
gravit
Collection
149 items
•
Updated
🔭 This model is part of GraViT: Transfer Learning with Vision Transformers and MLP-Mixer for Strong Gravitational Lens Discovery
🔗 GitHub Repository: https://github.com/parlange/gravit
import torch
import timm
# Load the model directly from the Hub
model = timm.create_model(
'hf-hub:parlange/twins_svt-gravit-b3',
pretrained=True
)
model.eval()
# Example inference
dummy_input = torch.randn(1, 3, 224, 224)
with torch.no_grad():
output = model(dummy_input)
predictions = torch.softmax(output, dim=1)
print(f"Lens probability: {predictions[0][1]:.4f}")
Training Dataset: J24 (Jaelani et al. 2024)
Fine-tuning Strategy: all-blocks
| 🔧 Parameter | 📝 Value |
|---|---|
| Batch Size | 192 |
| Learning Rate | AdamW with ReduceLROnPlateau |
| Epochs | 100 |
| Patience | 10 |
| Optimizer | AdamW |
| Scheduler | ReduceLROnPlateau |
| Image Size | 224x224 |
| Fine Tune Mode | all_blocks |
| Stochastic Depth Probability | 0.1 |

| Metric | Training | Validation |
|---|---|---|
| 📉 Loss | 0.0143 | 0.0596 |
| 🎯 Accuracy | 0.9949 | 0.9871 |
| 📊 AUC-ROC | 0.9998 | 0.9980 |
| ⚖️ F1 Score | 0.9949 | 0.9871 |
Performance across all test datasets (a through l) in the Common Test Sample (More et al. 2024):

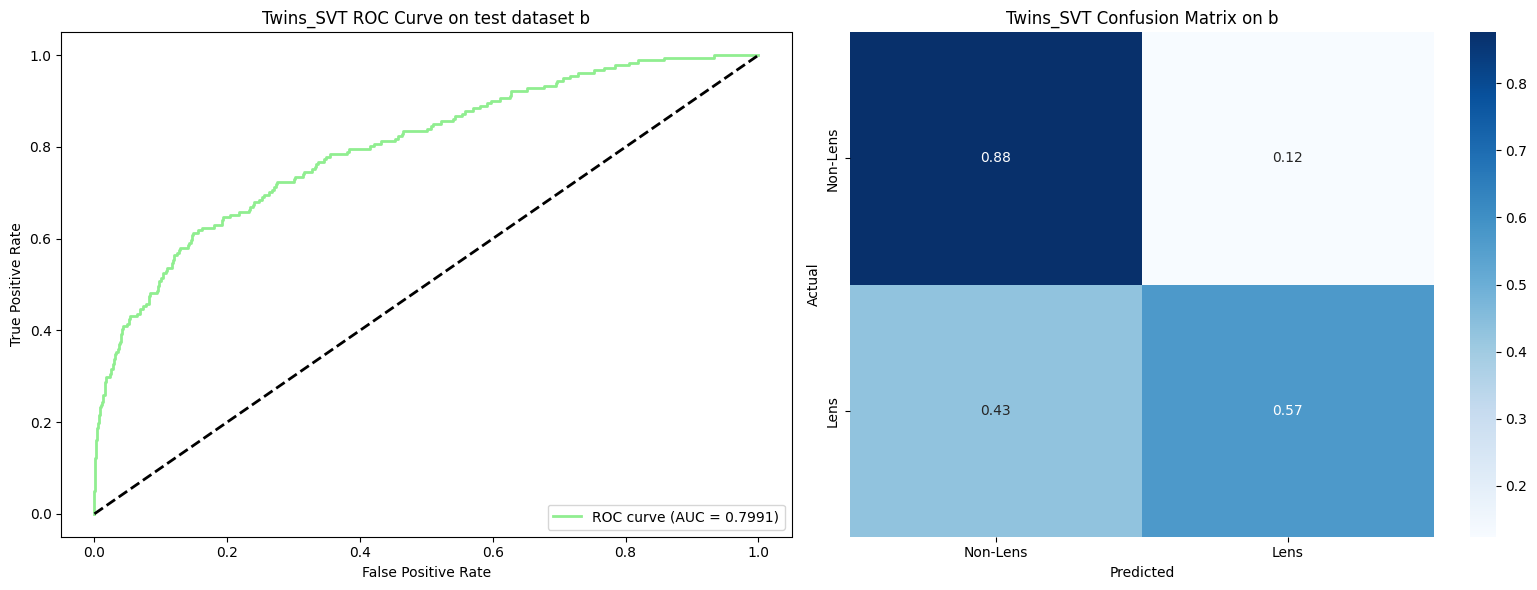

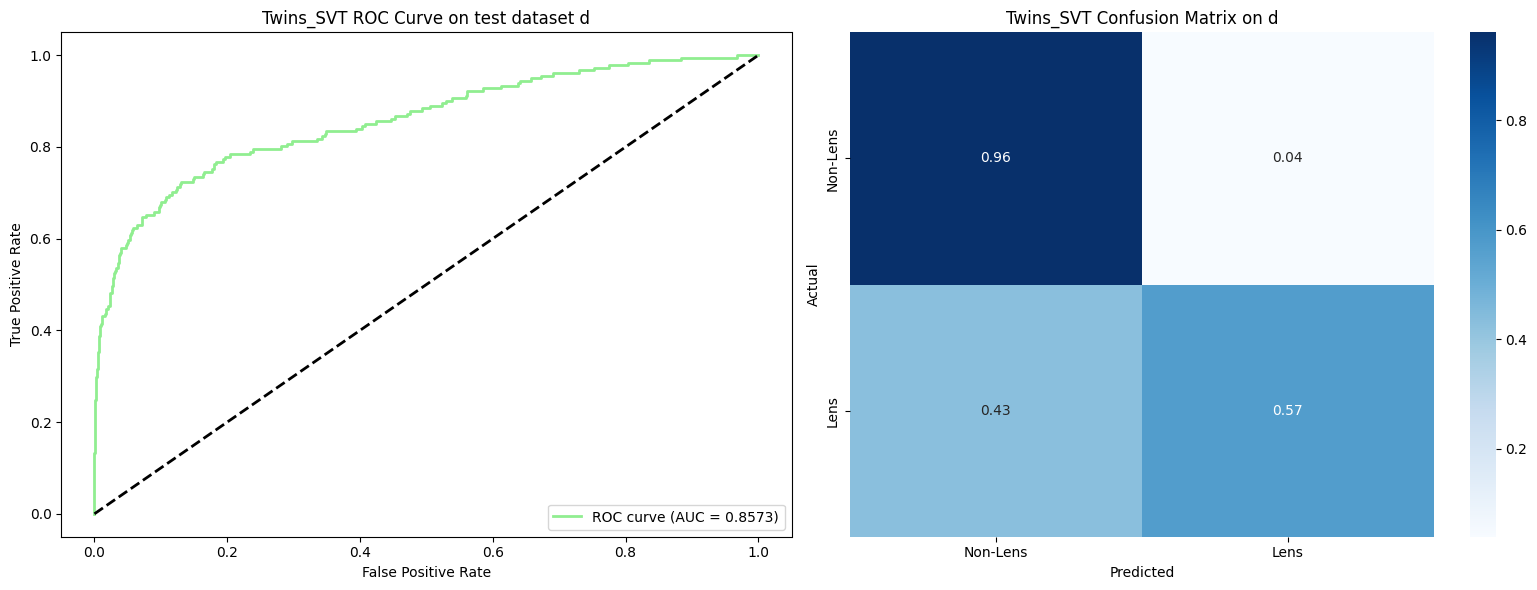



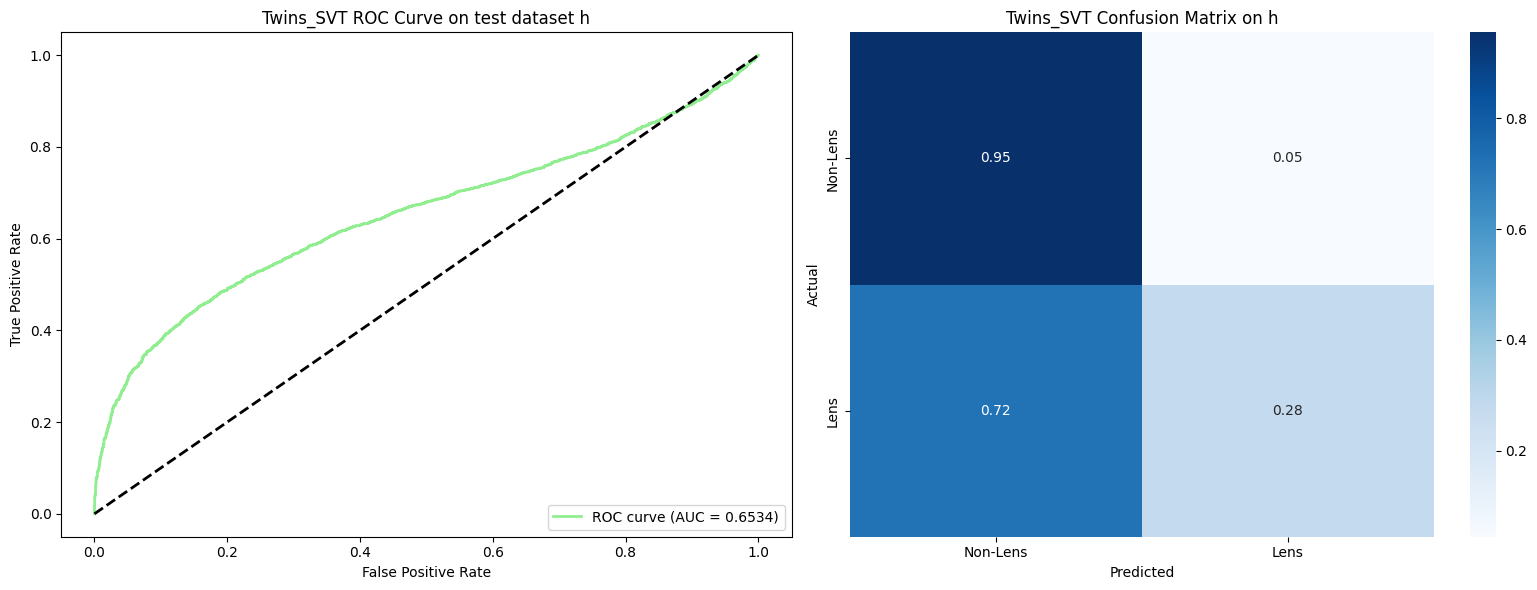

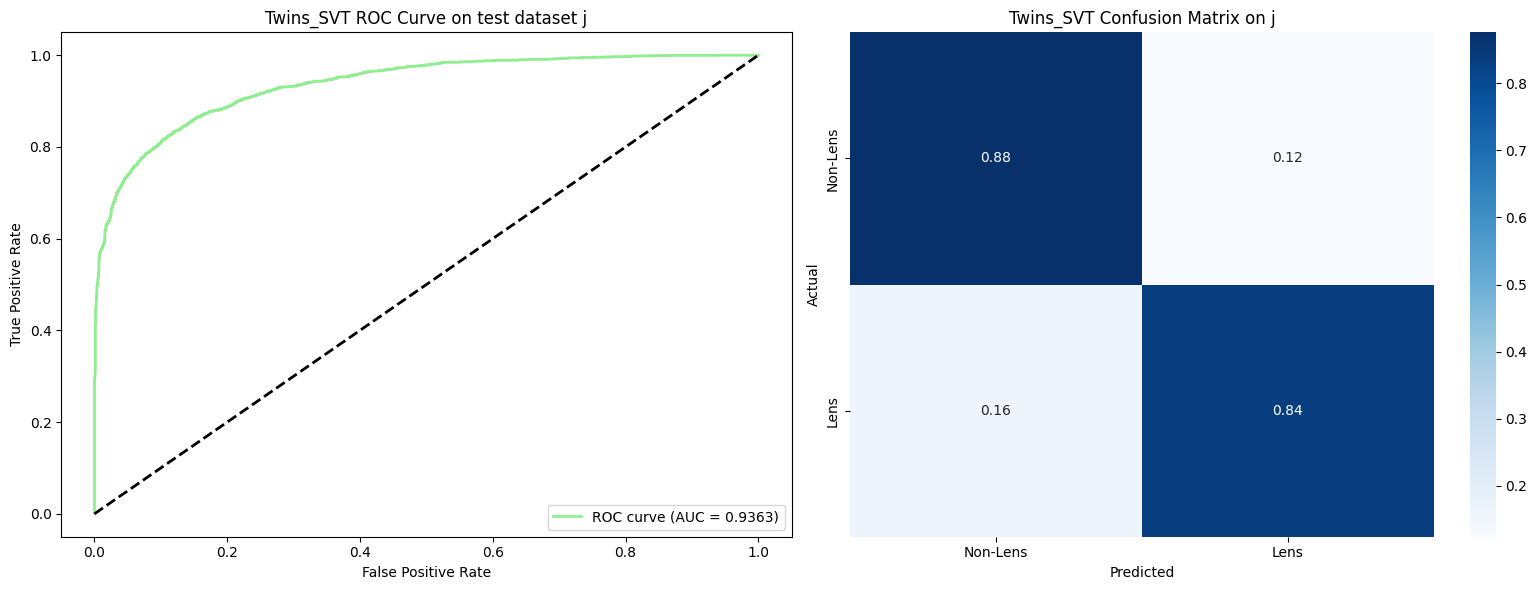
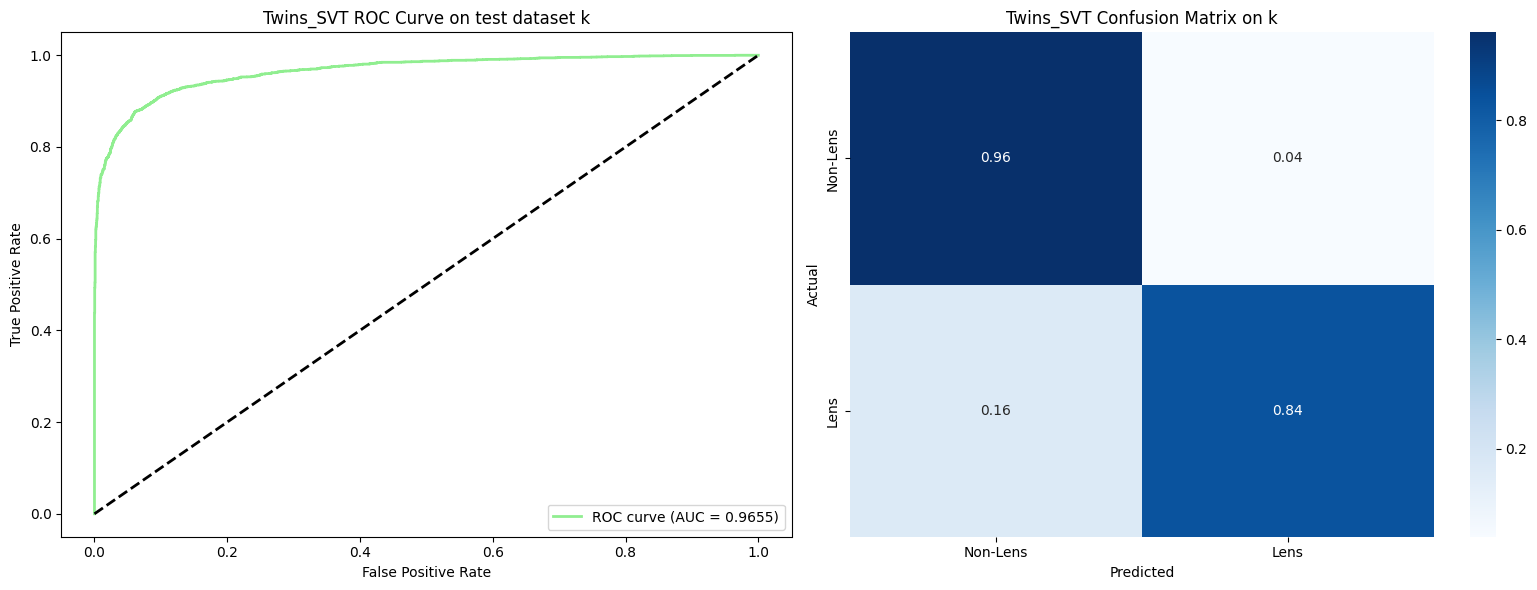

Average performance across 12 test datasets from the Common Test Sample (More et al. 2024):
| Metric | Value |
|---|---|
| 🎯 Average Accuracy | 0.8178 |
| 📈 Average AUC-ROC | 0.8050 |
| ⚖️ Average F1-Score | 0.5157 |
If you use this model in your research, please cite:
@misc{parlange2025gravit,
title={GraViT: Transfer Learning with Vision Transformers and MLP-Mixer for Strong Gravitational Lens Discovery},
author={René Parlange and Juan C. Cuevas-Tello and Octavio Valenzuela and Omar de J. Cabrera-Rosas and Tomás Verdugo and Anupreeta More and Anton T. Jaelani},
year={2025},
eprint={2509.00226},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.00226},
}
For questions about this model, please contact the author through: https://github.com/parlange/