Spaces:
Running

Running
Commit
·
755ac75
0
Parent(s):
almost working
Browse files- .gitignore +2 -0
- alarm-states.ipynb +513 -0
- concattedfiles.py +381 -0
- cw-alarm-creation-form.png +0 -0
- cw-alarm-missing-data-treatment.png +0 -0
- requirements.txt +6 -0
- streamlit_app.py +225 -0
- utils.py +140 -0
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# nothing
|
| 2 |
+
*env
|
alarm-states.ipynb
ADDED
|
@@ -0,0 +1,513 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [
|
| 8 |
+
{
|
| 9 |
+
"data": {
|
| 10 |
+
"text/html": [
|
| 11 |
+
"<div>\n",
|
| 12 |
+
"<style scoped>\n",
|
| 13 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 14 |
+
" vertical-align: middle;\n",
|
| 15 |
+
" }\n",
|
| 16 |
+
"\n",
|
| 17 |
+
" .dataframe tbody tr th {\n",
|
| 18 |
+
" vertical-align: top;\n",
|
| 19 |
+
" }\n",
|
| 20 |
+
"\n",
|
| 21 |
+
" .dataframe thead th {\n",
|
| 22 |
+
" text-align: right;\n",
|
| 23 |
+
" }\n",
|
| 24 |
+
"</style>\n",
|
| 25 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 26 |
+
" <thead>\n",
|
| 27 |
+
" <tr style=\"text-align: right;\">\n",
|
| 28 |
+
" <th></th>\n",
|
| 29 |
+
" <th>Timestamp</th>\n",
|
| 30 |
+
" <th>ResponseTime(ms)</th>\n",
|
| 31 |
+
" </tr>\n",
|
| 32 |
+
" </thead>\n",
|
| 33 |
+
" <tbody>\n",
|
| 34 |
+
" <tr>\n",
|
| 35 |
+
" <th>0</th>\n",
|
| 36 |
+
" <td>2024-07-26 12:00:12</td>\n",
|
| 37 |
+
" <td>169.0</td>\n",
|
| 38 |
+
" </tr>\n",
|
| 39 |
+
" <tr>\n",
|
| 40 |
+
" <th>1</th>\n",
|
| 41 |
+
" <td>2024-07-26 12:00:27</td>\n",
|
| 42 |
+
" <td>NaN</td>\n",
|
| 43 |
+
" </tr>\n",
|
| 44 |
+
" <tr>\n",
|
| 45 |
+
" <th>2</th>\n",
|
| 46 |
+
" <td>2024-07-26 12:00:42</td>\n",
|
| 47 |
+
" <td>NaN</td>\n",
|
| 48 |
+
" </tr>\n",
|
| 49 |
+
" <tr>\n",
|
| 50 |
+
" <th>3</th>\n",
|
| 51 |
+
" <td>2024-07-26 12:00:57</td>\n",
|
| 52 |
+
" <td>146.0</td>\n",
|
| 53 |
+
" </tr>\n",
|
| 54 |
+
" <tr>\n",
|
| 55 |
+
" <th>4</th>\n",
|
| 56 |
+
" <td>2024-07-26 12:01:30</td>\n",
|
| 57 |
+
" <td>202.0</td>\n",
|
| 58 |
+
" </tr>\n",
|
| 59 |
+
" </tbody>\n",
|
| 60 |
+
"</table>\n",
|
| 61 |
+
"</div>"
|
| 62 |
+
],
|
| 63 |
+
"text/plain": [
|
| 64 |
+
" Timestamp ResponseTime(ms)\n",
|
| 65 |
+
"0 2024-07-26 12:00:12 169.0\n",
|
| 66 |
+
"1 2024-07-26 12:00:27 NaN\n",
|
| 67 |
+
"2 2024-07-26 12:00:42 NaN\n",
|
| 68 |
+
"3 2024-07-26 12:00:57 146.0\n",
|
| 69 |
+
"4 2024-07-26 12:01:30 202.0"
|
| 70 |
+
]
|
| 71 |
+
},
|
| 72 |
+
"execution_count": 1,
|
| 73 |
+
"metadata": {},
|
| 74 |
+
"output_type": "execute_result"
|
| 75 |
+
}
|
| 76 |
+
],
|
| 77 |
+
"source": [
|
| 78 |
+
"import random\n",
|
| 79 |
+
"from datetime import datetime, timedelta\n",
|
| 80 |
+
"import pandas as pd\n",
|
| 81 |
+
"import numpy as np\n",
|
| 82 |
+
"\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"# Function to generate random timestamps and response times\n",
|
| 85 |
+
"def generate_random_data(date, start_time, end_time, count, response_time_range, null_percentage):\n",
|
| 86 |
+
" # Combine date with start and end times\n",
|
| 87 |
+
" start_datetime = datetime.combine(date, start_time)\n",
|
| 88 |
+
" end_datetime = datetime.combine(date, end_time)\n",
|
| 89 |
+
" \n",
|
| 90 |
+
" # Generate random timestamps\n",
|
| 91 |
+
" random_timestamps = [\n",
|
| 92 |
+
" start_datetime + timedelta(seconds=random.randint(0, int((end_datetime - start_datetime).total_seconds())))\n",
|
| 93 |
+
" for _ in range(count)\n",
|
| 94 |
+
" ]\n",
|
| 95 |
+
" \n",
|
| 96 |
+
" # Sort the timestamps\n",
|
| 97 |
+
" random_timestamps.sort()\n",
|
| 98 |
+
" \n",
|
| 99 |
+
" # Generate random response times\n",
|
| 100 |
+
" random_response_times = [\n",
|
| 101 |
+
" random.randint(response_time_range[0], response_time_range[1]) for _ in range(count)\n",
|
| 102 |
+
" ]\n",
|
| 103 |
+
" \n",
|
| 104 |
+
" # Introduce null values in response times\n",
|
| 105 |
+
" null_count = int(null_percentage * count)\n",
|
| 106 |
+
" null_indices = random.sample(range(count), null_count)\n",
|
| 107 |
+
" for idx in null_indices:\n",
|
| 108 |
+
" random_response_times[idx] = None\n",
|
| 109 |
+
" \n",
|
| 110 |
+
" # Create a pandas DataFrame\n",
|
| 111 |
+
" data = {\n",
|
| 112 |
+
" 'Timestamp': random_timestamps,\n",
|
| 113 |
+
" 'ResponseTime(ms)': random_response_times\n",
|
| 114 |
+
" }\n",
|
| 115 |
+
" df = pd.DataFrame(data)\n",
|
| 116 |
+
" return df\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"# Parameters\n",
|
| 119 |
+
"date = datetime.strptime('2024-07-26', '%Y-%m-%d').date()\n",
|
| 120 |
+
"start_time = datetime.strptime('12:00:00', '%H:%M:%S').time()\n",
|
| 121 |
+
"end_time = datetime.strptime('12:30:00', '%H:%M:%S').time()\n",
|
| 122 |
+
"count = 60\n",
|
| 123 |
+
"response_time_range = (100, 250)\n",
|
| 124 |
+
"null_percentage = 0.50\n",
|
| 125 |
+
"\n",
|
| 126 |
+
"# Generate random data and get the DataFrame\n",
|
| 127 |
+
"df = generate_random_data(date, start_time, end_time, count, response_time_range, null_percentage)\n",
|
| 128 |
+
"df.head()\n"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": 109,
|
| 134 |
+
"metadata": {},
|
| 135 |
+
"outputs": [
|
| 136 |
+
{
|
| 137 |
+
"data": {
|
| 138 |
+
"text/html": [
|
| 139 |
+
"<div>\n",
|
| 140 |
+
"<style scoped>\n",
|
| 141 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 142 |
+
" vertical-align: middle;\n",
|
| 143 |
+
" }\n",
|
| 144 |
+
"\n",
|
| 145 |
+
" .dataframe tbody tr th {\n",
|
| 146 |
+
" vertical-align: top;\n",
|
| 147 |
+
" }\n",
|
| 148 |
+
"\n",
|
| 149 |
+
" .dataframe thead th {\n",
|
| 150 |
+
" text-align: right;\n",
|
| 151 |
+
" }\n",
|
| 152 |
+
"</style>\n",
|
| 153 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 154 |
+
" <thead>\n",
|
| 155 |
+
" <tr style=\"text-align: right;\">\n",
|
| 156 |
+
" <th></th>\n",
|
| 157 |
+
" <th>Timestamp</th>\n",
|
| 158 |
+
" <th>p95_ResponseTime(ms)</th>\n",
|
| 159 |
+
" </tr>\n",
|
| 160 |
+
" </thead>\n",
|
| 161 |
+
" <tbody>\n",
|
| 162 |
+
" <tr>\n",
|
| 163 |
+
" <th>0</th>\n",
|
| 164 |
+
" <td>2024-07-26 12:02:00</td>\n",
|
| 165 |
+
" <td>None</td>\n",
|
| 166 |
+
" </tr>\n",
|
| 167 |
+
" <tr>\n",
|
| 168 |
+
" <th>1</th>\n",
|
| 169 |
+
" <td>2024-07-26 12:03:00</td>\n",
|
| 170 |
+
" <td>None</td>\n",
|
| 171 |
+
" </tr>\n",
|
| 172 |
+
" <tr>\n",
|
| 173 |
+
" <th>2</th>\n",
|
| 174 |
+
" <td>2024-07-26 12:04:00</td>\n",
|
| 175 |
+
" <td>184.8</td>\n",
|
| 176 |
+
" </tr>\n",
|
| 177 |
+
" <tr>\n",
|
| 178 |
+
" <th>3</th>\n",
|
| 179 |
+
" <td>2024-07-26 12:05:00</td>\n",
|
| 180 |
+
" <td>None</td>\n",
|
| 181 |
+
" </tr>\n",
|
| 182 |
+
" <tr>\n",
|
| 183 |
+
" <th>4</th>\n",
|
| 184 |
+
" <td>2024-07-26 12:06:00</td>\n",
|
| 185 |
+
" <td>181.3</td>\n",
|
| 186 |
+
" </tr>\n",
|
| 187 |
+
" <tr>\n",
|
| 188 |
+
" <th>5</th>\n",
|
| 189 |
+
" <td>2024-07-26 12:07:00</td>\n",
|
| 190 |
+
" <td>223.0</td>\n",
|
| 191 |
+
" </tr>\n",
|
| 192 |
+
" <tr>\n",
|
| 193 |
+
" <th>6</th>\n",
|
| 194 |
+
" <td>2024-07-26 12:08:00</td>\n",
|
| 195 |
+
" <td>196.2</td>\n",
|
| 196 |
+
" </tr>\n",
|
| 197 |
+
" <tr>\n",
|
| 198 |
+
" <th>7</th>\n",
|
| 199 |
+
" <td>2024-07-26 12:09:00</td>\n",
|
| 200 |
+
" <td>151.0</td>\n",
|
| 201 |
+
" </tr>\n",
|
| 202 |
+
" <tr>\n",
|
| 203 |
+
" <th>8</th>\n",
|
| 204 |
+
" <td>2024-07-26 12:10:00</td>\n",
|
| 205 |
+
" <td>None</td>\n",
|
| 206 |
+
" </tr>\n",
|
| 207 |
+
" <tr>\n",
|
| 208 |
+
" <th>9</th>\n",
|
| 209 |
+
" <td>2024-07-26 12:11:00</td>\n",
|
| 210 |
+
" <td>227.45</td>\n",
|
| 211 |
+
" </tr>\n",
|
| 212 |
+
" </tbody>\n",
|
| 213 |
+
"</table>\n",
|
| 214 |
+
"</div>"
|
| 215 |
+
],
|
| 216 |
+
"text/plain": [
|
| 217 |
+
" Timestamp p95_ResponseTime(ms)\n",
|
| 218 |
+
"0 2024-07-26 12:02:00 None\n",
|
| 219 |
+
"1 2024-07-26 12:03:00 None\n",
|
| 220 |
+
"2 2024-07-26 12:04:00 184.8\n",
|
| 221 |
+
"3 2024-07-26 12:05:00 None\n",
|
| 222 |
+
"4 2024-07-26 12:06:00 181.3\n",
|
| 223 |
+
"5 2024-07-26 12:07:00 223.0\n",
|
| 224 |
+
"6 2024-07-26 12:08:00 196.2\n",
|
| 225 |
+
"7 2024-07-26 12:09:00 151.0\n",
|
| 226 |
+
"8 2024-07-26 12:10:00 None\n",
|
| 227 |
+
"9 2024-07-26 12:11:00 227.45"
|
| 228 |
+
]
|
| 229 |
+
},
|
| 230 |
+
"execution_count": 109,
|
| 231 |
+
"metadata": {},
|
| 232 |
+
"output_type": "execute_result"
|
| 233 |
+
}
|
| 234 |
+
],
|
| 235 |
+
"source": [
|
| 236 |
+
"# Function to calculate the specified percentile of response times over specified frequency\n",
|
| 237 |
+
"def calculate_percentile(df, freq, percentile):\n",
|
| 238 |
+
" \"\"\"\n",
|
| 239 |
+
" freq: Frequency for grouping the data (e.g., '1Min', '5Min', '1H')\n",
|
| 240 |
+
" percentile: Percentile value (e.g., 0.95, 0.99)\n",
|
| 241 |
+
" \"\"\"\n",
|
| 242 |
+
" percentile_df = df.groupby(pd.Grouper(key='Timestamp', freq=freq))[\"ResponseTime(ms)\"].quantile(percentile).reset_index(name=f\"p{int(percentile*100)}_ResponseTime(ms)\")\n",
|
| 243 |
+
" percentile_df.replace(to_replace=np.nan, value=None, inplace=True)\n",
|
| 244 |
+
" return percentile_df\n",
|
| 245 |
+
"\n",
|
| 246 |
+
"\n",
|
| 247 |
+
"\n",
|
| 248 |
+
"# df.groupby(pd.Grouper(key='Timestamp', freq='1Min'))[\"ResponseTime(ms)\"]\\\n",
|
| 249 |
+
"# .quantile(0.95).reset_index(name=\"p95_ResponseTime(ms)\")\n",
|
| 250 |
+
"\n",
|
| 251 |
+
"percentile_df = calculate_percentile(df, '1min', 0.95)\n",
|
| 252 |
+
"percentile_df.head(10)"
|
| 253 |
+
]
|
| 254 |
+
},
|
| 255 |
+
{
|
| 256 |
+
"cell_type": "code",
|
| 257 |
+
"execution_count": 82,
|
| 258 |
+
"metadata": {},
|
| 259 |
+
"outputs": [
|
| 260 |
+
{
|
| 261 |
+
"data": {
|
| 262 |
+
"text/plain": [
|
| 263 |
+
"array([229.8 , nan, 224. , nan, 234. , nan, 162.5 , nan,\n",
|
| 264 |
+
" 136. , nan, 205.35, nan, nan, 183. , 241. , 221.8 ,\n",
|
| 265 |
+
" nan, 116.4 , 174.65, 133.35, 176. , 127. , 209.85, 207. ,\n",
|
| 266 |
+
" 200. , 241.25, 217. , nan, 188.7 , 188. ])"
|
| 267 |
+
]
|
| 268 |
+
},
|
| 269 |
+
"execution_count": 82,
|
| 270 |
+
"metadata": {},
|
| 271 |
+
"output_type": "execute_result"
|
| 272 |
+
}
|
| 273 |
+
],
|
| 274 |
+
"source": [
|
| 275 |
+
"percentile_df[\"p95_ResponseTime(ms)\"].values"
|
| 276 |
+
]
|
| 277 |
+
},
|
| 278 |
+
{
|
| 279 |
+
"cell_type": "code",
|
| 280 |
+
"execution_count": 81,
|
| 281 |
+
"metadata": {},
|
| 282 |
+
"outputs": [],
|
| 283 |
+
"source": [
|
| 284 |
+
"def chunk_list(input_list, size=3):\n",
|
| 285 |
+
" while input_list:\n",
|
| 286 |
+
" chunk = input_list[:size]\n",
|
| 287 |
+
" yield chunk\n",
|
| 288 |
+
" input_list = input_list[size:]\n",
|
| 289 |
+
"\n",
|
| 290 |
+
"\n",
|
| 291 |
+
"# for chunk in chunk_list(list(percentile_df[\"p95_ResponseTime(ms)\"].values)):\n",
|
| 292 |
+
"# print(chunk)\n"
|
| 293 |
+
]
|
| 294 |
+
},
|
| 295 |
+
{
|
| 296 |
+
"cell_type": "code",
|
| 297 |
+
"execution_count": 72,
|
| 298 |
+
"metadata": {},
|
| 299 |
+
"outputs": [
|
| 300 |
+
{
|
| 301 |
+
"data": {
|
| 302 |
+
"text/plain": [
|
| 303 |
+
"3"
|
| 304 |
+
]
|
| 305 |
+
},
|
| 306 |
+
"execution_count": 72,
|
| 307 |
+
"metadata": {},
|
| 308 |
+
"output_type": "execute_result"
|
| 309 |
+
}
|
| 310 |
+
],
|
| 311 |
+
"source": [
|
| 312 |
+
"s_ = \"0-X-X\"\n",
|
| 313 |
+
"# len(s_) - s_.count(\"-\")"
|
| 314 |
+
]
|
| 315 |
+
},
|
| 316 |
+
{
|
| 317 |
+
"cell_type": "code",
|
| 318 |
+
"execution_count": 112,
|
| 319 |
+
"metadata": {},
|
| 320 |
+
"outputs": [
|
| 321 |
+
{
|
| 322 |
+
"data": {
|
| 323 |
+
"text/html": [
|
| 324 |
+
"<div>\n",
|
| 325 |
+
"<style scoped>\n",
|
| 326 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 327 |
+
" vertical-align: middle;\n",
|
| 328 |
+
" }\n",
|
| 329 |
+
"\n",
|
| 330 |
+
" .dataframe tbody tr th {\n",
|
| 331 |
+
" vertical-align: top;\n",
|
| 332 |
+
" }\n",
|
| 333 |
+
"\n",
|
| 334 |
+
" .dataframe thead th {\n",
|
| 335 |
+
" text-align: right;\n",
|
| 336 |
+
" }\n",
|
| 337 |
+
"</style>\n",
|
| 338 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 339 |
+
" <thead>\n",
|
| 340 |
+
" <tr style=\"text-align: right;\">\n",
|
| 341 |
+
" <th></th>\n",
|
| 342 |
+
" <th>DataPoints</th>\n",
|
| 343 |
+
" <th># of data points that must be filled</th>\n",
|
| 344 |
+
" <th>MISSING</th>\n",
|
| 345 |
+
" <th>IGNORE</th>\n",
|
| 346 |
+
" <th>BREACHING</th>\n",
|
| 347 |
+
" <th>NOT BREACHING</th>\n",
|
| 348 |
+
" </tr>\n",
|
| 349 |
+
" </thead>\n",
|
| 350 |
+
" <tbody>\n",
|
| 351 |
+
" <tr>\n",
|
| 352 |
+
" <th>0</th>\n",
|
| 353 |
+
" <td>--X-X</td>\n",
|
| 354 |
+
" <td>1</td>\n",
|
| 355 |
+
" <td></td>\n",
|
| 356 |
+
" <td></td>\n",
|
| 357 |
+
" <td></td>\n",
|
| 358 |
+
" <td></td>\n",
|
| 359 |
+
" </tr>\n",
|
| 360 |
+
" <tr>\n",
|
| 361 |
+
" <th>1</th>\n",
|
| 362 |
+
" <td>XXX-X</td>\n",
|
| 363 |
+
" <td>0</td>\n",
|
| 364 |
+
" <td></td>\n",
|
| 365 |
+
" <td></td>\n",
|
| 366 |
+
" <td></td>\n",
|
| 367 |
+
" <td></td>\n",
|
| 368 |
+
" </tr>\n",
|
| 369 |
+
" <tr>\n",
|
| 370 |
+
" <th>2</th>\n",
|
| 371 |
+
" <td>XX0--</td>\n",
|
| 372 |
+
" <td>0</td>\n",
|
| 373 |
+
" <td></td>\n",
|
| 374 |
+
" <td></td>\n",
|
| 375 |
+
" <td></td>\n",
|
| 376 |
+
" <td></td>\n",
|
| 377 |
+
" </tr>\n",
|
| 378 |
+
" <tr>\n",
|
| 379 |
+
" <th>3</th>\n",
|
| 380 |
+
" <td>XXXXX</td>\n",
|
| 381 |
+
" <td>0</td>\n",
|
| 382 |
+
" <td></td>\n",
|
| 383 |
+
" <td></td>\n",
|
| 384 |
+
" <td></td>\n",
|
| 385 |
+
" <td></td>\n",
|
| 386 |
+
" </tr>\n",
|
| 387 |
+
" <tr>\n",
|
| 388 |
+
" <th>4</th>\n",
|
| 389 |
+
" <td>X00-X</td>\n",
|
| 390 |
+
" <td>0</td>\n",
|
| 391 |
+
" <td></td>\n",
|
| 392 |
+
" <td></td>\n",
|
| 393 |
+
" <td></td>\n",
|
| 394 |
+
" <td></td>\n",
|
| 395 |
+
" </tr>\n",
|
| 396 |
+
" <tr>\n",
|
| 397 |
+
" <th>5</th>\n",
|
| 398 |
+
" <td>--X--</td>\n",
|
| 399 |
+
" <td>2</td>\n",
|
| 400 |
+
" <td></td>\n",
|
| 401 |
+
" <td></td>\n",
|
| 402 |
+
" <td></td>\n",
|
| 403 |
+
" <td></td>\n",
|
| 404 |
+
" </tr>\n",
|
| 405 |
+
" </tbody>\n",
|
| 406 |
+
"</table>\n",
|
| 407 |
+
"</div>"
|
| 408 |
+
],
|
| 409 |
+
"text/plain": [
|
| 410 |
+
" DataPoints # of data points that must be filled MISSING IGNORE BREACHING \\\n",
|
| 411 |
+
"0 --X-X 1 \n",
|
| 412 |
+
"1 XXX-X 0 \n",
|
| 413 |
+
"2 XX0-- 0 \n",
|
| 414 |
+
"3 XXXXX 0 \n",
|
| 415 |
+
"4 X00-X 0 \n",
|
| 416 |
+
"5 --X-- 2 \n",
|
| 417 |
+
"\n",
|
| 418 |
+
" NOT BREACHING \n",
|
| 419 |
+
"0 \n",
|
| 420 |
+
"1 \n",
|
| 421 |
+
"2 \n",
|
| 422 |
+
"3 \n",
|
| 423 |
+
"4 \n",
|
| 424 |
+
"5 "
|
| 425 |
+
]
|
| 426 |
+
},
|
| 427 |
+
"execution_count": 112,
|
| 428 |
+
"metadata": {},
|
| 429 |
+
"output_type": "execute_result"
|
| 430 |
+
}
|
| 431 |
+
],
|
| 432 |
+
"source": [
|
| 433 |
+
"def evaluate_alarm_state(percentile_df, percentile_value, threshold, datapoints_to_alarm, evaluation_range=5):\n",
|
| 434 |
+
" data_points = list(percentile_df[f\"p{int(percentile_value*100)}_ResponseTime(ms)\"].values)\n",
|
| 435 |
+
" \n",
|
| 436 |
+
" data_table_dict = {\n",
|
| 437 |
+
" \"DataPoints\": [],\n",
|
| 438 |
+
" \"# of data points that must be filled\": [],\n",
|
| 439 |
+
" \"MISSING\": [],\n",
|
| 440 |
+
" \"IGNORE\": [],\n",
|
| 441 |
+
" \"BREACHING\": [],\n",
|
| 442 |
+
" \"NOT BREACHING\": []\n",
|
| 443 |
+
" }\n",
|
| 444 |
+
" \n",
|
| 445 |
+
" for chunk in chunk_list(data_points, size=evaluation_range):\n",
|
| 446 |
+
" data_point_repr = ''\n",
|
| 447 |
+
" num_dp_that_must_be_filled = 0\n",
|
| 448 |
+
" # missing_state, ignore_state, breaching_state, not_breaching_state = None, None, None, None\n",
|
| 449 |
+
" for dp in chunk:\n",
|
| 450 |
+
" if dp is None:\n",
|
| 451 |
+
" data_point_repr += '-'\n",
|
| 452 |
+
" elif dp < threshold:\n",
|
| 453 |
+
" data_point_repr += '0'\n",
|
| 454 |
+
" else:\n",
|
| 455 |
+
" data_point_repr += 'X'\n",
|
| 456 |
+
" \n",
|
| 457 |
+
" # Fill the remaining data points with '-' if the chunk is less than evaluation_range\n",
|
| 458 |
+
" if len(chunk) < evaluation_range:\n",
|
| 459 |
+
" data_point_repr += '-'*(evaluation_range - len(chunk))\n",
|
| 460 |
+
" \n",
|
| 461 |
+
" if data_point_repr.count('-') > (evaluation_range - datapoints_to_alarm):\n",
|
| 462 |
+
" num_dp_that_must_be_filled = datapoints_to_alarm - sum([data_point_repr.count('0'), data_point_repr.count('X')])\n",
|
| 463 |
+
" \n",
|
| 464 |
+
" \n",
|
| 465 |
+
" data_table_dict[\"DataPoints\"].append(data_point_repr)\n",
|
| 466 |
+
" data_table_dict[\"# of data points that must be filled\"].append(num_dp_that_must_be_filled)\n",
|
| 467 |
+
" \n",
|
| 468 |
+
" data_table_dict[\"MISSING\"] = [\"\"]*len(data_table_dict[\"DataPoints\"])\n",
|
| 469 |
+
" data_table_dict[\"IGNORE\"] = [\"\"]*len(data_table_dict[\"DataPoints\"])\n",
|
| 470 |
+
" data_table_dict[\"BREACHING\"] = [\"\"]*len(data_table_dict[\"DataPoints\"])\n",
|
| 471 |
+
" data_table_dict[\"NOT BREACHING\"] = [\"\"]*len(data_table_dict[\"DataPoints\"])\n",
|
| 472 |
+
" \n",
|
| 473 |
+
" return pd.DataFrame(data_table_dict)\n",
|
| 474 |
+
"\n",
|
| 475 |
+
"\n",
|
| 476 |
+
"evaluate_alarm_state(\n",
|
| 477 |
+
" percentile_df=percentile_df,\n",
|
| 478 |
+
" threshold=150,\n",
|
| 479 |
+
" percentile_value=0.95,\n",
|
| 480 |
+
" datapoints_to_alarm=3,\n",
|
| 481 |
+
")"
|
| 482 |
+
]
|
| 483 |
+
},
|
| 484 |
+
{
|
| 485 |
+
"cell_type": "code",
|
| 486 |
+
"execution_count": null,
|
| 487 |
+
"metadata": {},
|
| 488 |
+
"outputs": [],
|
| 489 |
+
"source": []
|
| 490 |
+
}
|
| 491 |
+
],
|
| 492 |
+
"metadata": {
|
| 493 |
+
"kernelspec": {
|
| 494 |
+
"display_name": ".venv",
|
| 495 |
+
"language": "python",
|
| 496 |
+
"name": "python3"
|
| 497 |
+
},
|
| 498 |
+
"language_info": {
|
| 499 |
+
"codemirror_mode": {
|
| 500 |
+
"name": "ipython",
|
| 501 |
+
"version": 3
|
| 502 |
+
},
|
| 503 |
+
"file_extension": ".py",
|
| 504 |
+
"mimetype": "text/x-python",
|
| 505 |
+
"name": "python",
|
| 506 |
+
"nbconvert_exporter": "python",
|
| 507 |
+
"pygments_lexer": "ipython3",
|
| 508 |
+
"version": "3.9.6"
|
| 509 |
+
}
|
| 510 |
+
},
|
| 511 |
+
"nbformat": 4,
|
| 512 |
+
"nbformat_minor": 2
|
| 513 |
+
}
|
concattedfiles.py
ADDED
|
@@ -0,0 +1,381 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.
|
| 2 |
+
├── streamlit_app.py
|
| 3 |
+
└── utils.py
|
| 4 |
+
|
| 5 |
+
1 directory, 2 files
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# File: ./streamlit_app.py
|
| 10 |
+
import streamlit as st
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import matplotlib.pyplot as plt
|
| 13 |
+
from datetime import datetime, time, date
|
| 14 |
+
from typing import List, Dict, Any, Tuple
|
| 15 |
+
from utils import generate_random_data, calculate_percentile, evaluate_alarm_state, aggregate_data
|
| 16 |
+
|
| 17 |
+
# Constants
|
| 18 |
+
HARD_CODED_DATE = date(2024, 7, 26)
|
| 19 |
+
|
| 20 |
+
def main():
|
| 21 |
+
st.title("Streamlit App for Data Generation and Analysis")
|
| 22 |
+
|
| 23 |
+
# Initialize session state
|
| 24 |
+
initialize_session_state()
|
| 25 |
+
|
| 26 |
+
# Section 1 - Generate random data
|
| 27 |
+
st.header("Section 1 - Generate Random Data")
|
| 28 |
+
generate_data_form()
|
| 29 |
+
|
| 30 |
+
if not st.session_state.df.empty:
|
| 31 |
+
display_dataframe("Raw Event Data", st.session_state.df)
|
| 32 |
+
|
| 33 |
+
# Section 2 - Calculate Percentile
|
| 34 |
+
st.header("Section 2 - Calculate Percentile")
|
| 35 |
+
percentile_form()
|
| 36 |
+
|
| 37 |
+
if not st.session_state.percentile_df.empty:
|
| 38 |
+
display_dataframe("Aggregated Summary Data", st.session_state.percentile_df)
|
| 39 |
+
|
| 40 |
+
# Section 3 - Summary Data Aggregated by Period
|
| 41 |
+
st.header("Section 3 - Summary Data Aggregated by Period")
|
| 42 |
+
summary_by_period_form()
|
| 43 |
+
|
| 44 |
+
if not st.session_state.summary_by_period_df.empty:
|
| 45 |
+
display_dataframe("Summary Data Aggregated by Period", st.session_state.summary_by_period_df)
|
| 46 |
+
|
| 47 |
+
# Section 4 - Evaluate Alarm State
|
| 48 |
+
st.header("Section 4 - Evaluate Alarm State")
|
| 49 |
+
alarm_state_form()
|
| 50 |
+
|
| 51 |
+
if not st.session_state.alarm_state_df.empty:
|
| 52 |
+
plot_time_series(st.session_state.summary_by_period_df, st.session_state.threshold_input, st.session_state.alarm_condition_input, st.session_state.evaluation_range_input)
|
| 53 |
+
display_alarm_state_evaluation(st.session_state.alarm_state_df)
|
| 54 |
+
|
| 55 |
+
display_key_tables()
|
| 56 |
+
|
| 57 |
+
def initialize_session_state() -> None:
|
| 58 |
+
if 'df' not in st.session_state:
|
| 59 |
+
st.session_state.df = pd.DataFrame()
|
| 60 |
+
if 'percentile_df' not in st.session_state:
|
| 61 |
+
st.session_state.percentile_df = pd.DataFrame()
|
| 62 |
+
if 'summary_by_period_df' not in st.session_state:
|
| 63 |
+
st.session_state.summary_by_period_df = pd.DataFrame()
|
| 64 |
+
if 'alarm_state_df' not in st.session_state:
|
| 65 |
+
st.session_state.alarm_state_df = pd.DataFrame()
|
| 66 |
+
|
| 67 |
+
def generate_data_form() -> None:
|
| 68 |
+
with st.form(key='generate_data_form'):
|
| 69 |
+
start_time_input = st.time_input("Start Time", time(12, 0), help="Select the start time for generating random data.")
|
| 70 |
+
end_time_input = st.time_input("End Time", time(12, 30), help="Select the end time for generating random data.")
|
| 71 |
+
count_input = st.slider("Count", min_value=1, max_value=200, value=60, help="Specify the number of data points to generate.")
|
| 72 |
+
response_time_range_input = st.slider("Response Time Range (ms)", min_value=50, max_value=300, value=(100, 250), help="Select the range of response times in milliseconds.")
|
| 73 |
+
null_percentage_input = st.slider("Null Percentage", min_value=0.0, max_value=1.0, value=0.5, help="Select the percentage of null values in the generated data.")
|
| 74 |
+
submit_button = st.form_submit_button(label='Generate Data')
|
| 75 |
+
|
| 76 |
+
if submit_button:
|
| 77 |
+
st.session_state.df = generate_random_data(
|
| 78 |
+
date=HARD_CODED_DATE,
|
| 79 |
+
start_time=start_time_input,
|
| 80 |
+
end_time=end_time_input,
|
| 81 |
+
count=count_input,
|
| 82 |
+
response_time_range=response_time_range_input,
|
| 83 |
+
null_percentage=null_percentage_input
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
def percentile_form() -> None:
|
| 87 |
+
freq_input = st.selectbox("Period (bin)", ['1min', '5min', '15min'], key='freq_input', help="Select the frequency for aggregating the data.")
|
| 88 |
+
percentile_input = st.slider("Percentile", min_value=0.0, max_value=1.0, value=0.95, key='percentile_input', help="Select the percentile for calculating the aggregated summary data.")
|
| 89 |
+
if not st.session_state.df.empty:
|
| 90 |
+
st.session_state.percentile_df = calculate_percentile(st.session_state.df, freq_input, percentile_input)
|
| 91 |
+
|
| 92 |
+
def summary_by_period_form() -> None:
|
| 93 |
+
period_length_input = st.selectbox("Period Length", ['1min', '5min', '15min'], key='period_length_input', help="Select the period length for aggregating the summary data.")
|
| 94 |
+
if not st.session_state.df.empty:
|
| 95 |
+
st.session_state.summary_by_period_df = aggregate_data(st.session_state.df, period_length_input)
|
| 96 |
+
|
| 97 |
+
def alarm_state_form() -> None:
|
| 98 |
+
threshold_input = st.number_input("Threshold (ms)", min_value=50, max_value=300, value=150, key='threshold_input', help="Specify the threshold value for evaluating the alarm state.")
|
| 99 |
+
datapoints_to_alarm_input = st.number_input("Datapoints to Alarm", min_value=1, value=3, key='datapoints_to_alarm_input', help="Specify the number of data points required to trigger an alarm.")
|
| 100 |
+
evaluation_range_input = st.number_input("Evaluation Range", min_value=1, value=5, key='evaluation_range_input', help="Specify the range of data points to evaluate for alarm state.")
|
| 101 |
+
aggregation_function_input = st.selectbox(
|
| 102 |
+
"Aggregation Function",
|
| 103 |
+
['p50', 'p95', 'p99', 'max', 'min', 'average'],
|
| 104 |
+
key='aggregation_function_input',
|
| 105 |
+
help="Select the aggregation function for visualizing the data and computing alarms."
|
| 106 |
+
)
|
| 107 |
+
alarm_condition_input = st.selectbox(
|
| 108 |
+
"Alarm Condition",
|
| 109 |
+
['>', '>=', '<', '<='],
|
| 110 |
+
key='alarm_condition_input',
|
| 111 |
+
help="Select the condition for evaluating the alarm state."
|
| 112 |
+
)
|
| 113 |
+
if not st.session_state.summary_by_period_df.empty:
|
| 114 |
+
st.session_state.alarm_state_df = evaluate_alarm_state(
|
| 115 |
+
summary_df=st.session_state.summary_by_period_df,
|
| 116 |
+
threshold=threshold_input,
|
| 117 |
+
datapoints_to_alarm=datapoints_to_alarm_input,
|
| 118 |
+
evaluation_range=evaluation_range_input,
|
| 119 |
+
aggregation_function=aggregation_function_input,
|
| 120 |
+
alarm_condition=alarm_condition_input
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
def display_dataframe(title: str, df: pd.DataFrame) -> None:
|
| 124 |
+
st.write(title)
|
| 125 |
+
st.dataframe(df)
|
| 126 |
+
|
| 127 |
+
def plot_time_series(df: pd.DataFrame, threshold: int, alarm_condition: str, evaluation_range: int) -> None:
|
| 128 |
+
timestamps = df['Timestamp']
|
| 129 |
+
response_times = df[st.session_state.aggregation_function_input]
|
| 130 |
+
|
| 131 |
+
segments = []
|
| 132 |
+
current_segment = {'timestamps': [], 'values': []}
|
| 133 |
+
|
| 134 |
+
for timestamp, value in zip(timestamps, response_times):
|
| 135 |
+
if pd.isna(value):
|
| 136 |
+
if current_segment['timestamps']:
|
| 137 |
+
segments.append(current_segment)
|
| 138 |
+
current_segment = {'timestamps': [], 'values': []}
|
| 139 |
+
else:
|
| 140 |
+
current_segment['timestamps'].append(timestamp)
|
| 141 |
+
current_segment['values'].append(value)
|
| 142 |
+
|
| 143 |
+
if current_segment['timestamps']:
|
| 144 |
+
segments.append(current_segment)
|
| 145 |
+
|
| 146 |
+
fig, ax1 = plt.subplots()
|
| 147 |
+
|
| 148 |
+
color = 'tab:blue'
|
| 149 |
+
ax1.set_xlabel('Timestamp')
|
| 150 |
+
ax1.set_ylabel('Response Time (ms)', color=color)
|
| 151 |
+
|
| 152 |
+
for segment in segments:
|
| 153 |
+
ax1.plot(segment['timestamps'], segment['values'], color=color, linewidth=0.5)
|
| 154 |
+
ax1.scatter(segment['timestamps'], segment['values'], color=color, s=10)
|
| 155 |
+
|
| 156 |
+
line_style = '--' if alarm_condition in ['<', '>'] else '-'
|
| 157 |
+
ax1.axhline(y=threshold, color='r', linestyle=line_style, linewidth=0.8, label='Threshold')
|
| 158 |
+
ax1.tick_params(axis='y', labelcolor=color)
|
| 159 |
+
|
| 160 |
+
if alarm_condition in ['<=', '<']:
|
| 161 |
+
ax1.fill_between(timestamps, 0, threshold, color='pink', alpha=0.3)
|
| 162 |
+
else:
|
| 163 |
+
ax1.fill_between(timestamps, threshold, response_times.max(), color='pink', alpha=0.3)
|
| 164 |
+
|
| 165 |
+
period_indices = range(len(df))
|
| 166 |
+
ax2 = ax1.twiny()
|
| 167 |
+
ax2.set_xticks(period_indices)
|
| 168 |
+
ax2.set_xticklabels(period_indices, fontsize=8)
|
| 169 |
+
ax2.set_xlabel('Time Periods', fontsize=8)
|
| 170 |
+
ax2.xaxis.set_tick_params(width=0.5)
|
| 171 |
+
|
| 172 |
+
for idx in period_indices:
|
| 173 |
+
if idx % evaluation_range == 0:
|
| 174 |
+
ax1.axvline(x=df['Timestamp'].iloc[idx], color='green', linestyle='-', alpha=0.3)
|
| 175 |
+
max_value = max(filter(lambda x: x is not None, df[st.session_state.aggregation_function_input]))
|
| 176 |
+
ax1.text(df['Timestamp'].iloc[idx], max_value * 0.95, f"[{idx // evaluation_range}]", rotation=90, verticalalignment='bottom', color='grey', alpha=0.7, fontsize=8)
|
| 177 |
+
else:
|
| 178 |
+
ax1.axvline(x=df['Timestamp'].iloc[idx], color='grey', linestyle='--', alpha=0.3)
|
| 179 |
+
|
| 180 |
+
ax1.annotate('Alarm threshold', xy=(0.98, threshold), xycoords=('axes fraction', 'data'), ha='right', va='bottom', fontsize=8, color='red', backgroundcolor='none')
|
| 181 |
+
|
| 182 |
+
fig.tight_layout()
|
| 183 |
+
st.pyplot(fig)
|
| 184 |
+
|
| 185 |
+
def display_alarm_state_evaluation(df: pd.DataFrame) -> None:
|
| 186 |
+
st.write("Alarm State Evaluation")
|
| 187 |
+
st.dataframe(df)
|
| 188 |
+
|
| 189 |
+
def display_key_tables() -> None:
|
| 190 |
+
st.write("### Key")
|
| 191 |
+
|
| 192 |
+
# Symbols
|
| 193 |
+
st.write("#### Symbols")
|
| 194 |
+
symbol_data = {
|
| 195 |
+
"Symbol": ["X", "-", "0"],
|
| 196 |
+
"Meaning": [
|
| 197 |
+
"Breaching data point: This data point exceeds the threshold.",
|
| 198 |
+
"Missing data point: This data point is missing or not reported.",
|
| 199 |
+
"Non-breaching data point: This data point is within the threshold."
|
| 200 |
+
]
|
| 201 |
+
}
|
| 202 |
+
symbol_df = pd.DataFrame(symbol_data)
|
| 203 |
+
st.table(symbol_df)
|
| 204 |
+
|
| 205 |
+
# Columns
|
| 206 |
+
st.write("#### Columns")
|
| 207 |
+
column_data = {
|
| 208 |
+
"Column": ["MISSING", "IGNORE", "BREACHING", "NOT BREACHING"],
|
| 209 |
+
"Meaning": [
|
| 210 |
+
"Action to take when all data points are missing. Possible values: INSUFFICIENT_DATA, Retain current state, ALARM, OK.",
|
| 211 |
+
"Action to take when data points are missing but ignored. Possible values: Retain current state, ALARM, OK.",
|
| 212 |
+
"Action to take when missing data points are treated as breaching. Possible values: ALARM, OK.",
|
| 213 |
+
"Action to take when missing data points are treated as not breaching. Possible values: ALARM, OK."
|
| 214 |
+
]
|
| 215 |
+
}
|
| 216 |
+
column_df = pd.DataFrame(column_data)
|
| 217 |
+
st.table(column_df)
|
| 218 |
+
|
| 219 |
+
# States
|
| 220 |
+
st.write("#### States")
|
| 221 |
+
state_data = {
|
| 222 |
+
"State": ["ALARM", "OK", "Retain current state", "INSUFFICIENT_DATA"],
|
| 223 |
+
"Description": [
|
| 224 |
+
"Alarm state is triggered.",
|
| 225 |
+
"Everything is within the threshold.",
|
| 226 |
+
"The current alarm state is maintained.",
|
| 227 |
+
"Not enough data to make a determination."
|
| 228 |
+
]
|
| 229 |
+
}
|
| 230 |
+
state_df = pd.DataFrame(state_data)
|
| 231 |
+
st.table(state_df)
|
| 232 |
+
|
| 233 |
+
if __name__ == "__main__":
|
| 234 |
+
main()
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
# File: ./utils.py
|
| 239 |
+
import random
|
| 240 |
+
from datetime import datetime, timedelta, date, time
|
| 241 |
+
import pandas as pd
|
| 242 |
+
import numpy as np
|
| 243 |
+
from typing import List, Iterator, Dict, Any, Optional
|
| 244 |
+
|
| 245 |
+
def generate_random_data(
|
| 246 |
+
date: date,
|
| 247 |
+
start_time: time,
|
| 248 |
+
end_time: time,
|
| 249 |
+
count: int,
|
| 250 |
+
response_time_range: (int, int),
|
| 251 |
+
null_percentage: float
|
| 252 |
+
) -> pd.DataFrame:
|
| 253 |
+
start_datetime: datetime = datetime.combine(date, start_time)
|
| 254 |
+
end_datetime: datetime = datetime.combine(date, end_time)
|
| 255 |
+
|
| 256 |
+
random_timestamps: List[datetime] = [
|
| 257 |
+
start_datetime + timedelta(seconds=random.randint(0, int((end_datetime - start_datetime).total_seconds())))
|
| 258 |
+
for _ in range(count)
|
| 259 |
+
]
|
| 260 |
+
random_timestamps.sort()
|
| 261 |
+
|
| 262 |
+
random_response_times: List[Optional[int]] = [
|
| 263 |
+
random.randint(response_time_range[0], response_time_range[1]) for _ in range(count)
|
| 264 |
+
]
|
| 265 |
+
|
| 266 |
+
null_count: int = int(null_percentage * count)
|
| 267 |
+
null_indices: List[int] = random.sample(range(count), null_count)
|
| 268 |
+
for idx in null_indices:
|
| 269 |
+
random_response_times[idx] = None
|
| 270 |
+
|
| 271 |
+
data: Dict[str, Any] = {
|
| 272 |
+
'Timestamp': random_timestamps,
|
| 273 |
+
'ResponseTime(ms)': random_response_times
|
| 274 |
+
}
|
| 275 |
+
df: pd.DataFrame = pd.DataFrame(data)
|
| 276 |
+
return df
|
| 277 |
+
|
| 278 |
+
def calculate_percentile(
|
| 279 |
+
df: pd.DataFrame,
|
| 280 |
+
freq: str,
|
| 281 |
+
percentile: float
|
| 282 |
+
) -> pd.DataFrame:
|
| 283 |
+
percentile_df: pd.DataFrame = df.groupby(pd.Grouper(key='Timestamp', freq=freq))["ResponseTime(ms)"]\
|
| 284 |
+
.quantile(percentile).reset_index(name=f"p{int(percentile * 100)}_ResponseTime(ms)")
|
| 285 |
+
percentile_df.replace(to_replace=np.nan, value=None, inplace=True)
|
| 286 |
+
return percentile_df
|
| 287 |
+
|
| 288 |
+
def aggregate_data(
|
| 289 |
+
df: pd.DataFrame,
|
| 290 |
+
period_length: str
|
| 291 |
+
) -> pd.DataFrame:
|
| 292 |
+
aggregation_funcs = {
|
| 293 |
+
'p50': lambda x: np.percentile(x.dropna(), 50),
|
| 294 |
+
'p95': lambda x: np.percentile(x.dropna(), 95),
|
| 295 |
+
'p99': lambda x: np.percentile(x.dropna(), 99),
|
| 296 |
+
'max': lambda x: np.max(x.dropna()),
|
| 297 |
+
'min': lambda x: np.min(x.dropna()),
|
| 298 |
+
'average': lambda x: np.mean(x.dropna())
|
| 299 |
+
}
|
| 300 |
+
|
| 301 |
+
summary_df = df.groupby(pd.Grouper(key='Timestamp', freq=period_length)).agg(
|
| 302 |
+
p50=('ResponseTime(ms)', aggregation_funcs['p50']),
|
| 303 |
+
p95=('ResponseTime(ms)', aggregation_funcs['p95']),
|
| 304 |
+
p99=('ResponseTime(ms)', aggregation_funcs['p99']),
|
| 305 |
+
max=('ResponseTime(ms)', aggregation_funcs['max']),
|
| 306 |
+
min=('ResponseTime(ms)', aggregation_funcs['min']),
|
| 307 |
+
average=('ResponseTime(ms)', aggregation_funcs['average']),
|
| 308 |
+
).reset_index()
|
| 309 |
+
return summary_df
|
| 310 |
+
|
| 311 |
+
def chunk_list(input_list: List[Any], size: int = 3) -> Iterator[List[Any]]:
|
| 312 |
+
while input_list:
|
| 313 |
+
chunk: List[Any] = input_list[:size]
|
| 314 |
+
yield chunk
|
| 315 |
+
input_list = input_list[size:]
|
| 316 |
+
|
| 317 |
+
def evaluate_alarm_state(
|
| 318 |
+
summary_df: pd.DataFrame,
|
| 319 |
+
threshold: int,
|
| 320 |
+
datapoints_to_alarm: int,
|
| 321 |
+
evaluation_range: int,
|
| 322 |
+
aggregation_function: str,
|
| 323 |
+
alarm_condition: str
|
| 324 |
+
) -> pd.DataFrame:
|
| 325 |
+
data_points: List[Optional[float]] = list(summary_df[aggregation_function].values)
|
| 326 |
+
|
| 327 |
+
data_table_dict: Dict[str, List[Any]] = {
|
| 328 |
+
"DataPoints": [],
|
| 329 |
+
"# of data points that must be filled": [],
|
| 330 |
+
"MISSING": [],
|
| 331 |
+
"IGNORE": [],
|
| 332 |
+
"BREACHING": [],
|
| 333 |
+
"NOT BREACHING": []
|
| 334 |
+
}
|
| 335 |
+
|
| 336 |
+
def check_condition(value, threshold, condition):
|
| 337 |
+
if condition == '>':
|
| 338 |
+
return value > threshold
|
| 339 |
+
elif condition == '>=':
|
| 340 |
+
return value >= threshold
|
| 341 |
+
elif condition == '<':
|
| 342 |
+
return value < threshold
|
| 343 |
+
elif condition == '<=':
|
| 344 |
+
return value <= threshold
|
| 345 |
+
|
| 346 |
+
for chunk in chunk_list(input_list=data_points, size=evaluation_range):
|
| 347 |
+
data_point_repr: str = ''
|
| 348 |
+
num_dp_that_must_be_filled: int = 0
|
| 349 |
+
|
| 350 |
+
for dp in chunk:
|
| 351 |
+
if dp is None:
|
| 352 |
+
data_point_repr += '-'
|
| 353 |
+
elif check_condition(dp, threshold, alarm_condition):
|
| 354 |
+
data_point_repr += 'X'
|
| 355 |
+
else:
|
| 356 |
+
data_point_repr += '0'
|
| 357 |
+
|
| 358 |
+
if len(chunk) < evaluation_range:
|
| 359 |
+
data_point_repr += '-' * (evaluation_range - len(chunk))
|
| 360 |
+
|
| 361 |
+
if data_point_repr.count('-') > (evaluation_range - datapoints_to_alarm):
|
| 362 |
+
num_dp_that_must_be_filled = datapoints_to_alarm - sum([data_point_repr.count('0'), data_point_repr.count('X')])
|
| 363 |
+
|
| 364 |
+
data_table_dict["DataPoints"].append(data_point_repr)
|
| 365 |
+
data_table_dict["# of data points that must be filled"].append(num_dp_that_must_be_filled)
|
| 366 |
+
|
| 367 |
+
if num_dp_that_must_be_filled > 0:
|
| 368 |
+
data_table_dict["MISSING"].append("INSUFFICIENT_DATA" if data_point_repr.count('-') == evaluation_range else "Retain current state")
|
| 369 |
+
data_table_dict["IGNORE"].append("Retain current state")
|
| 370 |
+
data_table_dict["BREACHING"].append("ALARM")
|
| 371 |
+
data_table_dict["NOT BREACHING"].append("OK")
|
| 372 |
+
else:
|
| 373 |
+
data_table_dict["MISSING"].append("OK")
|
| 374 |
+
data_table_dict["IGNORE"].append("Retain current state")
|
| 375 |
+
data_table_dict["BREACHING"].append("ALARM" if 'X' * datapoints_to_alarm in data_point_repr else "OK")
|
| 376 |
+
data_table_dict["NOT BREACHING"].append("ALARM" if '0' * datapoints_to_alarm not in data_point_repr else "OK")
|
| 377 |
+
|
| 378 |
+
return pd.DataFrame(data_table_dict)
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
|
cw-alarm-creation-form.png
ADDED
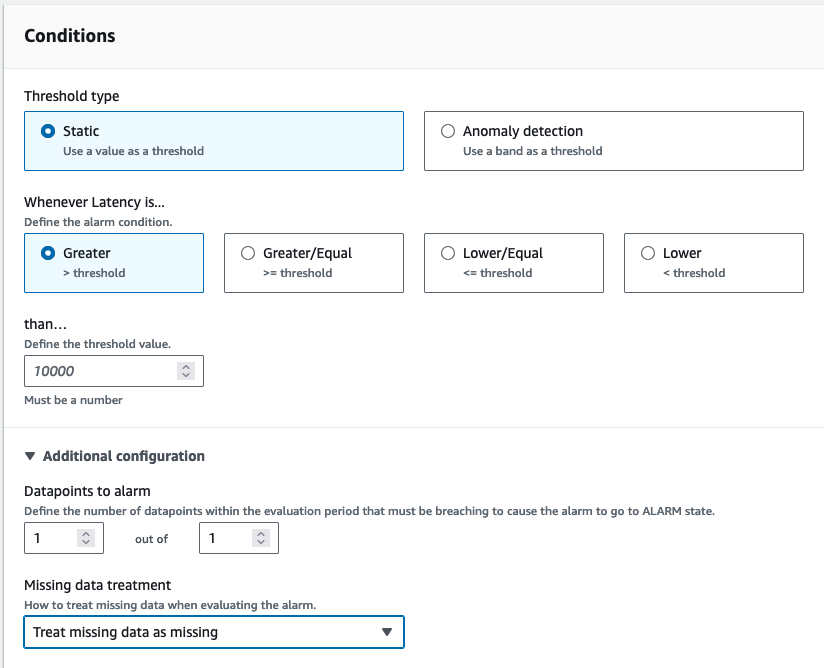
|
cw-alarm-missing-data-treatment.png
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pandas
|
| 2 |
+
numpy
|
| 3 |
+
ipykernel
|
| 4 |
+
jupyterlab
|
| 5 |
+
streamlit
|
| 6 |
+
matplotlib
|
streamlit_app.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
from datetime import datetime, time, date
|
| 5 |
+
from typing import List, Dict, Any, Tuple
|
| 6 |
+
from utils import generate_random_data, calculate_percentile, evaluate_alarm_state, aggregate_data
|
| 7 |
+
|
| 8 |
+
# Constants
|
| 9 |
+
HARD_CODED_DATE = date(2024, 7, 26)
|
| 10 |
+
|
| 11 |
+
def main():
|
| 12 |
+
st.title("Streamlit App for Data Generation and Analysis")
|
| 13 |
+
|
| 14 |
+
# Initialize session state
|
| 15 |
+
initialize_session_state()
|
| 16 |
+
|
| 17 |
+
# Section 1 - Generate random data
|
| 18 |
+
st.header("Section 1 - Generate Random Data")
|
| 19 |
+
generate_data_form()
|
| 20 |
+
|
| 21 |
+
if not st.session_state.df.empty:
|
| 22 |
+
display_dataframe("Raw Event Data", st.session_state.df)
|
| 23 |
+
|
| 24 |
+
# Section 2 - Calculate Percentile
|
| 25 |
+
st.header("Section 2 - Calculate Percentile")
|
| 26 |
+
percentile_form()
|
| 27 |
+
|
| 28 |
+
if not st.session_state.percentile_df.empty:
|
| 29 |
+
display_dataframe("Aggregated Summary Data", st.session_state.percentile_df)
|
| 30 |
+
|
| 31 |
+
# Section 3 - Summary Data Aggregated by Period
|
| 32 |
+
st.header("Section 3 - Summary Data Aggregated by Period")
|
| 33 |
+
summary_by_period_form()
|
| 34 |
+
|
| 35 |
+
if not st.session_state.summary_by_period_df.empty:
|
| 36 |
+
display_dataframe("Summary Data Aggregated by Period", st.session_state.summary_by_period_df)
|
| 37 |
+
|
| 38 |
+
# Section 4 - Evaluate Alarm State
|
| 39 |
+
st.header("Section 4 - Evaluate Alarm State")
|
| 40 |
+
alarm_state_form()
|
| 41 |
+
|
| 42 |
+
if not st.session_state.alarm_state_df.empty:
|
| 43 |
+
plot_time_series(st.session_state.summary_by_period_df, st.session_state.threshold_input, st.session_state.alarm_condition_input, st.session_state.evaluation_range_input)
|
| 44 |
+
display_alarm_state_evaluation(st.session_state.alarm_state_df)
|
| 45 |
+
|
| 46 |
+
display_key_tables()
|
| 47 |
+
|
| 48 |
+
def initialize_session_state() -> None:
|
| 49 |
+
if 'df' not in st.session_state:
|
| 50 |
+
st.session_state.df = pd.DataFrame()
|
| 51 |
+
if 'percentile_df' not in st.session_state:
|
| 52 |
+
st.session_state.percentile_df = pd.DataFrame()
|
| 53 |
+
if 'summary_by_period_df' not in st.session_state:
|
| 54 |
+
st.session_state.summary_by_period_df = pd.DataFrame()
|
| 55 |
+
if 'alarm_state_df' not in st.session_state:
|
| 56 |
+
st.session_state.alarm_state_df = pd.DataFrame()
|
| 57 |
+
|
| 58 |
+
def generate_data_form() -> None:
|
| 59 |
+
with st.form(key='generate_data_form'):
|
| 60 |
+
start_time_input = st.time_input("Start Time", time(12, 0), help="Select the start time for generating random data.")
|
| 61 |
+
end_time_input = st.time_input("End Time", time(12, 30), help="Select the end time for generating random data.")
|
| 62 |
+
count_input = st.slider("Count", min_value=1, max_value=200, value=60, help="Specify the number of data points to generate.")
|
| 63 |
+
response_time_range_input = st.slider("Response Time Range (ms)", min_value=50, max_value=300, value=(100, 250), help="Select the range of response times in milliseconds.")
|
| 64 |
+
null_percentage_input = st.slider("Null Percentage", min_value=0.0, max_value=1.0, value=0.5, help="Select the percentage of null values in the generated data.")
|
| 65 |
+
submit_button = st.form_submit_button(label='Generate Data')
|
| 66 |
+
|
| 67 |
+
if submit_button:
|
| 68 |
+
st.session_state.df = generate_random_data(
|
| 69 |
+
date=HARD_CODED_DATE,
|
| 70 |
+
start_time=start_time_input,
|
| 71 |
+
end_time=end_time_input,
|
| 72 |
+
count=count_input,
|
| 73 |
+
response_time_range=response_time_range_input,
|
| 74 |
+
null_percentage=null_percentage_input
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
def percentile_form() -> None:
|
| 78 |
+
freq_input = st.selectbox("Period (bin)", ['1min', '5min', '15min'], key='freq_input', help="Select the frequency for aggregating the data.")
|
| 79 |
+
percentile_input = st.slider("Percentile", min_value=0.0, max_value=1.0, value=0.95, key='percentile_input', help="Select the percentile for calculating the aggregated summary data.")
|
| 80 |
+
if not st.session_state.df.empty:
|
| 81 |
+
st.session_state.percentile_df = calculate_percentile(st.session_state.df, freq_input, percentile_input)
|
| 82 |
+
|
| 83 |
+
def summary_by_period_form() -> None:
|
| 84 |
+
period_length_input = st.selectbox("Period Length", ['1min', '5min', '15min'], key='period_length_input', help="Select the period length for aggregating the summary data.")
|
| 85 |
+
if not st.session_state.df.empty:
|
| 86 |
+
st.session_state.summary_by_period_df = aggregate_data(st.session_state.df, period_length_input)
|
| 87 |
+
|
| 88 |
+
def alarm_state_form() -> None:
|
| 89 |
+
threshold_input = st.number_input("Threshold (ms)", min_value=50, max_value=300, value=150, key='threshold_input', help="Specify the threshold value for evaluating the alarm state.")
|
| 90 |
+
datapoints_to_alarm_input = st.number_input("Datapoints to Alarm", min_value=1, value=3, key='datapoints_to_alarm_input', help="Specify the number of data points required to trigger an alarm.")
|
| 91 |
+
evaluation_range_input = st.number_input("Evaluation Range", min_value=1, value=5, key='evaluation_range_input', help="Specify the range of data points to evaluate for alarm state.")
|
| 92 |
+
aggregation_function_input = st.selectbox(
|
| 93 |
+
"Aggregation Function",
|
| 94 |
+
['p50', 'p95', 'p99', 'max', 'min', 'average'],
|
| 95 |
+
key='aggregation_function_input',
|
| 96 |
+
help="Select the aggregation function for visualizing the data and computing alarms."
|
| 97 |
+
)
|
| 98 |
+
alarm_condition_input = st.selectbox(
|
| 99 |
+
"Alarm Condition",
|
| 100 |
+
['>', '>=', '<', '<='],
|
| 101 |
+
key='alarm_condition_input',
|
| 102 |
+
help="Select the condition for evaluating the alarm state."
|
| 103 |
+
)
|
| 104 |
+
if not st.session_state.summary_by_period_df.empty:
|
| 105 |
+
st.session_state.alarm_state_df = evaluate_alarm_state(
|
| 106 |
+
summary_df=st.session_state.summary_by_period_df,
|
| 107 |
+
threshold=threshold_input,
|
| 108 |
+
datapoints_to_alarm=datapoints_to_alarm_input,
|
| 109 |
+
evaluation_range=evaluation_range_input,
|
| 110 |
+
aggregation_function=aggregation_function_input,
|
| 111 |
+
alarm_condition=alarm_condition_input
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
def display_dataframe(title: str, df: pd.DataFrame) -> None:
|
| 115 |
+
st.write(title)
|
| 116 |
+
st.dataframe(df)
|
| 117 |
+
|
| 118 |
+
def plot_time_series(df: pd.DataFrame, threshold: int, alarm_condition: str, evaluation_range: int) -> None:
|
| 119 |
+
timestamps = df['Timestamp']
|
| 120 |
+
response_times = df[st.session_state.aggregation_function_input]
|
| 121 |
+
|
| 122 |
+
segments = []
|
| 123 |
+
current_segment = {'timestamps': [], 'values': []}
|
| 124 |
+
|
| 125 |
+
for timestamp, value in zip(timestamps, response_times):
|
| 126 |
+
if pd.isna(value):
|
| 127 |
+
if current_segment['timestamps']:
|
| 128 |
+
segments.append(current_segment)
|
| 129 |
+
current_segment = {'timestamps': [], 'values': []}
|
| 130 |
+
else:
|
| 131 |
+
current_segment['timestamps'].append(timestamp)
|
| 132 |
+
current_segment['values'].append(value)
|
| 133 |
+
|
| 134 |
+
if current_segment['timestamps']:
|
| 135 |
+
segments.append(current_segment)
|
| 136 |
+
|
| 137 |
+
fig, ax1 = plt.subplots()
|
| 138 |
+
|
| 139 |
+
color = 'tab:blue'
|
| 140 |
+
ax1.set_xlabel('Timestamp')
|
| 141 |
+
ax1.set_ylabel('Response Time (ms)', color=color)
|
| 142 |
+
|
| 143 |
+
for segment in segments:
|
| 144 |
+
ax1.plot(segment['timestamps'], segment['values'], color=color, linewidth=0.5)
|
| 145 |
+
ax1.scatter(segment['timestamps'], segment['values'], color=color, s=10)
|
| 146 |
+
|
| 147 |
+
line_style = '--' if alarm_condition in ['<', '>'] else '-'
|
| 148 |
+
ax1.axhline(y=threshold, color='r', linestyle=line_style, linewidth=0.8, label='Threshold')
|
| 149 |
+
ax1.tick_params(axis='y', labelcolor=color)
|
| 150 |
+
|
| 151 |
+
if alarm_condition in ['<=', '<']:
|
| 152 |
+
ax1.fill_between(timestamps, 0, threshold, color='pink', alpha=0.3)
|
| 153 |
+
else:
|
| 154 |
+
ax1.fill_between(timestamps, threshold, response_times.max(), color='pink', alpha=0.3)
|
| 155 |
+
|
| 156 |
+
period_indices = range(len(df))
|
| 157 |
+
ax2 = ax1.twiny()
|
| 158 |
+
ax2.set_xticks(period_indices)
|
| 159 |
+
ax2.set_xticklabels(period_indices, fontsize=8)
|
| 160 |
+
ax2.set_xlabel('Time Periods', fontsize=8)
|
| 161 |
+
ax2.xaxis.set_tick_params(width=0.5)
|
| 162 |
+
|
| 163 |
+
for idx in period_indices:
|
| 164 |
+
if idx % evaluation_range == 0:
|
| 165 |
+
ax1.axvline(x=df['Timestamp'].iloc[idx], color='green', linestyle='-', alpha=0.3)
|
| 166 |
+
max_value = max(filter(lambda x: x is not None, df[st.session_state.aggregation_function_input]))
|
| 167 |
+
ax1.text(df['Timestamp'].iloc[idx], max_value * 0.95, f"[{idx // evaluation_range}]", rotation=90, verticalalignment='bottom', color='grey', alpha=0.7, fontsize=8)
|
| 168 |
+
else:
|
| 169 |
+
ax1.axvline(x=df['Timestamp'].iloc[idx], color='grey', linestyle='--', alpha=0.3)
|
| 170 |
+
|
| 171 |
+
ax1.annotate('Alarm threshold', xy=(0.98, threshold), xycoords=('axes fraction', 'data'), ha='right', va='bottom', fontsize=8, color='red', backgroundcolor='none')
|
| 172 |
+
|
| 173 |
+
fig.tight_layout()
|
| 174 |
+
st.pyplot(fig)
|
| 175 |
+
|
| 176 |
+
def display_alarm_state_evaluation(df: pd.DataFrame) -> None:
|
| 177 |
+
st.write("Alarm State Evaluation")
|
| 178 |
+
st.dataframe(df)
|
| 179 |
+
|
| 180 |
+
def display_key_tables() -> None:
|
| 181 |
+
st.write("### Key")
|
| 182 |
+
|
| 183 |
+
# Symbols
|
| 184 |
+
st.write("#### Symbols")
|
| 185 |
+
symbol_data = {
|
| 186 |
+
"Symbol": ["X", "-", "0"],
|
| 187 |
+
"Meaning": [
|
| 188 |
+
"Breaching data point: This data point exceeds the threshold.",
|
| 189 |
+
"Missing data point: This data point is missing or not reported.",
|
| 190 |
+
"Non-breaching data point: This data point is within the threshold."
|
| 191 |
+
]
|
| 192 |
+
}
|
| 193 |
+
symbol_df = pd.DataFrame(symbol_data)
|
| 194 |
+
st.table(symbol_df)
|
| 195 |
+
|
| 196 |
+
# Columns
|
| 197 |
+
st.write("#### Columns")
|
| 198 |
+
column_data = {
|
| 199 |
+
"Column": ["MISSING", "IGNORE", "BREACHING", "NOT BREACHING"],
|
| 200 |
+
"Meaning": [
|
| 201 |
+
"Action to take when all data points are missing. Possible values: INSUFFICIENT_DATA, Retain current state, ALARM, OK.",
|
| 202 |
+
"Action to take when data points are missing but ignored. Possible values: Retain current state, ALARM, OK.",
|
| 203 |
+
"Action to take when missing data points are treated as breaching. Possible values: ALARM, OK.",
|
| 204 |
+
"Action to take when missing data points are treated as not breaching. Possible values: ALARM, OK."
|
| 205 |
+
]
|
| 206 |
+
}
|
| 207 |
+
column_df = pd.DataFrame(column_data)
|
| 208 |
+
st.table(column_df)
|
| 209 |
+
|
| 210 |
+
# States
|
| 211 |
+
st.write("#### States")
|
| 212 |
+
state_data = {
|
| 213 |
+
"State": ["ALARM", "OK", "Retain current state", "INSUFFICIENT_DATA"],
|
| 214 |
+
"Description": [
|
| 215 |
+
"Alarm state is triggered.",
|
| 216 |
+
"Everything is within the threshold.",
|
| 217 |
+
"The current alarm state is maintained.",
|
| 218 |
+
"Not enough data to make a determination."
|
| 219 |
+
]
|
| 220 |
+
}
|
| 221 |
+
state_df = pd.DataFrame(state_data)
|
| 222 |
+
st.table(state_df)
|
| 223 |
+
|
| 224 |
+
if __name__ == "__main__":
|
| 225 |
+
main()
|
utils.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
from datetime import datetime, timedelta, date, time
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
from typing import List, Iterator, Dict, Any, Optional
|
| 6 |
+
|
| 7 |
+
def generate_random_data(
|
| 8 |
+
date: date,
|
| 9 |
+
start_time: time,
|
| 10 |
+
end_time: time,
|
| 11 |
+
count: int,
|
| 12 |
+
response_time_range: (int, int),
|
| 13 |
+
null_percentage: float
|
| 14 |
+
) -> pd.DataFrame:
|
| 15 |
+
start_datetime: datetime = datetime.combine(date, start_time)
|
| 16 |
+
end_datetime: datetime = datetime.combine(date, end_time)
|
| 17 |
+
|
| 18 |
+
random_timestamps: List[datetime] = [
|
| 19 |
+
start_datetime + timedelta(seconds=random.randint(0, int((end_datetime - start_datetime).total_seconds())))
|
| 20 |
+
for _ in range(count)
|
| 21 |
+
]
|
| 22 |
+
random_timestamps.sort()
|
| 23 |
+
|
| 24 |
+
random_response_times: List[Optional[int]] = [
|
| 25 |
+
random.randint(response_time_range[0], response_time_range[1]) for _ in range(count)
|
| 26 |
+
]
|
| 27 |
+
|
| 28 |
+
null_count: int = int(null_percentage * count)
|
| 29 |
+
null_indices: List[int] = random.sample(range(count), null_count)
|
| 30 |
+
for idx in null_indices:
|
| 31 |
+
random_response_times[idx] = None
|
| 32 |
+
|
| 33 |
+
data: Dict[str, Any] = {
|
| 34 |
+
'Timestamp': random_timestamps,
|
| 35 |
+
'ResponseTime(ms)': random_response_times
|
| 36 |
+
}
|
| 37 |
+
df: pd.DataFrame = pd.DataFrame(data)
|
| 38 |
+
return df
|
| 39 |
+
|
| 40 |
+
def calculate_percentile(
|
| 41 |
+
df: pd.DataFrame,
|
| 42 |
+
freq: str,
|
| 43 |
+
percentile: float
|
| 44 |
+
) -> pd.DataFrame:
|
| 45 |
+
percentile_df: pd.DataFrame = df.groupby(pd.Grouper(key='Timestamp', freq=freq))["ResponseTime(ms)"]\
|
| 46 |
+
.quantile(percentile).reset_index(name=f"p{int(percentile * 100)}_ResponseTime(ms)")
|
| 47 |
+
percentile_df.replace(to_replace=np.nan, value=None, inplace=True)
|
| 48 |
+
return percentile_df
|
| 49 |
+
|
| 50 |
+
def aggregate_data(
|
| 51 |
+
df: pd.DataFrame,
|
| 52 |
+
period_length: str
|
| 53 |
+
) -> pd.DataFrame:
|
| 54 |
+
aggregation_funcs = {
|
| 55 |
+
'p50': lambda x: np.percentile(x.dropna(), 50),
|
| 56 |
+
'p95': lambda x: np.percentile(x.dropna(), 95),
|
| 57 |
+
'p99': lambda x: np.percentile(x.dropna(), 99),
|
| 58 |
+
'max': lambda x: np.max(x.dropna()),
|
| 59 |
+
'min': lambda x: np.min(x.dropna()),
|
| 60 |
+
'average': lambda x: np.mean(x.dropna())
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
summary_df = df.groupby(pd.Grouper(key='Timestamp', freq=period_length)).agg(
|
| 64 |
+
p50=('ResponseTime(ms)', aggregation_funcs['p50']),
|
| 65 |
+
p95=('ResponseTime(ms)', aggregation_funcs['p95']),
|
| 66 |
+
p99=('ResponseTime(ms)', aggregation_funcs['p99']),
|
| 67 |
+
max=('ResponseTime(ms)', aggregation_funcs['max']),
|
| 68 |
+
min=('ResponseTime(ms)', aggregation_funcs['min']),
|
| 69 |
+
average=('ResponseTime(ms)', aggregation_funcs['average']),
|
| 70 |
+
).reset_index()
|
| 71 |
+
return summary_df
|
| 72 |
+
|
| 73 |
+
def chunk_list(input_list: List[Any], size: int = 3) -> Iterator[List[Any]]:
|
| 74 |
+
while input_list:
|
| 75 |
+
chunk: List[Any] = input_list[:size]
|
| 76 |
+
yield chunk
|
| 77 |
+
input_list = input_list[size:]
|
| 78 |
+
|
| 79 |
+
def evaluate_alarm_state(
|
| 80 |
+
summary_df: pd.DataFrame,
|
| 81 |
+
threshold: int,
|
| 82 |
+
datapoints_to_alarm: int,
|
| 83 |
+
evaluation_range: int,
|
| 84 |
+
aggregation_function: str,
|
| 85 |
+
alarm_condition: str
|
| 86 |
+
) -> pd.DataFrame:
|
| 87 |
+
data_points: List[Optional[float]] = list(summary_df[aggregation_function].values)
|
| 88 |
+
|
| 89 |
+
data_table_dict: Dict[str, List[Any]] = {
|
| 90 |
+
"DataPoints": [],
|
| 91 |
+
"# of data points that must be filled": [],
|
| 92 |
+
"MISSING": [],
|
| 93 |
+
"IGNORE": [],
|
| 94 |
+
"BREACHING": [],
|
| 95 |
+
"NOT BREACHING": []
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
def check_condition(value, threshold, condition):
|
| 99 |
+
if condition == '>':
|
| 100 |
+
return value > threshold
|
| 101 |
+
elif condition == '>=':
|
| 102 |
+
return value >= threshold
|
| 103 |
+
elif condition == '<':
|
| 104 |
+
return value < threshold
|
| 105 |
+
elif condition == '<=':
|
| 106 |
+
return value <= threshold
|
| 107 |
+
|
| 108 |
+
for chunk in chunk_list(input_list=data_points, size=evaluation_range):
|
| 109 |
+
data_point_repr: str = ''
|
| 110 |
+
num_dp_that_must_be_filled: int = 0
|
| 111 |
+
|
| 112 |
+
for dp in chunk:
|
| 113 |
+
if dp is None:
|
| 114 |
+
data_point_repr += '-'
|
| 115 |
+
elif check_condition(dp, threshold, alarm_condition):
|
| 116 |
+
data_point_repr += 'X'
|
| 117 |
+
else:
|
| 118 |
+
data_point_repr += '0'
|
| 119 |
+
|
| 120 |
+
if len(chunk) < evaluation_range:
|
| 121 |
+
data_point_repr += '-' * (evaluation_range - len(chunk))
|
| 122 |
+
|
| 123 |
+
if data_point_repr.count('-') > (evaluation_range - datapoints_to_alarm):
|
| 124 |
+
num_dp_that_must_be_filled = datapoints_to_alarm - sum([data_point_repr.count('0'), data_point_repr.count('X')])
|
| 125 |
+
|
| 126 |
+
data_table_dict["DataPoints"].append(data_point_repr)
|
| 127 |
+
data_table_dict["# of data points that must be filled"].append(num_dp_that_must_be_filled)
|
| 128 |
+
|
| 129 |
+
if num_dp_that_must_be_filled > 0:
|
| 130 |
+
data_table_dict["MISSING"].append("INSUFFICIENT_DATA" if data_point_repr.count('-') == evaluation_range else "Retain current state")
|
| 131 |
+
data_table_dict["IGNORE"].append("Retain current state")
|
| 132 |
+
data_table_dict["BREACHING"].append("ALARM")
|
| 133 |
+
data_table_dict["NOT BREACHING"].append("OK")
|
| 134 |
+
else:
|
| 135 |
+
data_table_dict["MISSING"].append("OK")
|
| 136 |
+
data_table_dict["IGNORE"].append("Retain current state")
|
| 137 |
+
data_table_dict["BREACHING"].append("ALARM" if 'X' * datapoints_to_alarm in data_point_repr else "OK")
|
| 138 |
+
data_table_dict["NOT BREACHING"].append("ALARM" if '0' * datapoints_to_alarm not in data_point_repr else "OK")
|
| 139 |
+
|
| 140 |
+
return pd.DataFrame(data_table_dict)
|