
OpenTyphoon API
Collection
OpenTyphoon-API consists of Typhoon models that were previously served in opentyphoon.ai
•
10 items
•
Updated
•
1
|
|
|
Typhoon ASR Real-Time is a next-generation, open-source Automatic Speech Recognition (ASR) model built specifically for real-world streaming applications in the Thai language. It is designed to deliver fast and accurate transcriptions while running efficiently on standard CPUs. This enables users to host their own ASR service, reducing costs and avoiding the need to send sensitive data to third-party cloud services. The model is trained on 10,000 hours of Thai audio transcriptions to help it generalize to any environments.
The model is based on NVIDIA's FastConformer Transducer model, which is optimized for low-latency, real-time performance.
Try our demo available on Demo
Code / Examples available on Github
Release Blog available on OpenTyphoon Blog
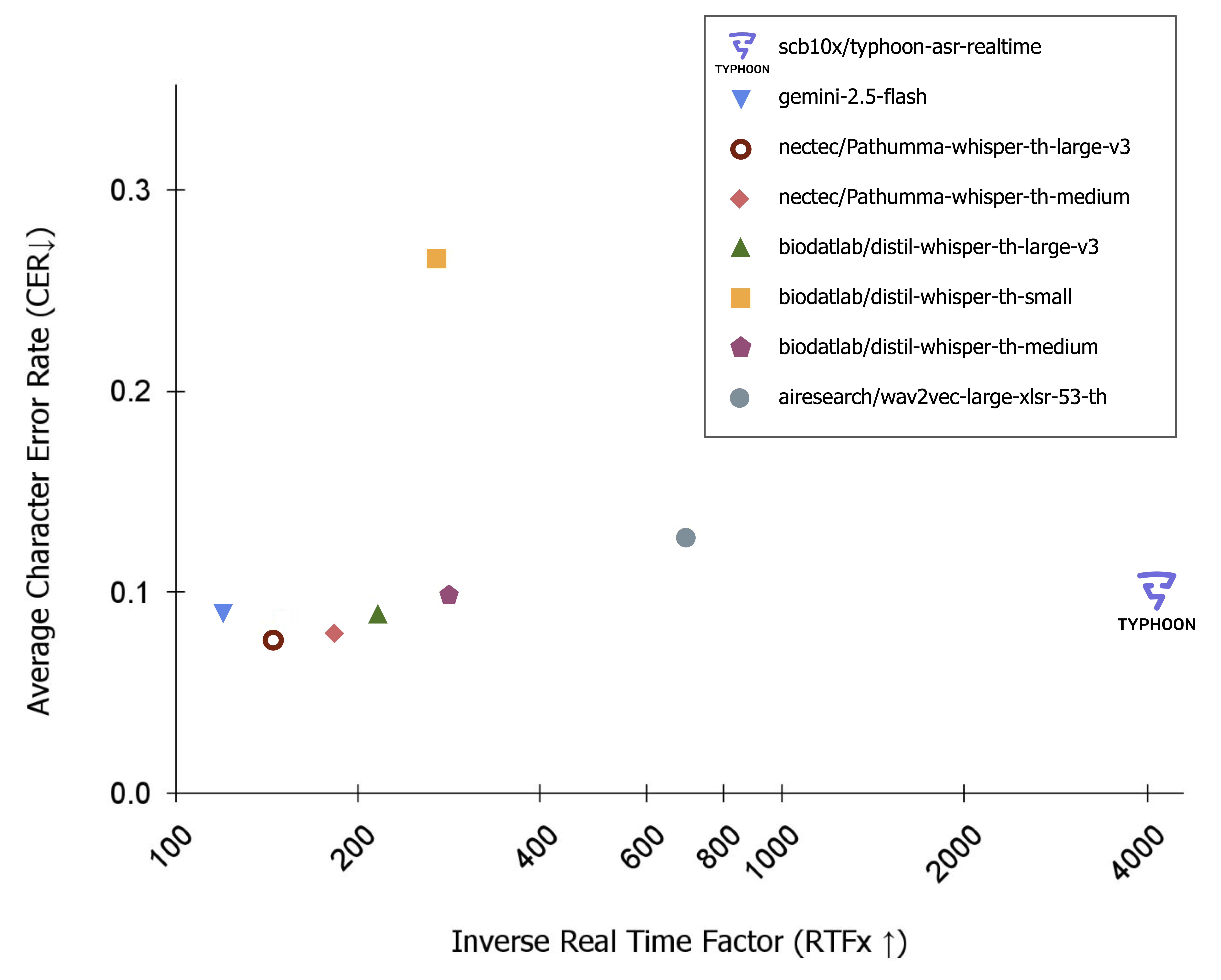
Typhoon ASR Realtime achieves 4097x real-time processing speed with competitive accuracy (CER: 0.0984), representing a 6x throughput improvement over the next fastest model. RTFx values are from the Open ASR Leaderboard on Hugging Face. The model outperforms Whisper variants by 15-19x in throughput while maintaining comparable accuracy, making it ideal for production Thai speech recognition requiring real-time performance and high-volume processing scenarios.
(Recommended): Quick Start with Google Colab
For a hands-on demonstration without any local setup, you can run this project directly in Google Colab. The notebook provides a complete environment to transcribe audio files and experiment with the model.
![]()
(Recommended): Using the typhoon-asr Package
This is the easiest way to get started. You can install the package via pip and use it directly from the command line or within your Python code.
1. Install the package:
pip install typhoon-asr
2. Command-Line Usage:
# Basic transcription (auto-detects device)
typhoon-asr path/to/your_audio.wav
# Transcription with timestamps on a specific device
typhoon-asr path/to/your_audio.mp3 --with-timestamps --device cuda
3. Python API Usage:
from typhoon_asr import transcribe
# Basic transcription
result = transcribe("path/to/your_audio.wav")
print(result['text'])
# Transcription with timestamps
result_with_timestamps = transcribe("path/to/your_audio.wav", with_timestamps=True)
print(result_with_timestamps)
(Alternative): Running from the Repository Script
You can also run the model by cloning the repository and using the inference script directly. This method is useful for development or if you need to modify the underlying code.
1. Clone the repository and install dependencies:
git clone https://github.com/scb10x/typhoon-asr.git
cd typhoon-asr
pip install -r requirements.txt
2. Run the inference script:
The typhoon_asr_inference.py script handles audio resampling and processing automatically.
# Basic Transcription (CPU):
python typhoon_asr_inference.py path/to/your_audio.m4a
# Transcription with Estimated Timestamps:
python typhoon_asr_inference.py path/to/your_audio.wav --with-timestamps
# Transcription on a GPU:
python typhoon_asr_inference.py path/to/your_audio.mp3 --device cuda
https://twitter.com/opentyphoon
Base model
nvidia/stt_en_fastconformer_transducer_large