Spaces:
Runtime error


Runtime error
Duplicate from fl399/deplot_plus_llm
Browse filesCo-authored-by: Fangyu Liu <fl399@users.noreply.huggingface.co>
- .gitattributes +34 -0
- README.md +14 -0
- app.py +283 -0
- deplot_case_study_3.png +0 -0
- deplot_case_study_4.png +0 -0
- deplot_case_study_5.png +0 -0
- deplot_case_study_6.png +0 -0
- deplot_case_study_m1.png +0 -0
- deplot_case_study_x2.png +0 -0
- requirements.txt +10 -0
.gitattributes
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: DePlot+LLM (multimodal chain-of-thought reasoning on plots)
|
| 3 |
+
emoji: 🏢
|
| 4 |
+
colorFrom: yellow
|
| 5 |
+
colorTo: blue
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 3.23.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
license: mit
|
| 11 |
+
duplicated_from: fl399/deplot_plus_llm
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import openai
|
| 4 |
+
import requests
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import transformers
|
| 7 |
+
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
|
| 8 |
+
from peft import PeftModel
|
| 9 |
+
|
| 10 |
+
## CoT prompts
|
| 11 |
+
|
| 12 |
+
def _add_markup(table):
|
| 13 |
+
try:
|
| 14 |
+
parts = [p.strip() for p in table.splitlines(keepends=False)]
|
| 15 |
+
if parts[0].startswith('TITLE'):
|
| 16 |
+
result = f"Title: {parts[0].split(' | ')[1].strip()}\n"
|
| 17 |
+
rows = parts[1:]
|
| 18 |
+
else:
|
| 19 |
+
result = ''
|
| 20 |
+
rows = parts
|
| 21 |
+
prefixes = ['Header: '] + [f'Row {i+1}: ' for i in range(len(rows) - 1)]
|
| 22 |
+
return result + '\n'.join(prefix + row for prefix, row in zip(prefixes, rows))
|
| 23 |
+
except:
|
| 24 |
+
# just use the raw table if parsing fails
|
| 25 |
+
return table
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
_TABLE = """Year | Democrats | Republicans | Independents
|
| 29 |
+
2004 | 68.1% | 45.0% | 53.0%
|
| 30 |
+
2006 | 58.0% | 42.0% | 53.0%
|
| 31 |
+
2007 | 59.0% | 38.0% | 45.0%
|
| 32 |
+
2009 | 72.0% | 49.0% | 60.0%
|
| 33 |
+
2011 | 71.0% | 51.2% | 58.0%
|
| 34 |
+
2012 | 70.0% | 48.0% | 53.0%
|
| 35 |
+
2013 | 72.0% | 41.0% | 60.0%"""
|
| 36 |
+
|
| 37 |
+
_INSTRUCTION = 'Read the table below to answer the following questions.'
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
_TEMPLATE = f"""First read an example then the complete question for the second table.
|
| 41 |
+
------------
|
| 42 |
+
{_INSTRUCTION}
|
| 43 |
+
{_add_markup(_TABLE)}
|
| 44 |
+
Q: In which year republicans have the lowest favor rate?
|
| 45 |
+
A: Let's find the column of republicans. Then let's extract the favor rates, they [45.0, 42.0, 38.0, 49.0, 51.2, 48.0, 41.0]. The smallest number is 38.0, that's Row 3. Row 3 is year 2007. The answer is 2007.
|
| 46 |
+
Q: What is the sum of Democrats' favor rates of 2004, 2012, and 2013?
|
| 47 |
+
A: Let's find the rows of years 2004, 2012, and 2013. We find Row 1, 6, 7. The favor dates of Demoncrats on that 3 rows are 68.1, 70.0, and 72.0. 68.1+70.0+72=210.1. The answer is 210.1.
|
| 48 |
+
Q: By how many points do Independents surpass Republicans in the year of 2011?
|
| 49 |
+
A: Let's find the row with year = 2011. We find Row 5. We extract Independents and Republicans' numbers. They are 58.0 and 51.2. 58.0-51.2=6.8. The answer is 6.8.
|
| 50 |
+
Q: Which group has the overall worst performance?
|
| 51 |
+
A: Let's sample a couple of years. In Row 1, year 2004, we find Republicans having the lowest favor rate 45.0 (since 45.0<68.1, 45.0<53.0). In year 2006, Row 2, we find Republicans having the lowest favor rate 42.0 (42.0<58.0, 42.0<53.0). The trend continues to other years. The answer is Republicans.
|
| 52 |
+
Q: Which party has the second highest favor rates in 2007?
|
| 53 |
+
A: Let's find the row of year 2007, that's Row 3. Let's extract the numbers on Row 3: [59.0, 38.0, 45.0]. 45.0 is the second highest. 45.0 is the number of Independents. The answer is Independents.
|
| 54 |
+
{_INSTRUCTION}"""
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
## alpaca-lora
|
| 58 |
+
|
| 59 |
+
# debugging...
|
| 60 |
+
assert (
|
| 61 |
+
"LlamaTokenizer" in transformers._import_structure["models.llama"]
|
| 62 |
+
), "LLaMA is now in HuggingFace's main branch.\nPlease reinstall it: pip uninstall transformers && pip install git+https://github.com/huggingface/transformers.git"
|
| 63 |
+
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
|
| 64 |
+
|
| 65 |
+
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
|
| 66 |
+
|
| 67 |
+
BASE_MODEL = "decapoda-research/llama-7b-hf"
|
| 68 |
+
LORA_WEIGHTS = "tloen/alpaca-lora-7b"
|
| 69 |
+
|
| 70 |
+
if torch.cuda.is_available():
|
| 71 |
+
device = "cuda"
|
| 72 |
+
else:
|
| 73 |
+
device = "cpu"
|
| 74 |
+
|
| 75 |
+
try:
|
| 76 |
+
if torch.backends.mps.is_available():
|
| 77 |
+
device = "mps"
|
| 78 |
+
except:
|
| 79 |
+
pass
|
| 80 |
+
|
| 81 |
+
if device == "cuda":
|
| 82 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 83 |
+
BASE_MODEL,
|
| 84 |
+
load_in_8bit=False,
|
| 85 |
+
torch_dtype=torch.float16,
|
| 86 |
+
device_map="auto",
|
| 87 |
+
)
|
| 88 |
+
model = PeftModel.from_pretrained(
|
| 89 |
+
model, LORA_WEIGHTS, torch_dtype=torch.float16, force_download=True
|
| 90 |
+
)
|
| 91 |
+
elif device == "mps":
|
| 92 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 93 |
+
BASE_MODEL,
|
| 94 |
+
device_map={"": device},
|
| 95 |
+
torch_dtype=torch.float16,
|
| 96 |
+
)
|
| 97 |
+
model = PeftModel.from_pretrained(
|
| 98 |
+
model,
|
| 99 |
+
LORA_WEIGHTS,
|
| 100 |
+
device_map={"": device},
|
| 101 |
+
torch_dtype=torch.float16,
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 105 |
+
BASE_MODEL, device_map={"": device}, low_cpu_mem_usage=True
|
| 106 |
+
)
|
| 107 |
+
model = PeftModel.from_pretrained(
|
| 108 |
+
model,
|
| 109 |
+
LORA_WEIGHTS,
|
| 110 |
+
device_map={"": device},
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
if device != "cpu":
|
| 115 |
+
model.half()
|
| 116 |
+
model.eval()
|
| 117 |
+
if torch.__version__ >= "2":
|
| 118 |
+
model = torch.compile(model)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
## FLAN-UL2
|
| 122 |
+
HF_TOKEN = os.environ.get("API_TOKEN", None)
|
| 123 |
+
API_URL = "https://api-inference.huggingface.co/models/google/flan-ul2"
|
| 124 |
+
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
|
| 125 |
+
def query(payload):
|
| 126 |
+
response = requests.post(API_URL, headers=headers, json=payload)
|
| 127 |
+
return response.json()
|
| 128 |
+
|
| 129 |
+
## OpenAI models
|
| 130 |
+
openai.api_key = os.environ.get("OPENAI_TOKEN", None)
|
| 131 |
+
def set_openai_api_key(api_key):
|
| 132 |
+
if api_key and api_key.startswith("sk-") and len(api_key) > 50:
|
| 133 |
+
openai.api_key = api_key
|
| 134 |
+
|
| 135 |
+
def get_response_from_openai(prompt, model="gpt-3.5-turbo", max_output_tokens=256):
|
| 136 |
+
messages = [{"role": "assistant", "content": prompt}]
|
| 137 |
+
response = openai.ChatCompletion.create(
|
| 138 |
+
model=model,
|
| 139 |
+
messages=messages,
|
| 140 |
+
temperature=0.7,
|
| 141 |
+
max_tokens=max_output_tokens,
|
| 142 |
+
top_p=1,
|
| 143 |
+
frequency_penalty=0,
|
| 144 |
+
presence_penalty=0,
|
| 145 |
+
)
|
| 146 |
+
ret = response.choices[0].message['content']
|
| 147 |
+
return ret
|
| 148 |
+
|
| 149 |
+
## deplot models
|
| 150 |
+
model_deplot = Pix2StructForConditionalGeneration.from_pretrained("google/deplot", torch_dtype=torch.bfloat16).to(0)
|
| 151 |
+
processor_deplot = Pix2StructProcessor.from_pretrained("google/deplot")
|
| 152 |
+
|
| 153 |
+
def evaluate(
|
| 154 |
+
table,
|
| 155 |
+
question,
|
| 156 |
+
llm="alpaca-lora",
|
| 157 |
+
input=None,
|
| 158 |
+
temperature=0.1,
|
| 159 |
+
top_p=0.75,
|
| 160 |
+
top_k=40,
|
| 161 |
+
num_beams=4,
|
| 162 |
+
max_new_tokens=128,
|
| 163 |
+
**kwargs,
|
| 164 |
+
):
|
| 165 |
+
prompt_0shot = _INSTRUCTION + "\n" + _add_markup(table) + "\n" + "Q: " + question + "\n" + "A:"
|
| 166 |
+
prompt = _TEMPLATE + "\n" + _add_markup(table) + "\n" + "Q: " + question + "\n" + "A:"
|
| 167 |
+
if llm == "alpaca-lora":
|
| 168 |
+
inputs = tokenizer(prompt, return_tensors="pt")
|
| 169 |
+
input_ids = inputs["input_ids"].to(device)
|
| 170 |
+
generation_config = GenerationConfig(
|
| 171 |
+
temperature=temperature,
|
| 172 |
+
top_p=top_p,
|
| 173 |
+
top_k=top_k,
|
| 174 |
+
num_beams=num_beams,
|
| 175 |
+
**kwargs,
|
| 176 |
+
)
|
| 177 |
+
with torch.no_grad():
|
| 178 |
+
generation_output = model.generate(
|
| 179 |
+
input_ids=input_ids,
|
| 180 |
+
generation_config=generation_config,
|
| 181 |
+
return_dict_in_generate=True,
|
| 182 |
+
output_scores=True,
|
| 183 |
+
max_new_tokens=max_new_tokens,
|
| 184 |
+
)
|
| 185 |
+
s = generation_output.sequences[0]
|
| 186 |
+
output = tokenizer.decode(s)
|
| 187 |
+
elif llm == "flan-ul2":
|
| 188 |
+
output = query({"inputs": prompt_0shot})[0]["generated_text"]
|
| 189 |
+
elif llm == "gpt-3.5-turbo":
|
| 190 |
+
try:
|
| 191 |
+
output = get_response_from_openai(prompt_0shot)
|
| 192 |
+
except:
|
| 193 |
+
output = "<Remember to input your OpenAI API key ☺>"
|
| 194 |
+
else:
|
| 195 |
+
RuntimeError(f"No such LLM: {llm}")
|
| 196 |
+
|
| 197 |
+
return output
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def process_document(image, question, llm):
|
| 201 |
+
# image = Image.open(image)
|
| 202 |
+
inputs = processor_deplot(images=image, text="Generate the underlying data table for the figure below:", return_tensors="pt").to(0, torch.bfloat16)
|
| 203 |
+
predictions = model_deplot.generate(**inputs, max_new_tokens=512)
|
| 204 |
+
table = processor_deplot.decode(predictions[0], skip_special_tokens=True).replace("<0x0A>", "\n")
|
| 205 |
+
|
| 206 |
+
# send prompt+table to LLM
|
| 207 |
+
res = evaluate(table, question, llm=llm)
|
| 208 |
+
if llm == "alpaca-lora":
|
| 209 |
+
return [table, res.split("A:")[-1]]
|
| 210 |
+
else:
|
| 211 |
+
return [table, res]
|
| 212 |
+
|
| 213 |
+
theme = gr.themes.Monochrome(
|
| 214 |
+
primary_hue="indigo",
|
| 215 |
+
secondary_hue="blue",
|
| 216 |
+
neutral_hue="slate",
|
| 217 |
+
radius_size=gr.themes.sizes.radius_sm,
|
| 218 |
+
font=[gr.themes.GoogleFont("Open Sans"), "ui-sans-serif", "system-ui", "sans-serif"],
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
with gr.Blocks(theme=theme) as demo:
|
| 222 |
+
with gr.Column():
|
| 223 |
+
gr.Markdown(
|
| 224 |
+
"""<h1><center>DePlot+LLM: Multimodal chain-of-thought reasoning on plots</center></h1>
|
| 225 |
+
<p>
|
| 226 |
+
This is a demo of DePlot+LLM for QA and summarisation. <a href='https://arxiv.org/abs/2212.10505' target='_blank'>DePlot</a> is an image-to-text model that converts plots and charts into a textual sequence. The sequence then is used to prompt LLM for chain-of-thought reasoning. The current underlying LLMs are <a href='https://huggingface.co/spaces/tloen/alpaca-lora' target='_blank'>alpaca-lora</a>, <a href='https://huggingface.co/google/flan-ul2' target='_blank'>flan-ul2</a>, and <a href='https://openai.com/blog/chatgpt' target='_blank'>gpt-3.5-turbo</a>. To use it, simply upload your image and type a question or instruction and click 'submit', or click one of the examples to load them. Read more at the links below.
|
| 227 |
+
</p>
|
| 228 |
+
"""
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
with gr.Row():
|
| 232 |
+
with gr.Column(scale=2):
|
| 233 |
+
input_image = gr.Image(label="Input Image", type="pil", interactive=True)
|
| 234 |
+
#input_image.style(height=512, width=512)
|
| 235 |
+
instruction = gr.Textbox(placeholder="Enter your instruction/question...", label="Question/Instruction")
|
| 236 |
+
llm = gr.Dropdown(["alpaca-lora", "flan-ul2", "gpt-3.5-turbo"], label="LLM")
|
| 237 |
+
openai_api_key_textbox = gr.Textbox(value='',
|
| 238 |
+
placeholder="Paste your OpenAI API key (sk-...) and hit Enter (if using OpenAI models, otherwise leave empty)",
|
| 239 |
+
show_label=False, lines=1, type='password')
|
| 240 |
+
submit = gr.Button("Submit", variant="primary")
|
| 241 |
+
|
| 242 |
+
with gr.Column(scale=2):
|
| 243 |
+
with gr.Accordion("Show intermediate table", open=False):
|
| 244 |
+
output_table = gr.Textbox(lines=8, label="Intermediate Table")
|
| 245 |
+
output_text = gr.Textbox(lines=8, label="Output")
|
| 246 |
+
|
| 247 |
+
gr.Examples(
|
| 248 |
+
examples=[
|
| 249 |
+
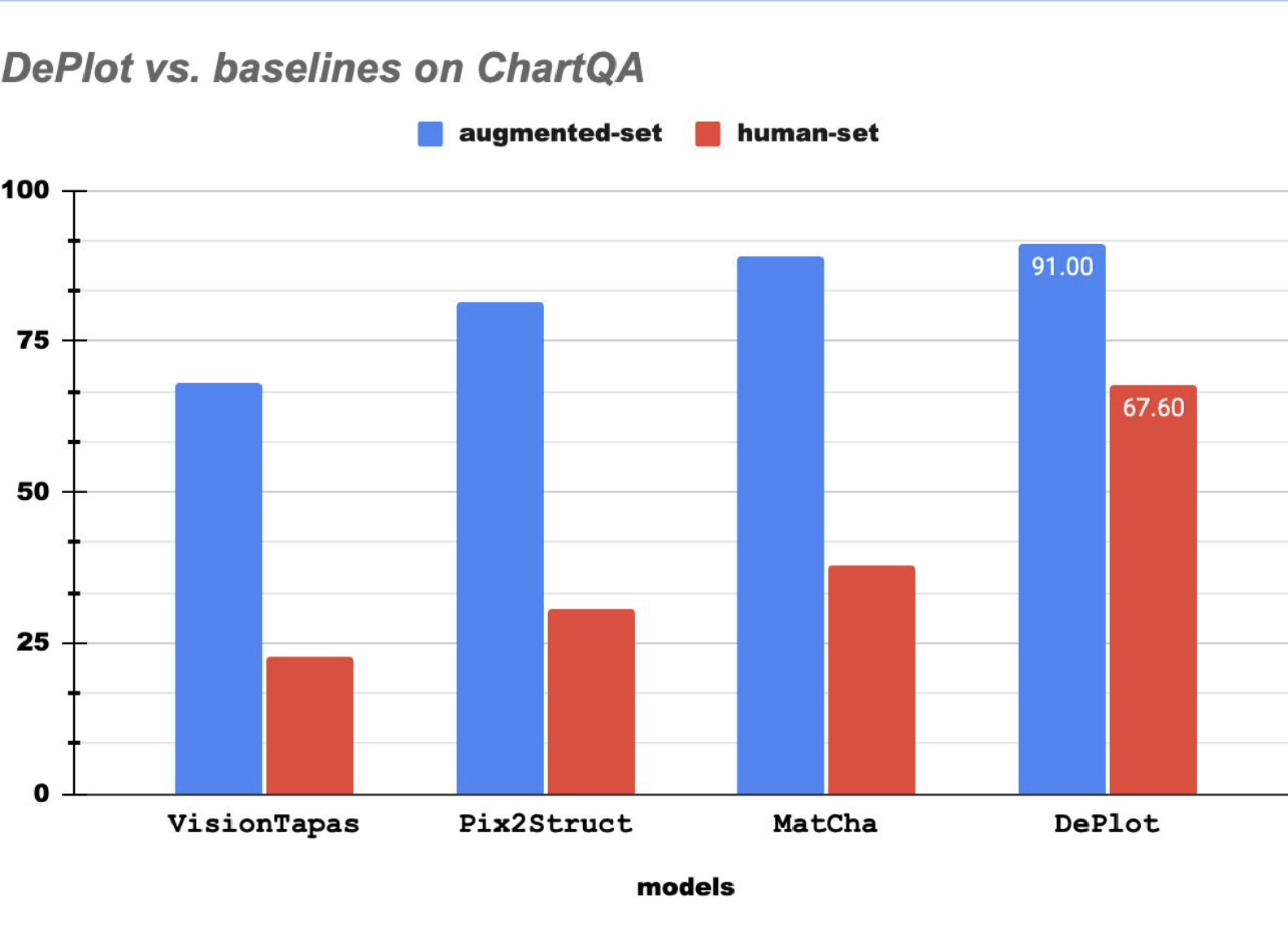
["deplot_case_study_6.png", "Rank the four methods according to model performances. By how much does deplot outperform the second strongest approach on average across the two sets? Show the computation.", "gpt-3.5-turbo"],
|
| 250 |
+
["deplot_case_study_4.png", "What are the acceptance rates? And how does the acceptance change over the years?", "gpt-3.5-turbo"],
|
| 251 |
+
["deplot_case_study_m1.png", "Summarise the chart for me please.", "gpt-3.5-turbo"],
|
| 252 |
+
["deplot_case_study_m1.png", "What is the sum of numbers of Indonesia and Ireland? Remember to think step by step.", "alpaca-lora"],
|
| 253 |
+
["deplot_case_study_3.png", "By how much did China's growth rate drop? Think step by step.", "alpaca-lora"],
|
| 254 |
+
["deplot_case_study_4.png", "How many papers are submitted in 2020?", "flan-ul2"],
|
| 255 |
+
["deplot_case_study_5.png", "Which sales channel has the second highest portion?", "flan-ul2"],
|
| 256 |
+
#["deplot_case_study_x2.png", "Summarise the chart for me please.", "alpaca-lora"],
|
| 257 |
+
#["deplot_case_study_4.png", "How many papers are submitted in 2020?", "alpaca-lora"],
|
| 258 |
+
#["deplot_case_study_m1.png", "Summarise the chart for me please.", "alpaca-lora"],
|
| 259 |
+
#["deplot_case_study_4.png", "acceptance rate = # accepted / #submitted . What is the acceptance rate of 2010?", "flan-ul2"],
|
| 260 |
+
#["deplot_case_study_m1.png", "Summarise the chart for me please.", "flan-ul2"],
|
| 261 |
+
],
|
| 262 |
+
cache_examples=True,
|
| 263 |
+
inputs=[input_image, instruction, llm],
|
| 264 |
+
outputs=[output_table, output_text],
|
| 265 |
+
fn=process_document
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
gr.Markdown(
|
| 269 |
+
"""<p style='text-align: center'><a href='https://arxiv.org/abs/2212.10505' target='_blank'>DePlot: One-shot visual language reasoning by plot-to-table translation</a></p>"""
|
| 270 |
+
)
|
| 271 |
+
openai.api_key = ""
|
| 272 |
+
openai_api_key_textbox.change(set_openai_api_key,
|
| 273 |
+
inputs=[openai_api_key_textbox],
|
| 274 |
+
outputs=[])
|
| 275 |
+
openai_api_key_textbox.submit(set_openai_api_key,
|
| 276 |
+
inputs=[openai_api_key_textbox],
|
| 277 |
+
outputs=[])
|
| 278 |
+
submit.click(process_document, inputs=[input_image, instruction, llm], outputs=[output_table, output_text])
|
| 279 |
+
instruction.submit(
|
| 280 |
+
process_document, inputs=[input_image, instruction, llm], outputs=[output_table, output_text]
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
demo.queue(concurrency_count=1).launch()
|
deplot_case_study_3.png
ADDED

|
deplot_case_study_4.png
ADDED

|
deplot_case_study_5.png
ADDED

|
deplot_case_study_6.png
ADDED
|
deplot_case_study_m1.png
ADDED

|
deplot_case_study_x2.png
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch
|
| 2 |
+
git+https://github.com/huggingface/transformers
|
| 3 |
+
datasets
|
| 4 |
+
loralib
|
| 5 |
+
sentencepiece
|
| 6 |
+
accelerate
|
| 7 |
+
bitsandbytes
|
| 8 |
+
git+https://github.com/huggingface/peft.git
|
| 9 |
+
gradio
|
| 10 |
+
openai
|