Inference Endpoints (dedicated) documentation
SGLang
SGLang
SGLang is a fast serving framework for large language models and vision language models. It’s very similar to TGI and vLLM and comes with production ready features.
The core features include:
Fast Backend Runtime:
- efficient serving with RadixAttention for prefix caching
- zero-overhead CPU scheduler
- continuous batching, paged attention, tensor parallelism and pipeline parallelism,
- expert parallelism, structured outputs, chunked prefill, quantization (FP8/INT4/AWQ/GPTQ), and multi-lora batching
Extensive Model Support: Supports a wide range of generative models (Llama, Gemma, Mistral, Qwen, DeepSeek, LLaVA, etc.), embedding models (e5-mistral, gte, mcdse) and reward models (Skywork), with easy extensibility for integrating new models.
Configuration
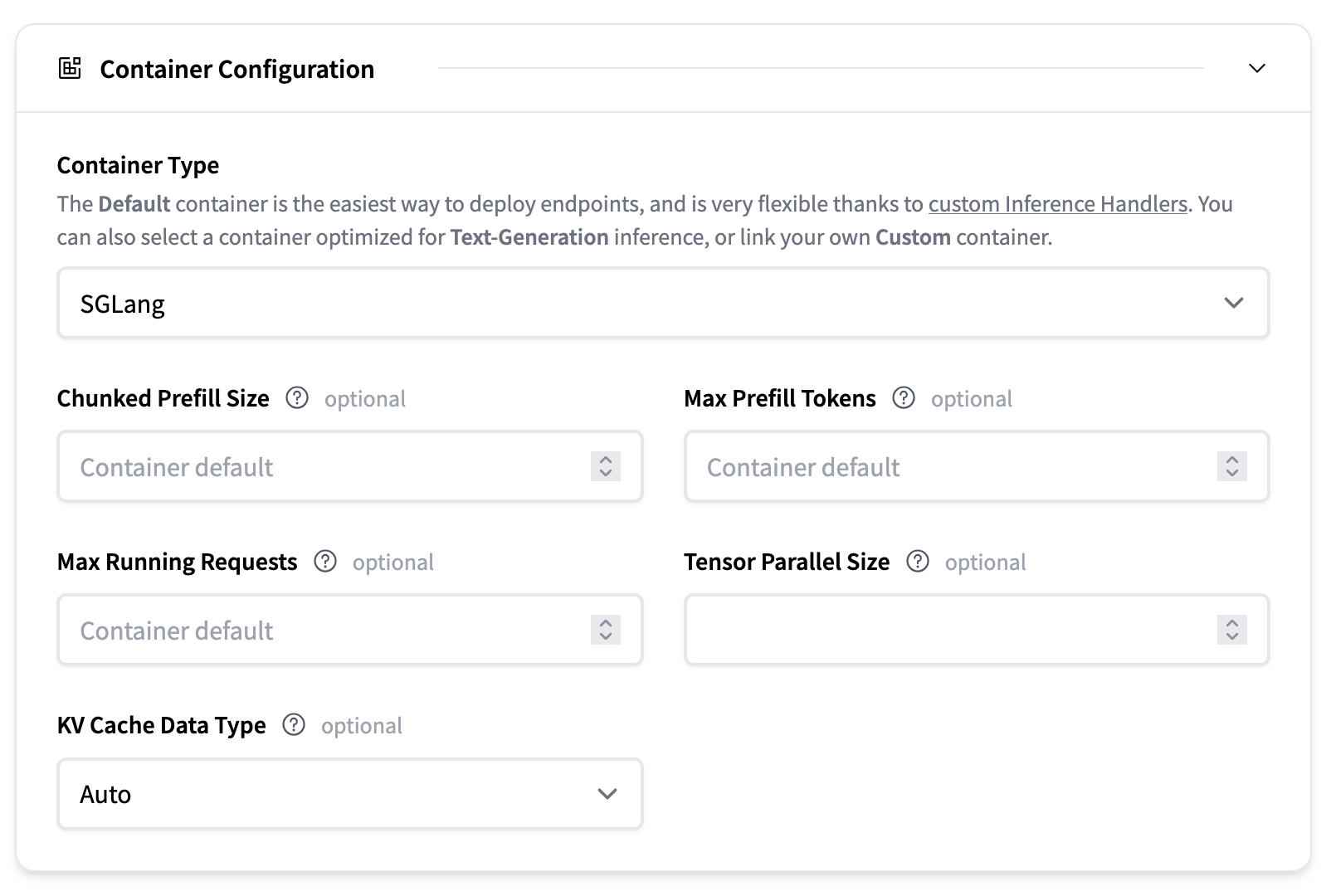
- Max Running Request: the max number of concurrent requests
- Max Prefill Tokens (per batch): the maximum number of tokens that can be processed in a single prefill operation. This controls the batch size for the prefill phase and helps manage memory usage during prompt processing.
- Chunked prefill size: sets how many tokens are processed at once during the prefill phase. If a prompt is longer than this value, it will be split into smaller chunks and processed sequentially to avoid out-of-memory errors during prefill with long prompts. For example, setting —chunked-prefill-size 4096 means each chunk will have up to 4096 tokens processed at a time. Setting this to -1 means disabling chunked prefill.
- Tensor Parallel Size: the number of GPUs to use for tensor parallelism. This enables model sharding across multiple GPUs to handle larger models that don’t fit on a single GPU. For example, setting this to 2 will split the model across 2 GPUs.
- KV Cache DType: the data type used for storing the key-value cache during generation. Options include “auto”, “fp8_e5m2”, and “fp8_e4m3”. Using lower precision types can reduce memory usage but may slightly impact generation quality.
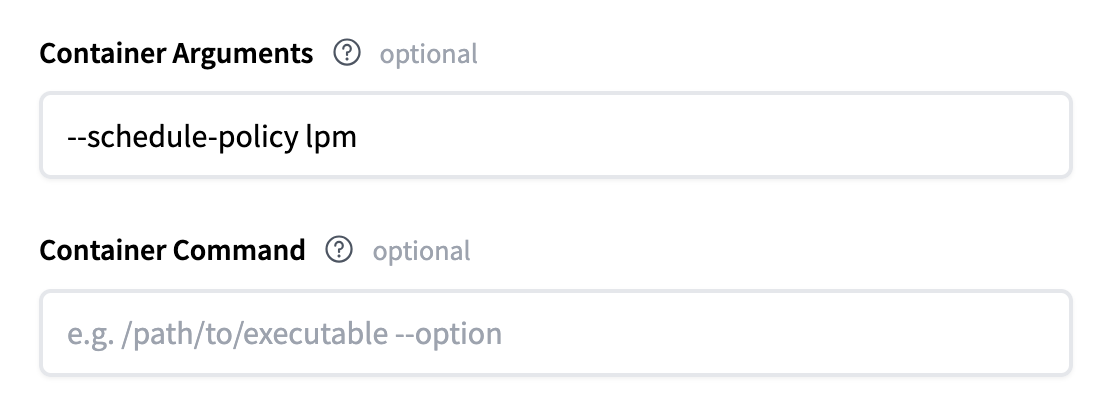
For more advanced configuration you can pass any of the Server Arguments that SGlang supports
as container arguments. For example changing the schedule-policy to lpm would look like this:
Supported models
SGlang has wide support for large language models, multimodal language models, embedding models and more. We recommend reading the supported models section in the SGLang documentation for a full list.
In the Inference Endpoints UI, by default, any model on the Hugging Face Hub that has a transformers tag, can be deployed with SGLang.
This is because SGLang implements a fallback to use transformers
if SGLang doesn’t have their own implementation of a model.
References
We also recommend reading the SGLang documentation for more in-depth information.
< > Update on GitHub