
Holo1.5
Collection
Holo1.5 - Open Foundation Models for Computer Use Agents
•
5 items
•
Updated
•
30
Computer Use (CU) agents are AI systems that can interact with real applications—web, desktop, and mobile—on behalf of a user. They can navigate interfaces, manipulate elements, and answer questions about content, enabling powerful automation and productivity tools. CU agents are becoming increasingly important as they allow humans to delegate complex digital tasks safely and efficiently.
Our Holo1.5 series provides state-of-the-art foundational models for building such agents. Holo1.5 models excel at user interface (UI) localization and UI-based question answering (QA) across web, computer, and mobile environments, with strong performance on benchmarks including Screenspot-V2, Screenspot-Pro, GroundUI-Web, Showdown, and our newly introduced WebClick.
The Holo1.5 family comes in three model sizes to fit different deployment needs:
These models are designed to provide reliable, accurate, and efficient foundations for next-generation CU agents, like Surfer-H, enabling them to manipulate real applications with unprecedented capability.
Our models are trained using high-quality proprietary data for UI understanding and action prediction, following a multi-stage training pipeline. The training dataset is a carefully curated mix of open-source datasets, large-scale synthetic data, and human-annotated samples.
Training proceeds in two stages: large-scale supervised fine-tuning, followed by online reinforcement learning (GRPO). The resulting Holo1.5 models are natively high-resolution (up to 3840 × 2160 pixels), capable of interpreting UIs and performing actions on large, complex screens with accuracy and efficiency.
UI Localization refers to an agent’s ability to find the exact positions of elements on a user interface (buttons, text boxes, images, etc.). This capability is essential for Computer Use (CU) agents because, to interact with an application—click a button, fill out a form, or read information—the agent must know where elements are located on the screen.
Our Holo1.5 models were evaluated on several standard UI localization benchmarks (Screenspot-V2, Screenspot-Pro, GroundUI-Web, Showdown, and our newly introduced WebClick) to measure how accurately they can predict these coordinates.
The results:
These results establish a new Pareto frontier in open-source UI localization: the best trade-off yet between model size and localization accuracy, setting a new standard for CU agents.
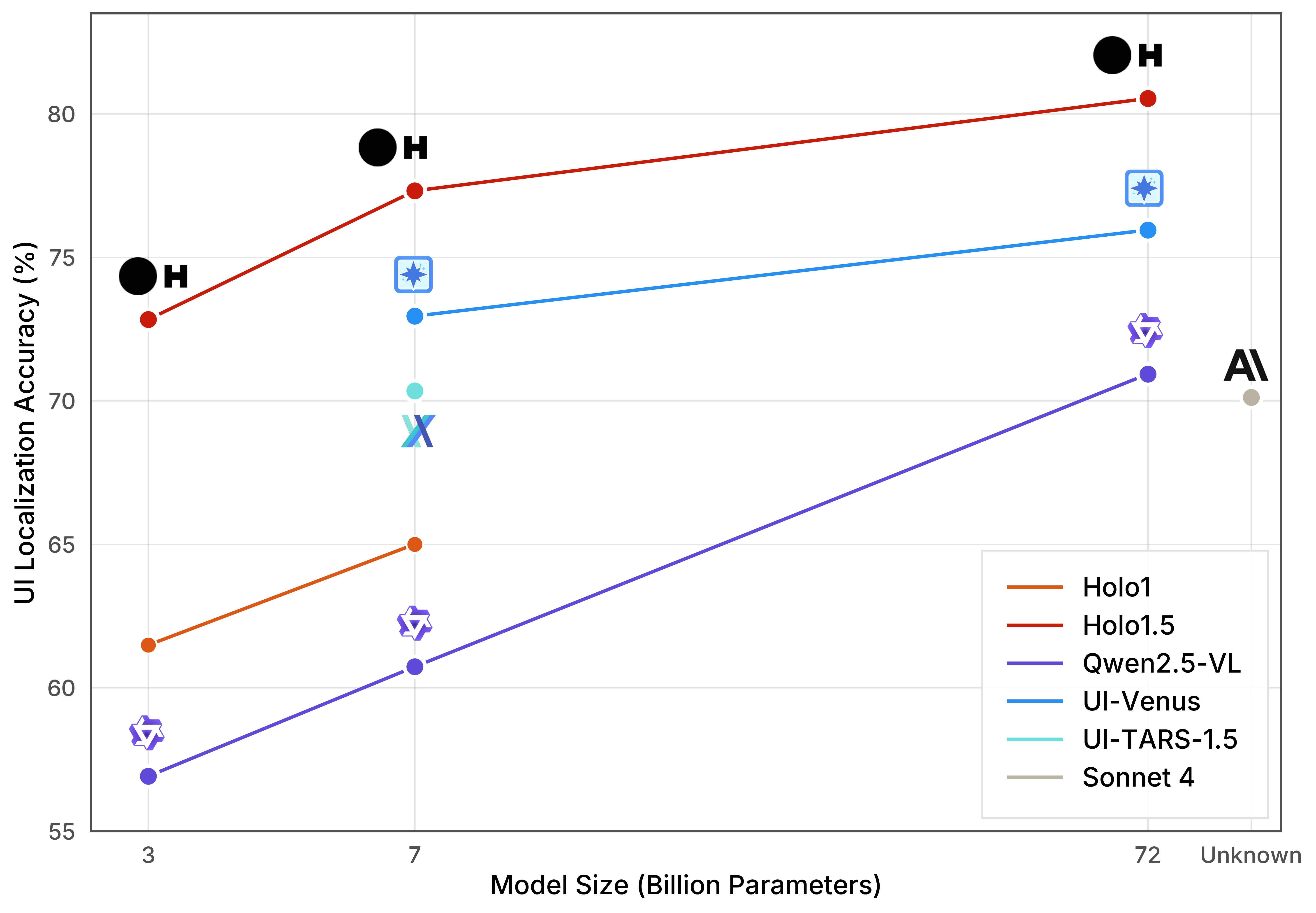 Pareto frontier of UI Localization accuracy versus Model size
Pareto frontier of UI Localization accuracy versus Model size
 Accuracy of our and competitors' models on UI Localization benchmarks.
Accuracy of our and competitors' models on UI Localization benchmarks.
| WebClick | Showdown | ScreenSpot-v2 | ScreenSpot-Pro | Ground-UI-1K | OSWorld-G | Average | |
|---|---|---|---|---|---|---|---|
| Holo1.5-3B | 81.45 | 67.50 | 91.66 | 51.49 | 83.20 | 61.57 | 72.81 |
| Holo1.5-7B | 90.24 | 72.17 | 93.31 | 57.94 | 84.00 | 66.27 | 77.32 |
| Holo1.5-72B | 92.43 | 76.84 | 94.41 | 63.25 | 84.50 | 71.80 | 80.54 |
| Qwen2.5-VL-3B | 71.20 | 50.30 | 80.00 | 29.30 | 76.40 | 34.31 | 56.92 |
| Qwen2.5-VL-7B | 76.51 | 52.00 | 85.60 | 29.00 | 80.70 | 40.59 | 60.73 |
| Qwen2.5-VL-72B | 88.29 | 41.00 | 93.30 | 55.60 | 85.40 | 61.96 | 70.93 |
| UI-TARS-1.5-7B | 86.10 | 58.00 | 94.00 | 39.00 | 84.20 | 61.40 | 70.45 |
| Holo1-7B | 84.04 | 64.27 | 89.85 | 26.06 | 78.50 | 47.25 | 65.00 |
| Holo1-3B | 79.35 | 59.96 | 88.91 | 23.66 | 74.75 | 42.16 | 61.47 |
| UI-Venus-7B | 84.44 | 67.32 | 94.10 | 50.80 | 82.30 | 58.80 | 72.96 |
| UI-Venus-72B | 77.00 | 75.58 | 95.30 | 61.90 | 75.50 | 70.40 | 75.95 |
| Sonnet 4 | 93.00 | 72.00 | 93.00 | 19.10 | 84.00 | 59.60 | 70.12 |
Table 1: Localization benchmark scores for leading models. Bold values show state-of-the-art performance, scores in italic were obtained from previously reported sources and scores in non-italic were reproduced in-house
While precise localization is essential for GUI agents, it is equally important for models to comprehend the structure and functionality of user interfaces to interact with them effectively. To evaluate these capabilities, we tested our Holo1.5 models on several GUI-focused question answering (QA) benchmarks, including ScreenQA Short, ScreenQA Complex, VisualWebBench, and WebSRC. These benchmarks measure the models’ ability to understand and reason about UIs, ensuring they can perform tasks accurately across diverse applications.
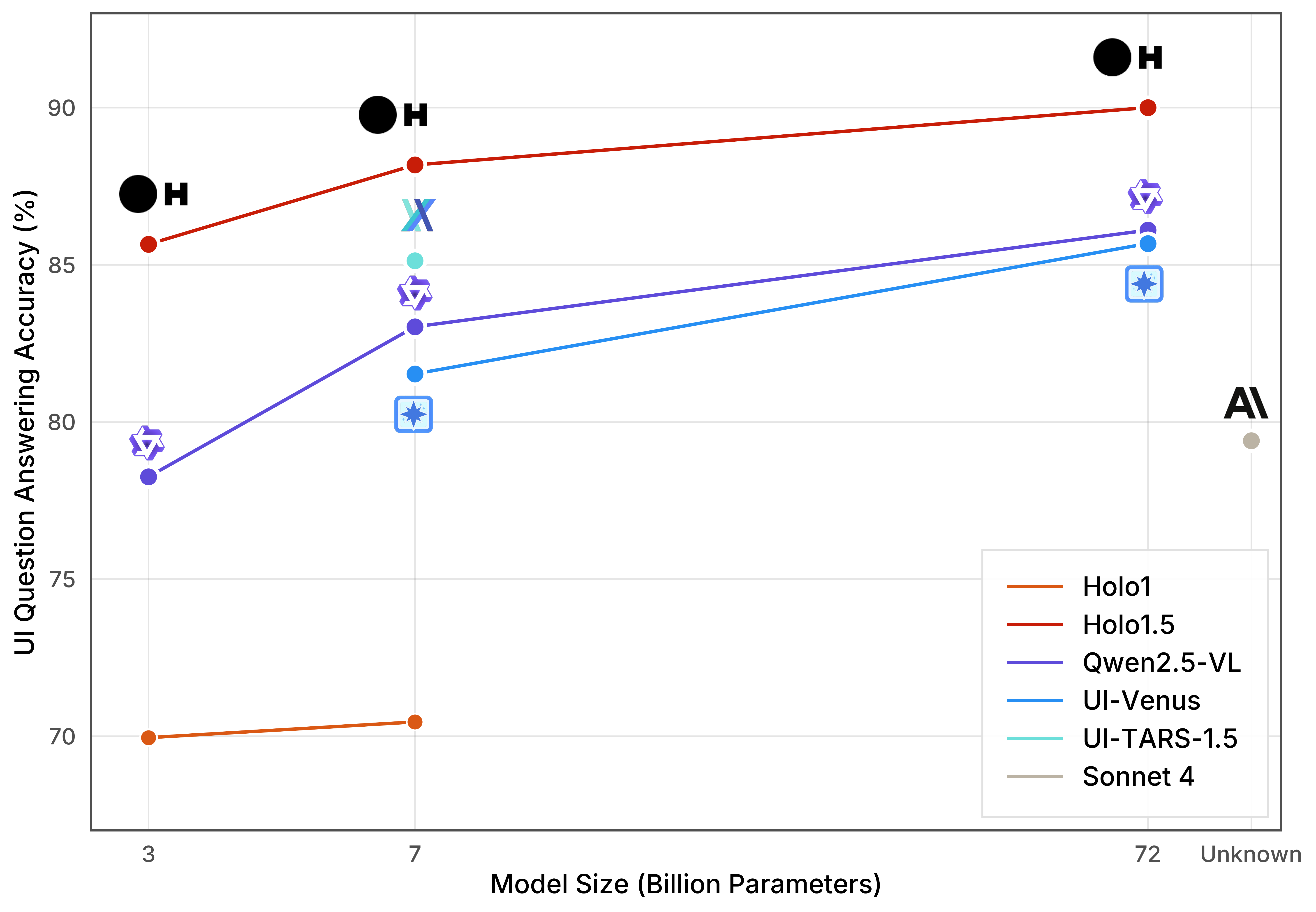 Pareto Frontier of UI Question Answering Performance versus Model size
Pareto Frontier of UI Question Answering Performance versus Model size
 UI Understanding and Visual Question Answering performance
UI Understanding and Visual Question Answering performance
| VisualWebBench | WebSRC | ScreenQAShort | ScreenQAComplex | Average | |
|---|---|---|---|---|---|
| Holo1.5-3B | 78.50 | 94.80 | 87.90 | 81.40 | 85.65 |
| Holo1.5-7B | 82.60 | 95.90 | 91.00 | 83.20 | 88.17 |
| Holo1.5-72B | 83.80 | 97.20 | 91.90 | 87.10 | 90.00 |
| Qwen2.5-VL-3B | 58.00 | 93.00 | 86.00 | 76.00 | 78.25 |
| Qwen2.5-VL-7B | 69.00 | 95.00 | 87.00 | 81.10 | 83.02 |
| Qwen2.5-VL-72B | 76.30 | 97.00 | 87.90 | 83.20 | 86.10 |
| UI-TARS-1.5-7B | 79.70 | 92.90 | 88.70 | 79.20 | 85.12 |
| Holo1-3B | 54.10 | 93.90 | 78.30 | 53.50 | 69.95 |
| Holo1-7B | 38.10 | 95.30 | 83.30 | 65.10 | 70.45 |
| UI-Venus-7B | 60.90 | 96.60 | 86.30 | 82.30 | 81.52 |
| UI-Venus-72B | 74.10 | 96.70 | 88.60 | 83.30 | 85.67 |
| Claude-Sonnet-4 | 58.90 | 96.00 | 87.00 | 75.70 | 79.40 |
Table 2: Screen content QA benchmark scores for leading models. Bold values show state-of-the-art performance
Holo1.5 models show impressive capabilities in GUI QA tasks by improving on state-of-the-art models by 3.9%. This demonstrates strong visual perception capabilities in web and desktop environments, which is crucial for computer-use agents
Watch a demo of how to prompt the model in a computer use setting:
The demo is also live on our Hugging Face Space.
Our goal is to build cost-efficient and reliable computer use agents. With the release of Holo1.5, we take an important step toward fostering trust and adoption of this technology.
This milestone is only the beginning—over the coming weeks, we will be unveiling new tools and agents powered by Holo models.
Stay tuned—we’re just getting started!
@misc{hai2025holo15modelfamily,
title={Holo1.5 - Open Foundation Models for Computer Use Agents},
author={H Company},
year={2025},
url={https://huggingface.co/collections/Hcompany/holo15-68c1a5736e8583a309d23d9b},
}