diff --git a/.girattributes b/.girattributes
new file mode 100644
index 0000000000000000000000000000000000000000..73a87ef1d20621efd908d00cee926546c8d46157
--- /dev/null
+++ b/.girattributes
@@ -0,0 +1,2 @@
+*.py linguist-language=python
+*.ipynb linguist-documentation
\ No newline at end of file
diff --git a/.github/workflows/ci.yml b/.github/workflows/ci.yml
new file mode 100644
index 0000000000000000000000000000000000000000..02972c9ec3ad607f6180e4a39b40687f7dfaa7ad
--- /dev/null
+++ b/.github/workflows/ci.yml
@@ -0,0 +1,121 @@
+name: Continuous integration
+
+on:
+ push:
+ branches:
+ - main
+ paths-ignore:
+ - '**.md'
+ - 'CITATION.cff'
+ - 'LICENSE'
+ - '.gitignore'
+ - 'docs/**'
+ pull_request:
+ branches:
+ - main
+ paths-ignore:
+ - '**.md'
+ - 'CITATION.cff'
+ - 'LICENSE'
+ - '.gitignore'
+ - 'docs/**'
+ workflow_dispatch:
+ inputs:
+ manual_revision_reference:
+ required: false
+ type: string
+ manual_revision_test:
+ required: false
+ type: string
+
+env:
+ REVISION_REFERENCE: v2.8.2
+ #9d31b2ec4df6d8228f370ff20c8267ec6ba39383 earliest compatible v2.7.0 + pretrained_hf param
+
+jobs:
+ Tests:
+ strategy:
+ matrix:
+ os: [ ubuntu-latest ] #, macos-latest ]
+ python: [ 3.8 ]
+ job_num: [ 4 ]
+ job: [ 1, 2, 3, 4 ]
+ runs-on: ${{ matrix.os }}
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ fetch-depth: 0
+ ref: ${{ inputs.manual_revision_test }}
+ - name: Set up Python ${{ matrix.python }}
+ id: pythonsetup
+ uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python }}
+ - name: Venv cache
+ id: venv-cache
+ uses: actions/cache@v3
+ with:
+ path: .env
+ key: venv-${{ matrix.os }}-${{ steps.pythonsetup.outputs.python-version }}-${{ hashFiles('requirements*') }}
+ - name: Pytest durations cache
+ uses: actions/cache@v3
+ with:
+ path: .test_durations
+ key: test_durations-${{ matrix.os }}-${{ steps.pythonsetup.outputs.python-version }}-${{ matrix.job }}-${{ github.run_id }}
+ restore-keys: test_durations-0-
+ - name: Setup
+ if: steps.venv-cache.outputs.cache-hit != 'true'
+ run: |
+ python3 -m venv .env
+ source .env/bin/activate
+ pip install -e .[test]
+ - name: Prepare test data
+ run: |
+ source .env/bin/activate
+ python -m pytest \
+ --quiet --co \
+ --splitting-algorithm least_duration \
+ --splits ${{ matrix.job_num }} \
+ --group ${{ matrix.job }} \
+ -m regression_test \
+ tests \
+ | head -n -2 | grep -Po 'test_inference_with_data\[\K[^]]*(?=-False]|-True])' \
+ > models_gh_runner.txt
+ if [ -n "${{ inputs.manual_revision_reference }}" ]; then
+ REVISION_REFERENCE=${{ inputs.manual_revision_reference }}
+ fi
+ python tests/util_test.py \
+ --save_model_list models_gh_runner.txt \
+ --model_list models_gh_runner.txt \
+ --git_revision $REVISION_REFERENCE
+ - name: Unit tests
+ run: |
+ source .env/bin/activate
+ if [[ -f .test_durations ]]
+ then
+ cp .test_durations durations_1
+ mv .test_durations durations_2
+ fi
+ python -m pytest \
+ -x -s -v \
+ --splitting-algorithm least_duration \
+ --splits ${{ matrix.job_num }} \
+ --group ${{ matrix.job }} \
+ --store-durations \
+ --durations-path durations_1 \
+ --clean-durations \
+ -m "not regression_test" \
+ tests
+ OPEN_CLIP_TEST_REG_MODELS=models_gh_runner.txt python -m pytest \
+ -x -s -v \
+ --store-durations \
+ --durations-path durations_2 \
+ --clean-durations \
+ -m "regression_test" \
+ tests
+ jq -s -S 'add' durations_* > .test_durations
+ - name: Collect pytest durations
+ uses: actions/upload-artifact@v4
+ with:
+ name: pytest_durations_${{ matrix.os }}-${{ matrix.python }}-${{ matrix.job }}
+ path: .test_durations
diff --git a/.github/workflows/clear-cache.yml b/.github/workflows/clear-cache.yml
new file mode 100644
index 0000000000000000000000000000000000000000..22a1a24618ed339cb429dcce0d6969299fb49cac
--- /dev/null
+++ b/.github/workflows/clear-cache.yml
@@ -0,0 +1,29 @@
+name: Clear cache
+
+on:
+ workflow_dispatch:
+
+permissions:
+ actions: write
+
+jobs:
+ clear-cache:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Clear cache
+ uses: actions/github-script@v6
+ with:
+ script: |
+ const caches = await github.rest.actions.getActionsCacheList({
+ owner: context.repo.owner,
+ repo: context.repo.repo,
+ })
+ for (const cache of caches.data.actions_caches) {
+ console.log(cache)
+ await github.rest.actions.deleteActionsCacheById({
+ owner: context.repo.owner,
+ repo: context.repo.repo,
+ cache_id: cache.id,
+ })
+ }
+
diff --git a/.github/workflows/python-publish.yml b/.github/workflows/python-publish.yml
new file mode 100644
index 0000000000000000000000000000000000000000..017ba074c537281d3158a373cfa305acbb736289
--- /dev/null
+++ b/.github/workflows/python-publish.yml
@@ -0,0 +1,37 @@
+name: Release
+
+on:
+ push:
+ branches:
+ - main
+jobs:
+ deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - uses: actions-ecosystem/action-regex-match@v2
+ id: regex-match
+ with:
+ text: ${{ github.event.head_commit.message }}
+ regex: '^Release ([^ ]+)'
+ - name: Set up Python
+ uses: actions/setup-python@v2
+ with:
+ python-version: '3.8'
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install setuptools wheel twine build
+ - name: Release
+ if: ${{ steps.regex-match.outputs.match != '' }}
+ uses: softprops/action-gh-release@v1
+ with:
+ tag_name: v${{ steps.regex-match.outputs.group1 }}
+ - name: Build and publish
+ if: ${{ steps.regex-match.outputs.match != '' }}
+ env:
+ TWINE_USERNAME: __token__
+ TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
+ run: |
+ python -m build
+ twine upload dist/*
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..b880054ba3f8ad032b6fc110921e0772b2877cd9
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,153 @@
+**/logs/
+**/wandb/
+models/
+features/
+results/
+
+tests/data/
+*.pt
+
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
+sync.sh
+gpu1sync.sh
+.idea
+*.pdf
+**/._*
+**/*DS_*
+**.jsonl
+src/sbatch
+src/misc
+.vscode
+src/debug
+core.*
+
+# Allow
+!src/evaluation/misc/results_dbs/*
\ No newline at end of file
diff --git a/CITATION.cff b/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..1072ddd3a6065bbf88346c2c1d6ce7681363fab8
--- /dev/null
+++ b/CITATION.cff
@@ -0,0 +1,33 @@
+cff-version: 1.1.0
+message: If you use this software, please cite it as below.
+authors:
+ - family-names: Ilharco
+ given-names: Gabriel
+ - family-names: Wortsman
+ given-names: Mitchell
+ - family-names: Wightman
+ given-names: Ross
+ - family-names: Gordon
+ given-names: Cade
+ - family-names: Carlini
+ given-names: Nicholas
+ - family-names: Taori
+ given-names: Rohan
+ - family-names: Dave
+ given-names: Achal
+ - family-names: Shankar
+ given-names: Vaishaal
+ - family-names: Namkoong
+ given-names: Hongseok
+ - family-names: Miller
+ given-names: John
+ - family-names: Hajishirzi
+ given-names: Hannaneh
+ - family-names: Farhadi
+ given-names: Ali
+ - family-names: Schmidt
+ given-names: Ludwig
+title: OpenCLIP
+version: v0.1
+doi: 10.5281/zenodo.5143773
+date-released: 2021-07-28
diff --git a/HISTORY.md b/HISTORY.md
new file mode 100644
index 0000000000000000000000000000000000000000..329452ddd172ba70aa713818b4e4001653840ba8
--- /dev/null
+++ b/HISTORY.md
@@ -0,0 +1,223 @@
+## 2.24.0
+
+* Fix missing space in error message
+* use model flag for normalizing embeddings
+* init logit_bias for non siglip pretrained models
+* Fix logit_bias load_checkpoint addition
+* Make CoCa model match CLIP models for logit scale/bias init
+* Fix missing return of "logit_bias" in CoCa.forward
+* Add NLLB-CLIP with SigLIP models
+* Add get_logits method and NLLB tokenizer
+* Remove the empty file src/open_clip/generation_utils.py
+* Update params.py: "BatchNorm" -> "LayerNorm" in the description string for "--lock-text-freeze-layer-norm"
+
+## 2.23.0
+
+* Add CLIPA-v2 models
+* Add SigLIP models
+* Add MetaCLIP models
+* Add NLLB-CLIP models
+* CLIPA train code
+* Minor changes/fixes
+ * Remove protobuf version limit
+ * Stop checking model name when loading CoCa models
+ * Log native wandb step
+ * Use bool instead of long masks
+
+## 2.21.0
+
+* Add SigLIP loss + training support
+* Add more DataComp models (B/16, B/32 and B/32@256)
+* Update default num workers
+* Update CoCa generation for `transformers>=4.31`
+* PyTorch 2.0 `state_dict()` compatibility fix for compiled models
+* Fix padding in `ResizeMaxSize`
+* Convert JIT model on state dict load for `pretrained='filename…'`
+* Other minor changes and fixes (typos, README, dependencies, CI)
+
+## 2.20.0
+
+* Add EVA models
+* Support serial worker training
+* Fix Python 3.7 compatibility
+
+## 2.19.0
+
+* Add DataComp models
+
+## 2.18.0
+
+* Enable int8 inference without `.weight` attribute
+
+## 2.17.2
+
+* Update push_to_hf_hub
+
+## 2.17.0
+
+* Add int8 support
+* Update notebook demo
+* Refactor zero-shot classification code
+
+## 2.16.2
+
+* Fixes for context_length and vocab_size attributes
+
+## 2.16.1
+
+* Fixes for context_length and vocab_size attributes
+* Fix --train-num-samples logic
+* Add HF BERT configs for PubMed CLIP model
+
+## 2.16.0
+
+* Add improved g-14 weights
+* Update protobuf version
+
+## 2.15.0
+
+* Add convnext_xxlarge weights
+* Fixed import in readme
+* Add samples per second per gpu logging
+* Fix slurm example
+
+## 2.14.0
+
+* Move dataset mixtures logic to shard level
+* Fix CoCa accum-grad training
+* Safer transformers import guard
+* get_labels refactoring
+
+## 2.13.0
+
+* Add support for dataset mixtures with different sampling weights
+* Make transformers optional again
+
+## 2.12.0
+
+* Updated convnext configs for consistency
+* Added input_patchnorm option
+* Clean and improve CoCa generation
+* Support model distillation
+* Add ConvNeXt-Large 320x320 fine-tune weights
+
+## 2.11.1
+
+* Make transformers optional
+* Add MSCOCO CoCa finetunes to pretrained models
+
+## 2.11.0
+
+* coca support and weights
+* ConvNeXt-Large weights
+
+## 2.10.1
+
+* `hf-hub:org/model_id` support for loading models w/ config and weights in Hugging Face Hub
+
+## 2.10.0
+
+* Added a ViT-bigG-14 model.
+* Added an up-to-date example slurm script for large training jobs.
+* Added a option to sync logs and checkpoints to S3 during training.
+* New options for LR schedulers, constant and constant with cooldown
+* Fix wandb autoresuming when resume is not set
+* ConvNeXt `base` & `base_w` pretrained models added
+* `timm-` model prefix removed from configs
+* `timm` augmentation + regularization (dropout / drop-path) supported
+
+## 2.9.3
+
+* Fix wandb collapsing multiple parallel runs into a single one
+
+## 2.9.2
+
+* Fix braceexpand memory explosion for complex webdataset urls
+
+## 2.9.1
+
+* Fix release
+
+## 2.9.0
+
+* Add training feature to auto-resume from the latest checkpoint on restart via `--resume latest`
+* Allow webp in webdataset
+* Fix logging for number of samples when using gradient accumulation
+* Add model configs for convnext xxlarge
+
+## 2.8.2
+
+* wrapped patchdropout in a torch.nn.Module
+
+## 2.8.1
+
+* relax protobuf dependency
+* override the default patch dropout value in 'vision_cfg'
+
+## 2.8.0
+
+* better support for HF models
+* add support for gradient accumulation
+* CI fixes
+* add support for patch dropout
+* add convnext configs
+
+
+## 2.7.0
+
+* add multilingual H/14 xlm roberta large
+
+## 2.6.1
+
+* fix setup.py _read_reqs
+
+## 2.6.0
+
+* Make openclip training usable from pypi.
+* Add xlm roberta large vit h 14 config.
+
+## 2.5.0
+
+* pretrained B/32 xlm roberta base: first multilingual clip trained on laion5B
+* pretrained B/32 roberta base: first clip trained using an HF text encoder
+
+## 2.4.1
+
+* Add missing hf_tokenizer_name in CLIPTextCfg.
+
+## 2.4.0
+
+* Fix #211, missing RN50x64 config. Fix type of dropout param for ResNet models
+* Bring back LayerNorm impl that casts to input for non bf16/fp16
+* zero_shot.py: set correct tokenizer based on args
+* training/params.py: remove hf params and get them from model config
+
+## 2.3.1
+
+* Implement grad checkpointing for hf model.
+* custom_text: True if hf_model_name is set
+* Disable hf tokenizer parallelism
+
+## 2.3.0
+
+* Generalizable Text Transformer with HuggingFace Models (@iejMac)
+
+## 2.2.0
+
+* Support for custom text tower
+* Add checksum verification for pretrained model weights
+
+## 2.1.0
+
+* lot including sota models, bfloat16 option, better loading, better metrics
+
+## 1.2.0
+
+* ViT-B/32 trained on Laion2B-en
+* add missing openai RN50x64 model
+
+## 1.1.1
+
+* ViT-B/16+
+* Add grad checkpointing support
+* more robust data loader
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..5bfbf6c09daad743dbf9a98d303c0402e4099a27
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,23 @@
+Copyright (c) 2012-2021 Gabriel Ilharco, Mitchell Wortsman,
+Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar,
+John Miller, Hongseok Namkoong, Hannaneh Hajishirzi, Ali Farhadi,
+Ludwig Schmidt
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..c74de18e62cf8fe3b8fa777195f7d38c90b13380
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,3 @@
+include src/open_clip/bpe_simple_vocab_16e6.txt.gz
+include src/open_clip/model_configs/*.json
+
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a46954bba4e8f9ee0e2c944082688110b0a66f11
--- /dev/null
+++ b/README.md
@@ -0,0 +1,618 @@
+# OpenCLIP
+
+[[Paper]](https://arxiv.org/abs/2212.07143) [[Citations]](#citing) [[Clip Colab]](https://colab.research.google.com/github/mlfoundations/open_clip/blob/master/docs/Interacting_with_open_clip.ipynb) [[Coca Colab]](https://colab.research.google.com/github/mlfoundations/open_clip/blob/master/docs/Interacting_with_open_coca.ipynb)
+[](https://pypi.python.org/pypi/open_clip_torch)
+
+Welcome to an open source implementation of OpenAI's [CLIP](https://arxiv.org/abs/2103.00020) (Contrastive Language-Image Pre-training).
+
+Using this codebase, we have trained several models on a variety of data sources and compute budgets, ranging from [small-scale experiments](docs/LOW_ACC.md) to larger runs including models trained on datasets such as [LAION-400M](https://arxiv.org/abs/2111.02114), [LAION-2B](https://arxiv.org/abs/2210.08402) and [DataComp-1B](https://arxiv.org/abs/2304.14108).
+Many of our models and their scaling properties are studied in detail in the paper [reproducible scaling laws for contrastive language-image learning](https://arxiv.org/abs/2212.07143).
+Some of the best models we've trained and their zero-shot ImageNet-1k accuracy are shown below, along with the ViT-L model trained by OpenAI and other state-of-the-art open source alternatives (all can be loaded via OpenCLIP).
+We provide more details about our full collection of pretrained models [here](docs/PRETRAINED.md), and zero-shot results for 38 datasets [here](docs/openclip_results.csv).
+
+
+
+| Model | Training data | Resolution | # of samples seen | ImageNet zero-shot acc. |
+| -------- | ------- | ------- | ------- | ------- |
+| ConvNext-Base | LAION-2B | 256px | 13B | 71.5% |
+| ConvNext-Large | LAION-2B | 320px | 29B | 76.9% |
+| ConvNext-XXLarge | LAION-2B | 256px | 34B | 79.5% |
+| ViT-B/32 | DataComp-1B | 256px | 34B | 72.8% |
+| ViT-B/16 | DataComp-1B | 224px | 13B | 73.5% |
+| ViT-L/14 | LAION-2B | 224px | 32B | 75.3% |
+| ViT-H/14 | LAION-2B | 224px | 32B | 78.0% |
+| ViT-L/14 | DataComp-1B | 224px | 13B | 79.2% |
+| ViT-G/14 | LAION-2B | 224px | 34B | 80.1% |
+| | | | | |
+| ViT-L/14-quickgelu [(Original CLIP)](https://arxiv.org/abs/2103.00020) | WIT | 224px | 13B | 75.5% |
+| ViT-SO400M/14 [(SigLIP)](https://arxiv.org/abs/2303.15343) | WebLI | 224px | 45B | 82.0% |
+| ViT-L/14 [(DFN)](https://arxiv.org/abs/2309.17425) | DFN-2B | 224px | 39B | 82.2% |
+| ViT-SO400M-14-SigLIP-384 [(SigLIP)](https://arxiv.org/abs/2303.15343) | WebLI | 384px | 45B | 83.1% |
+| ViT-H/14-quickgelu [(DFN)](https://arxiv.org/abs/2309.17425) | DFN-5B | 224px | 39B | 83.4% |
+| ViT-H-14-378-quickgelu [(DFN)](https://arxiv.org/abs/2309.17425) | DFN-5B | 378px | 44B | 84.4% |
+
+Model cards with additional model specific details can be found on the Hugging Face Hub under the OpenCLIP library tag: https://huggingface.co/models?library=open_clip.
+
+If you found this repository useful, please consider [citing](#citing).
+We welcome anyone to submit an issue or send an email if you have any other requests or suggestions.
+
+Note that portions of `src/open_clip/` modelling and tokenizer code are adaptations of OpenAI's official [repository](https://github.com/openai/CLIP).
+
+## Approach
+
+|  |
+|:--:|
+| Image Credit: https://github.com/openai/CLIP |
+
+## Usage
+
+```
+pip install open_clip_torch
+```
+
+```python
+import torch
+from PIL import Image
+import open_clip
+
+model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
+model.eval() # model in train mode by default, impacts some models with BatchNorm or stochastic depth active
+tokenizer = open_clip.get_tokenizer('ViT-B-32')
+
+image = preprocess(Image.open("docs/CLIP.png")).unsqueeze(0)
+text = tokenizer(["a diagram", "a dog", "a cat"])
+
+with torch.no_grad(), torch.autocast("cuda"):
+ image_features = model.encode_image(image)
+ text_features = model.encode_text(text)
+ image_features /= image_features.norm(dim=-1, keepdim=True)
+ text_features /= text_features.norm(dim=-1, keepdim=True)
+
+ text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
+
+print("Label probs:", text_probs) # prints: [[1., 0., 0.]]
+```
+
+If model uses `timm` image encoders (convnext, siglip, eva, etc) ensure the latest timm is installed. Upgrade `timm` if you see 'Unknown model' errors for the image encoder.
+
+If model uses transformers tokenizers, ensure `transformers` is installed.
+
+See also this [[Clip Colab]](https://colab.research.google.com/github/mlfoundations/open_clip/blob/master/docs/Interacting_with_open_clip.ipynb).
+
+To compute billions of embeddings efficiently, you can use [clip-retrieval](https://github.com/rom1504/clip-retrieval) which has openclip support.
+
+### Pretrained models
+
+We offer a simple model interface to instantiate both pre-trained and untrained models.
+To see which pretrained models are available, use the following code snippet.
+More details about our pretrained models are available [here](docs/PRETRAINED.md).
+
+```python
+>>> import open_clip
+>>> open_clip.list_pretrained()
+```
+
+You can find more about the models we support (e.g. number of parameters, FLOPs) in [this table](docs/model_profile.csv).
+
+NOTE: Many existing checkpoints use the QuickGELU activation from the original OpenAI models. This activation is actually less efficient than native torch.nn.GELU in recent versions of PyTorch. The model defaults are now nn.GELU, so one should use model definitions with `-quickgelu` postfix for the OpenCLIP pretrained weights. All OpenAI pretrained weights will always default to QuickGELU. One can also use the non `-quickgelu` model definitions with pretrained weights using QuickGELU but there will be an accuracy drop, for fine-tune that will likely vanish for longer runs.
+Future trained models will use nn.GELU.
+
+### Loading models
+
+Models can be loaded with `open_clip.create_model_and_transforms`, as shown in the example below. The model name and corresponding `pretrained` keys are compatible with the outputs of `open_clip.list_pretrained()`.
+
+The `pretrained` argument also accepts local paths, for example `/path/to/my/b32.pt`.
+You can also load checkpoints from huggingface this way. To do so, download the `open_clip_pytorch_model.bin` file (for example, [https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K/tree/main](https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K/blob/main/open_clip_pytorch_model.bin)), and use `pretrained=/path/to/open_clip_pytorch_model.bin`.
+
+```python
+# pretrained also accepts local paths
+model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')
+```
+
+## Fine-tuning on classification tasks
+
+This repository is focused on training CLIP models. To fine-tune a *trained* zero-shot model on a downstream classification task such as ImageNet, please see [our other repository: WiSE-FT](https://github.com/mlfoundations/wise-ft). The [WiSE-FT repository](https://github.com/mlfoundations/wise-ft) contains code for our paper on [Robust Fine-tuning of Zero-shot Models](https://arxiv.org/abs/2109.01903), in which we introduce a technique for fine-tuning zero-shot models while preserving robustness under distribution shift.
+
+## Data
+
+To download datasets as webdataset, we recommend [img2dataset](https://github.com/rom1504/img2dataset).
+
+### Conceptual Captions
+
+See [cc3m img2dataset example](https://github.com/rom1504/img2dataset/blob/main/dataset_examples/cc3m.md).
+
+### YFCC and other datasets
+
+In addition to specifying the training data via CSV files as mentioned above, our codebase also supports [webdataset](https://github.com/webdataset/webdataset), which is recommended for larger scale datasets. The expected format is a series of `.tar` files. Each of these `.tar` files should contain two files for each training example, one for the image and one for the corresponding text. Both files should have the same name but different extensions. For instance, `shard_001.tar` could contain files such as `abc.jpg` and `abc.txt`. You can learn more about `webdataset` at [https://github.com/webdataset/webdataset](https://github.com/webdataset/webdataset). We use `.tar` files with 1,000 data points each, which we create using [tarp](https://github.com/webdataset/tarp).
+
+You can download the YFCC dataset from [Multimedia Commons](http://mmcommons.org/).
+Similar to OpenAI, we used a subset of YFCC to reach the aforementioned accuracy numbers.
+The indices of images in this subset are in [OpenAI's CLIP repository](https://github.com/openai/CLIP/blob/main/data/yfcc100m.md).
+
+
+## Training CLIP
+
+### Install
+
+We advise you first create a virtual environment with:
+
+```
+python3 -m venv .env
+source .env/bin/activate
+pip install -U pip
+```
+
+You can then install openclip for training with `pip install 'open_clip_torch[training]'`.
+
+#### Development
+
+If you want to make changes to contribute code, you can clone openclip then run `make install` in openclip folder (after creating a virtualenv)
+
+Install pip PyTorch as per https://pytorch.org/get-started/locally/
+
+You may run `make install-training` to install training deps
+
+#### Testing
+
+Test can be run with `make install-test` then `make test`
+
+`python -m pytest -x -s -v tests -k "training"` to run a specific test
+
+Running regression tests against a specific git revision or tag:
+1. Generate testing data
+ ```sh
+ python tests/util_test.py --model RN50 RN101 --save_model_list models.txt --git_revision 9d31b2ec4df6d8228f370ff20c8267ec6ba39383
+ ```
+ **_WARNING_: This will invoke git and modify your working tree, but will reset it to the current state after data has been generated! \
+ Don't modify your working tree while test data is being generated this way.**
+
+2. Run regression tests
+ ```sh
+ OPEN_CLIP_TEST_REG_MODELS=models.txt python -m pytest -x -s -v -m regression_test
+ ```
+
+### Sample single-process running code:
+
+```bash
+python -m open_clip_train.main \
+ --save-frequency 1 \
+ --zeroshot-frequency 1 \
+ --report-to tensorboard \
+ --train-data="/path/to/train_data.csv" \
+ --val-data="/path/to/validation_data.csv" \
+ --csv-img-key filepath \
+ --csv-caption-key title \
+ --imagenet-val=/path/to/imagenet/root/val/ \
+ --warmup 10000 \
+ --batch-size=128 \
+ --lr=1e-3 \
+ --wd=0.1 \
+ --epochs=30 \
+ --workers=8 \
+ --model RN50
+```
+
+Note: `imagenet-val` is the path to the *validation* set of ImageNet for zero-shot evaluation, not the training set!
+You can remove this argument if you do not want to perform zero-shot evaluation on ImageNet throughout training. Note that the `val` folder should contain subfolders. If it does not, please use [this script](https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh).
+
+### Multi-GPU and Beyond
+
+This code has been battle tested up to 1024 A100s and offers a variety of solutions
+for distributed training. We include native support for SLURM clusters.
+
+As the number of devices used to train increases, so does the space complexity of
+the the logit matrix. Using a naïve all-gather scheme, space complexity will be
+`O(n^2)`. Instead, complexity may become effectively linear if the flags
+`--gather-with-grad` and `--local-loss` are used. This alteration results in one-to-one
+numerical results as the naïve method.
+
+#### Epochs
+
+For larger datasets (eg Laion2B), we recommend setting `--train-num-samples` to a lower value than the full epoch, for example `--train-num-samples 135646078` to 1/16 of an epoch in conjunction with `--dataset-resampled` to do sampling with replacement. This allows having frequent checkpoints to evaluate more often.
+
+#### Patch Dropout
+
+Recent research has shown that one can dropout half to three-quarters of the visual tokens, leading to up to 2-3x training speeds without loss of accuracy.
+
+You can set this on your visual transformer config with the key `patch_dropout`.
+
+In the paper, they also finetuned without the patch dropout at the end. You can do this with the command-line argument `--force-patch-dropout 0.`
+
+#### Multiple data sources
+
+OpenCLIP supports using multiple data sources, by separating different data paths with `::`.
+For instance, to train on CC12M and on LAION, one might use `--train-data "/data/cc12m/cc12m-train-{0000..2175}.tar::/data/LAION-400M/{00000..41455}.tar"`.
+Using `--dataset-resampled` is recommended for these cases.
+
+By default, on expectation the amount of times the model will see a sample from each source is proportional to the size of the source.
+For instance, when training on one data source with size 400M and one with size 10M, samples from the first source are 40x more likely to be seen in expectation.
+
+We also support different weighting of the data sources, by using the `--train-data-upsampling-factors` flag.
+For instance, using `--train-data-upsampling-factors=1::1` in the above scenario is equivalent to not using the flag, and `--train-data-upsampling-factors=1::2` is equivalent to upsampling the second data source twice.
+If you want to sample from data sources with the same frequency, the upsampling factors should be inversely proportional to the sizes of the data sources.
+For instance, if dataset `A` has 1000 samples and dataset `B` has 100 samples, you can use `--train-data-upsampling-factors=0.001::0.01` (or analogously, `--train-data-upsampling-factors=1::10`).
+
+#### Single-Node
+
+We make use of `torchrun` to launch distributed jobs. The following launches a
+a job on a node of 4 GPUs:
+
+```bash
+cd open_clip/src
+torchrun --nproc_per_node 4 -m open_clip_train.main \
+ --train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
+ --train-num-samples 10968539 \
+ --dataset-type webdataset \
+ --batch-size 320 \
+ --precision amp \
+ --workers 4 \
+ --imagenet-val /data/imagenet/validation/
+```
+
+#### Multi-Node
+
+The same script above works, so long as users include information about the number
+of nodes and host node.
+
+```bash
+cd open_clip/src
+torchrun --nproc_per_node=4 \
+ --rdzv_endpoint=$HOSTE_NODE_ADDR \
+ -m open_clip_train.main \
+ --train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
+ --train-num-samples 10968539 \
+ --dataset-type webdataset \
+ --batch-size 320 \
+ --precision amp \
+ --workers 4 \
+ --imagenet-val /data/imagenet/validation/
+```
+
+#### SLURM
+
+This is likely the easiest solution to utilize. The following script was used to
+train our largest models:
+
+```bash
+#!/bin/bash -x
+#SBATCH --nodes=32
+#SBATCH --gres=gpu:4
+#SBATCH --ntasks-per-node=4
+#SBATCH --cpus-per-task=6
+#SBATCH --wait-all-nodes=1
+#SBATCH --job-name=open_clip
+#SBATCH --account=ACCOUNT_NAME
+#SBATCH --partition PARTITION_NAME
+
+eval "$(/path/to/conda/bin/conda shell.bash hook)" # init conda
+conda activate open_clip
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+export MASTER_PORT=12802
+
+master_addr=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
+export MASTER_ADDR=$master_addr
+
+cd /shared/open_clip
+export PYTHONPATH="$PYTHONPATH:$PWD/src"
+srun --cpu_bind=v --accel-bind=gn python -u src/open_clip_train/main.py \
+ --save-frequency 1 \
+ --report-to tensorboard \
+ --train-data="/data/LAION-400M/{00000..41455}.tar" \
+ --warmup 2000 \
+ --batch-size=256 \
+ --epochs=32 \
+ --workers=8 \
+ --model ViT-B-32 \
+ --name "ViT-B-32-Vanilla" \
+ --seed 0 \
+ --local-loss \
+ --gather-with-grad
+```
+
+### Resuming from a checkpoint:
+
+```bash
+python -m open_clip_train.main \
+ --train-data="/path/to/train_data.csv" \
+ --val-data="/path/to/validation_data.csv" \
+ --resume /path/to/checkpoints/epoch_K.pt
+```
+
+### Training CoCa:
+Training [CoCa](https://arxiv.org/abs/2205.01917) models is enabled through specifying a CoCa config using the ```--model``` parameter of the training script. Currently available configs are "coca_base", "coca_ViT-B-32", and "coca_roberta-ViT-B-32" (which uses RoBERTa as the text encoder). CoCa configs are different from CLIP configs because they have an additional "multimodal_cfg" component which specifies parameters for the multimodal text decoder. Here's an example from the coca_ViT-B-32 config:
+```json
+"multimodal_cfg": {
+ "context_length": 76,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "latent_dim": 512,
+ "attn_pooler_heads": 8
+}
+```
+Credit to [lucidrains](https://github.com/lucidrains) for [initial code](https://github.com/lucidrains/CoCa-pytorch), [gpucce](https://github.com/gpucce) for adapting the code to open_clip, and [iejMac](https://github.com/iejMac) for training the models.
+
+### Generating text with CoCa
+
+```python
+import open_clip
+import torch
+from PIL import Image
+
+model, _, transform = open_clip.create_model_and_transforms(
+ model_name="coca_ViT-L-14",
+ pretrained="mscoco_finetuned_laion2B-s13B-b90k"
+)
+
+im = Image.open("cat.jpg").convert("RGB")
+im = transform(im).unsqueeze(0)
+
+with torch.no_grad(), torch.cuda.amp.autocast():
+ generated = model.generate(im)
+
+print(open_clip.decode(generated[0]).split("")[0].replace("", ""))
+```
+
+See also this [[Coca Colab]](https://colab.research.google.com/github/mlfoundations/open_clip/blob/master/docs/Interacting_with_open_coca.ipynb)
+
+### Fine Tuning CoCa
+
+To fine-tune coca on mscoco, first create the dataset, one way is using a csvdataset and perhaps the simplest way to do it is using [CLIP_benchmark](https://github.com/LAION-AI/CLIP_benchmark) which in turn uses [pycocotools](https://github.com/cocodataset/cocoapi) (that can be used also by itself).
+
+```python
+from clip_benchmark.datasets.builder import build_dataset
+import pandas as pd
+import os
+
+root_path = "path/to/data/dir" # set this to smth meaningful
+ds = build_dataset("mscoco_captions", root=root_path, split="train", task="captioning") # this downloads the dataset if it is not there already
+coco = ds.coco
+imgs = coco.loadImgs(coco.getImgIds())
+future_df = {"filepath":[], "title":[]}
+for img in imgs:
+ caps = coco.imgToAnns[img["id"]]
+ for cap in caps:
+ future_df["filepath"].append(img["file_name"])
+ future_df["title"].append(cap["caption"])
+pd.DataFrame.from_dict(future_df).to_csv(
+ os.path.join(root_path, "train2014.csv"), index=False, sep="\t"
+)
+```
+This should create a csv dataset that one can use to fine-tune coca with open_clip
+```bash
+python -m open_clip_train.main \
+ --dataset-type "csv" \
+ --train-data "path/to/data/dir/train2014.csv" \
+ --warmup 1000 \
+ --batch-size 128 \
+ --lr 1e-5 \
+ --wd 0.1 \
+ --epochs 1 \
+ --workers 3 \
+ --model "coca_ViT-L-14" \
+ --report-to "wandb" \
+ --coca-contrastive-loss-weight 0 \
+ --coca-caption-loss-weight 1 \
+ --log-every-n-steps 100
+```
+
+This is a general setting, open_clip has very parameters that can be set, ```python -m open_clip_train.main --help``` should show them. The only relevant change compared to pre-training are the two arguments
+
+```bash
+--coca-contrastive-loss-weight 0
+--coca-caption-loss-weight 1
+```
+which make the model only train the generative side.
+
+### Training with pre-trained language models as text encoder:
+
+If you wish to use different language models as the text encoder for CLIP you can do so by using one of the Hugging Face model configs in ```src/open_clip/model_configs``` and passing in it's tokenizer as the ```--model``` and ```--hf-tokenizer-name``` parameters respectively. Currently we only support RoBERTa ("test-roberta" config), however adding new models should be trivial. You can also determine how many layers, from the end, to leave unfrozen with the ```--lock-text-unlocked-layers``` parameter. Here's an example command to train CLIP with the RoBERTa LM that has it's last 10 layers unfrozen:
+```bash
+python -m open_clip_train.main \
+ --train-data="pipe:aws s3 cp s3://s-mas/cc3m/{00000..00329}.tar -" \
+ --train-num-samples 3000000 \
+ --val-data="pipe:aws s3 cp s3://s-mas/cc3m/{00330..00331}.tar -" \
+ --val-num-samples 10000 \
+ --dataset-type webdataset \
+ --batch-size 256 \
+ --warmup 2000 \
+ --epochs 10 \
+ --lr 5e-4 \
+ --precision amp \
+ --workers 6 \
+ --model "roberta-ViT-B-32" \
+ --lock-text \
+ --lock-text-unlocked-layers 10 \
+ --name "10_unfrozen" \
+ --report-to "tensorboard" \
+```
+
+### Loss Curves
+
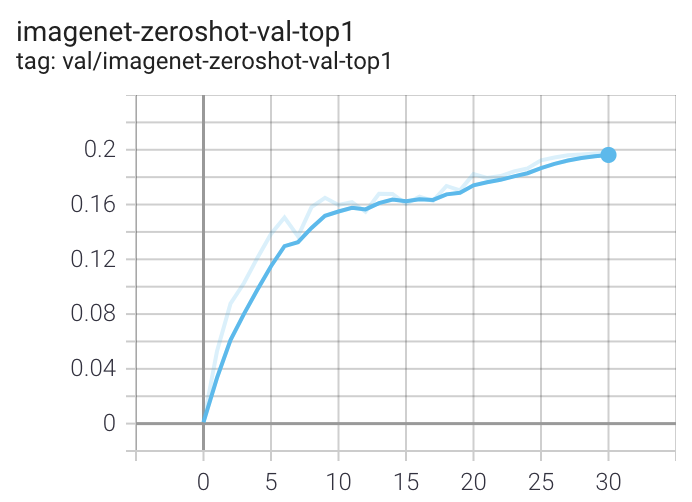
+When run on a machine with 8 GPUs the command should produce the following training curve for Conceptual Captions:
+
+
+
+More detailed curves for Conceptual Captions are given at [/docs/clip_conceptual_captions.md](/docs/clip_conceptual_captions.md).
+
+When training a RN50 on YFCC the same hyperparameters as above are used, with the exception of `lr=5e-4` and `epochs=32`.
+
+Note that to use another model, like `ViT-B/32` or `RN50x4` or `RN50x16` or `ViT-B/16`, specify with `--model RN50x4`.
+
+### Logging
+
+For tensorboard logging, run:
+```bash
+tensorboard --logdir=logs/tensorboard/ --port=7777
+```
+
+For wandb logging, we recommend looking at the `step` variable instead of `Step`, since the later was not properly set in earlier versions of this codebase.
+For older runs with models trained before https://github.com/mlfoundations/open_clip/pull/613, the `Step` variable should be ignored.
+For newer runs, after that PR, the two variables are the same.
+
+## Evaluation / Zero-Shot
+
+We recommend https://github.com/LAION-AI/CLIP_benchmark#how-to-use for systematic evaluation on 40 datasets.
+
+### Evaluating local checkpoint:
+
+```bash
+python -m open_clip_train.main \
+ --val-data="/path/to/validation_data.csv" \
+ --model RN101 \
+ --pretrained /path/to/checkpoints/epoch_K.pt
+```
+
+### Evaluating hosted pretrained checkpoint on ImageNet zero-shot prediction:
+
+```bash
+python -m open_clip_train.main \
+ --imagenet-val /path/to/imagenet/validation \
+ --model ViT-B-32-quickgelu \
+ --pretrained laion400m_e32
+```
+
+### Model distillation
+
+You can distill from a pre-trained by using `--distill-model` and `--distill-pretrained` to specify the model you'd like to distill from.
+For instance, to distill from OpenAI ViT-L/14 use `--distill-model ViT-L-14 --distill-pretrained openai`.
+
+### Gradient accumulation
+
+To simulate larger batches use `--accum-freq k`. If per gpu batch size, `--batch-size`, is `m`, then the effective batch size will be `k * m * num_gpus`.
+
+When increasing `--accum-freq` from its default of 1, samples/s will remain approximately constant (batch size will double, as will time-per-batch). It is recommended to use other features to reduce batch size such as `--grad-checkpointing --local-loss --gather-with-grad` before increasing `--accum-freq`. `--accum-freq` can be used in addition to these features.
+
+Instead of 1 forward pass per example, there are now 2 forward passes per-example. However, the first is done with `torch.no_grad`.
+
+There is some additional GPU memory required --- the features and data from all `m` batches are stored in memory.
+
+There are also `m` loss computations instead of the usual 1.
+
+For more information see Cui et al. (https://arxiv.org/abs/2112.09331) or Pham et al. (https://arxiv.org/abs/2111.10050).
+
+### Int8 Support
+
+We have beta support for int8 training and inference.
+You can enable int8 training with `--use-bnb-linear SwitchBackLinearGlobal` or `--use-bnb-linear SwitchBackLinearGlobalMemEfficient`.
+Please see the bitsandbytes library for definitions for these layers.
+For CLIP VIT-Huge this should currently correspond to a 10% training speedup with no accuracy loss.
+More speedups comin when the attention layer is refactored so that linear layers man be replaced there, too.
+
+See the tutorial https://github.com/mlfoundations/open_clip/blob/main/tutorials/int8_tutorial.ipynb or [paper](https://arxiv.org/abs/2304.13013).
+
+### Support for remote loading/training
+
+It is always possible to resume directly from a remote file, e.g., a file in an s3 bucket. Just set `--resume s3:// `.
+This will work with any filesystem supported by `fsspec`.
+
+It is also possible to train `open_clip` models while continuously backing up to s3. This can help to avoid slow local file systems.
+
+Say that your node has a local ssd `/scratch`, an s3 bucket `s3://`.
+
+In that case, set `--logs /scratch` and `--remote-sync s3://`. Then, a background process will sync `/scratch/` to `s3:///`. After syncing, the background process will sleep for `--remote-sync-frequency` seconds, which defaults to 5 minutes.
+
+There is also experimental support for syncing to other remote file systems, not just s3. To do so, specify `--remote-sync-protocol fsspec`. However, this is currently very slow and not recommended.
+
+Also, to optionally avoid saving too many checkpoints locally when using these features, you can use `--delete-previous-checkpoint` which deletes the previous checkpoint after saving a new one.
+
+Note: if you are using this feature with `--resume latest`, there are a few warnings. First, use with `--save-most-recent` is not supported. Second, only `s3` is supported. Finally, since the sync happens in the background, it is possible that the most recent checkpoint may not be finished syncing to the remote.
+
+### Pushing Models to Hugging Face Hub
+
+The module `open_clip.push_to_hf_hub` includes helpers for pushing models /w weights and config to the HF Hub.
+
+The tool can be run from command line, ex:
+`python -m open_clip.push_to_hf_hub --model convnext_large_d_320 --pretrained /train/checkpoints/epoch_12.pt --repo-id laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft`
+
+
+
+## Acknowledgments
+
+We gratefully acknowledge the Gauss Centre for Supercomputing e.V. (www.gauss-centre.eu) for funding this part of work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC).
+
+## The Team
+
+Current development of this repository is led by [Ross Wightman](https://rwightman.com/), [Romain Beaumont](https://github.com/rom1504), [Cade Gordon](http://cadegordon.io/), and [Vaishaal Shankar](http://vaishaal.com/).
+
+The original version of this repository is from a group of researchers at UW, Google, Stanford, Amazon, Columbia, and Berkeley.
+
+[Gabriel Ilharco*](http://gabrielilharco.com/), [Mitchell Wortsman*](https://mitchellnw.github.io/), [Nicholas Carlini](https://nicholas.carlini.com/), [Rohan Taori](https://www.rohantaori.com/), [Achal Dave](http://www.achaldave.com/), [Vaishaal Shankar](http://vaishaal.com/), [John Miller](https://people.eecs.berkeley.edu/~miller_john/), [Hongseok Namkoong](https://hsnamkoong.github.io/), [Hannaneh Hajishirzi](https://homes.cs.washington.edu/~hannaneh/), [Ali Farhadi](https://homes.cs.washington.edu/~ali/), [Ludwig Schmidt](https://people.csail.mit.edu/ludwigs/)
+
+Special thanks to [Jong Wook Kim](https://jongwook.kim/) and [Alec Radford](https://github.com/Newmu) for help with reproducing CLIP!
+
+## Citing
+
+If you found this repository useful, please consider citing:
+```bibtex
+@software{ilharco_gabriel_2021_5143773,
+ author = {Ilharco, Gabriel and
+ Wortsman, Mitchell and
+ Wightman, Ross and
+ Gordon, Cade and
+ Carlini, Nicholas and
+ Taori, Rohan and
+ Dave, Achal and
+ Shankar, Vaishaal and
+ Namkoong, Hongseok and
+ Miller, John and
+ Hajishirzi, Hannaneh and
+ Farhadi, Ali and
+ Schmidt, Ludwig},
+ title = {OpenCLIP},
+ month = jul,
+ year = 2021,
+ note = {If you use this software, please cite it as below.},
+ publisher = {Zenodo},
+ version = {0.1},
+ doi = {10.5281/zenodo.5143773},
+ url = {https://doi.org/10.5281/zenodo.5143773}
+}
+```
+
+```bibtex
+@inproceedings{cherti2023reproducible,
+ title={Reproducible scaling laws for contrastive language-image learning},
+ author={Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={2818--2829},
+ year={2023}
+}
+```
+
+```bibtex
+@inproceedings{Radford2021LearningTV,
+ title={Learning Transferable Visual Models From Natural Language Supervision},
+ author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
+ booktitle={ICML},
+ year={2021}
+}
+```
+
+```bibtex
+@inproceedings{schuhmann2022laionb,
+ title={{LAION}-5B: An open large-scale dataset for training next generation image-text models},
+ author={Christoph Schuhmann and
+ Romain Beaumont and
+ Richard Vencu and
+ Cade W Gordon and
+ Ross Wightman and
+ Mehdi Cherti and
+ Theo Coombes and
+ Aarush Katta and
+ Clayton Mullis and
+ Mitchell Wortsman and
+ Patrick Schramowski and
+ Srivatsa R Kundurthy and
+ Katherine Crowson and
+ Ludwig Schmidt and
+ Robert Kaczmarczyk and
+ Jenia Jitsev},
+ booktitle={Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
+ year={2022},
+ url={https://openreview.net/forum?id=M3Y74vmsMcY}
+}
+```
+
+[](https://zenodo.org/badge/latestdoi/390536799)
diff --git a/models.txt b/models.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ce97c15febdbd26e1c79a71a0c34e059853a7611
--- /dev/null
+++ b/models.txt
@@ -0,0 +1,2 @@
+RN101
+RN50
diff --git a/pytest.ini b/pytest.ini
new file mode 100644
index 0000000000000000000000000000000000000000..9546b10ce86328ef21697b8d134a6d5865632f35
--- /dev/null
+++ b/pytest.ini
@@ -0,0 +1,3 @@
+[pytest]
+markers =
+ regression_test
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4b1ff4a3d66d6ce16afb3712fe26d698e0323b43
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,8 @@
+torch>=1.9.0
+torchvision
+regex
+ftfy
+tqdm
+huggingface_hub
+safetensors
+timm
diff --git a/src/open_clip/__init__.py b/src/open_clip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0419b4d7887b5af810f6251c9e4b3c18971b59a
--- /dev/null
+++ b/src/open_clip/__init__.py
@@ -0,0 +1,18 @@
+from .version import __version__
+
+from .coca_model import CoCa
+from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
+from .factory import create_model, create_model_and_transforms, create_model_from_pretrained, get_tokenizer, create_loss
+from .factory import list_models, add_model_config, get_model_config, load_checkpoint
+from .loss import ClipLoss, DistillClipLoss, CoCaLoss
+from .model import CLIP, CustomTextCLIP, CLIPTextCfg, CLIPVisionCfg, \
+ convert_weights_to_lp, convert_weights_to_fp16, trace_model, get_cast_dtype, get_input_dtype, \
+ get_model_tokenize_cfg, get_model_preprocess_cfg, set_model_preprocess_cfg
+from .openai import load_openai_model, list_openai_models
+from .pretrained import list_pretrained, list_pretrained_models_by_tag, list_pretrained_tags_by_model, \
+ get_pretrained_url, download_pretrained_from_url, is_pretrained_cfg, get_pretrained_cfg, download_pretrained
+from .push_to_hf_hub import push_pretrained_to_hf_hub, push_to_hf_hub
+from .tokenizer import SimpleTokenizer, tokenize, decode
+from .transform import image_transform, AugmentationCfg
+from .zero_shot_classifier import build_zero_shot_classifier, build_zero_shot_classifier_legacy
+from .zero_shot_metadata import OPENAI_IMAGENET_TEMPLATES, SIMPLE_IMAGENET_TEMPLATES, IMAGENET_CLASSNAMES
diff --git a/src/open_clip/coca_model.py b/src/open_clip/coca_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebf65563043237dfccf85e23b41d6da9ad113397
--- /dev/null
+++ b/src/open_clip/coca_model.py
@@ -0,0 +1,582 @@
+from typing import Dict, List, Optional, Union
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+import numpy as np
+from dataclasses import dataclass
+
+from .transformer import (
+ LayerNormFp32,
+ LayerNorm,
+ QuickGELU,
+ MultimodalTransformer,
+)
+from .model import CLIPTextCfg, CLIPVisionCfg, _build_vision_tower, _build_text_tower
+
+try:
+ from transformers import (
+ BeamSearchScorer,
+ LogitsProcessorList,
+ TopPLogitsWarper,
+ TopKLogitsWarper,
+ RepetitionPenaltyLogitsProcessor,
+ MinLengthLogitsProcessor,
+ MaxLengthCriteria,
+ StopStringCriteria,
+ EosTokenCriteria,
+ StoppingCriteriaList
+ )
+
+ GENERATION_TYPES = {
+ "top_k": TopKLogitsWarper,
+ "top_p": TopPLogitsWarper,
+ "beam_search": "beam_search"
+ }
+ _has_transformers = True
+except ImportError as e:
+ GENERATION_TYPES = {
+ "top_k": None,
+ "top_p": None,
+ "beam_search": "beam_search"
+ }
+ _has_transformers = False
+
+
+@dataclass
+class MultimodalCfg(CLIPTextCfg):
+ mlp_ratio: int = 4
+ dim_head: int = 64
+ heads: int = 8
+ n_queries: int = 256
+ attn_pooler_heads: int = 8
+
+
+def _build_text_decoder_tower(
+ embed_dim,
+ multimodal_cfg,
+ quick_gelu: bool = False,
+ cast_dtype: Optional[torch.dtype] = None,
+):
+ multimodal_cfg = MultimodalCfg(**multimodal_cfg) if isinstance(multimodal_cfg, dict) else multimodal_cfg
+ act_layer = QuickGELU if quick_gelu else nn.GELU
+ norm_layer = (
+ LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
+ )
+
+ decoder = MultimodalTransformer(
+ context_length=multimodal_cfg.context_length,
+ width=multimodal_cfg.width,
+ heads=multimodal_cfg.heads,
+ layers=multimodal_cfg.layers,
+ ls_init_value=multimodal_cfg.ls_init_value,
+ output_dim=embed_dim,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ )
+
+ return decoder
+
+
+def _token_to_tensor(token_id, device: str = "cpu") -> torch.Tensor:
+ if not isinstance(token_id, torch.Tensor):
+ if isinstance(token_id, int):
+ token_id = [token_id]
+ token_id = torch.tensor(token_id, device=device)
+ return token_id
+
+
+class CoCa(nn.Module):
+ def __init__(
+ self,
+ embed_dim,
+ multimodal_cfg: MultimodalCfg,
+ text_cfg: CLIPTextCfg,
+ vision_cfg: CLIPVisionCfg,
+ quick_gelu: bool = False,
+ init_logit_scale: float = np.log(1 / 0.07),
+ init_logit_bias: Optional[float] = None,
+ nonscalar_logit_scale: bool = False,
+ cast_dtype: Optional[torch.dtype] = None,
+ pad_id: int = 0,
+ ):
+ super().__init__()
+ multimodal_cfg = MultimodalCfg(**multimodal_cfg) if isinstance(multimodal_cfg, dict) else multimodal_cfg
+ text_cfg = CLIPTextCfg(**text_cfg) if isinstance(text_cfg, dict) else text_cfg
+ vision_cfg = CLIPVisionCfg(**vision_cfg) if isinstance(vision_cfg, dict) else vision_cfg
+
+ self.text = _build_text_tower(
+ embed_dim=embed_dim,
+ text_cfg=text_cfg,
+ quick_gelu=quick_gelu,
+ cast_dtype=cast_dtype,
+ )
+
+ vocab_size = (
+ text_cfg.vocab_size # for hf models
+ if hasattr(text_cfg, "hf_model_name") and text_cfg.hf_model_name is not None
+ else text_cfg.vocab_size
+ )
+
+ self.visual = _build_vision_tower(
+ embed_dim=embed_dim,
+ vision_cfg=vision_cfg,
+ quick_gelu=quick_gelu,
+ cast_dtype=cast_dtype,
+ )
+
+ self.text_decoder = _build_text_decoder_tower(
+ vocab_size,
+ multimodal_cfg=multimodal_cfg,
+ quick_gelu=quick_gelu,
+ cast_dtype=cast_dtype,
+ )
+
+ lshape = [1] if nonscalar_logit_scale else []
+ self.logit_scale = nn.Parameter(torch.ones(lshape) * init_logit_scale)
+ if init_logit_bias is not None:
+ self.logit_bias = nn.Parameter(torch.ones(lshape) * init_logit_bias)
+ else:
+ self.logit_bias = None
+ self.pad_id = pad_id
+
+ self.context_length = multimodal_cfg.context_length
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable: bool = True):
+ self.visual.set_grad_checkpointing(enable)
+ self.text.set_grad_checkpointing(enable)
+ self.text_decoder.set_grad_checkpointing(enable)
+
+ def _encode_image(self, images, normalize: bool = True):
+ image_latent, tokens_embs = self.visual(images)
+ image_latent = F.normalize(image_latent, dim=-1) if normalize else image_latent
+ return image_latent, tokens_embs
+
+ def _encode_text(self, text, normalize: bool = True):
+ text_latent, token_emb = self.text(text)
+ text_latent = F.normalize(text_latent, dim=-1) if normalize else text_latent
+ return text_latent, token_emb
+
+ def encode_image(self, images, normalize: bool = True):
+ image_latent, _ = self._encode_image(images, normalize=normalize)
+ return image_latent
+
+ def encode_text(self, text, normalize: bool = True):
+ text_latent, _ = self._encode_text(text, normalize=normalize)
+ return text_latent
+
+ def forward_intermediates(
+ self,
+ image: Optional[torch.Tensor] = None,
+ text: Optional[torch.Tensor] = None,
+ image_indices: Optional[Union[int, List[int]]] = None,
+ text_indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize: bool = True,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ image_output_fmt: str = 'NCHW',
+ image_output_extra_tokens: bool = False,
+ text_output_fmt: str = 'NLC',
+ text_output_extra_tokens: bool = False,
+ output_logits: bool = False,
+ output_logit_scale_bias: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ image: Input image tensor
+ text: Input text tensor
+ image_indices: For image tower, Take last n blocks if int, all if None, select matching indices if sequence
+ text_indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize: L2 Normalize final image and text features (if present)
+ normalize_intermediates: Apply final encoder norm layer to all intermediates (if possible)
+ intermediates_only: Only return intermediate features, do not return final features
+ image_output_fmt: Shape of intermediate image feature outputs
+ image_output_extra_tokens: Return both prefix and spatial intermediate tokens
+ text_output_fmt: Shape of intermediate text feature outputs
+ text_output_extra_tokens: Return both prefix and spatial intermediate tokens
+ output_logits: Include logits in output
+ output_logit_scale_bias: Include the logit scale bias in the output
+ Returns:
+
+ """
+ output = {}
+ if intermediates_only:
+ # intermediates only disables final feature normalization, and include logits
+ normalize = False
+ output_logits = False
+ if output_logits:
+ assert False, 'FIXME, needs implementing'
+
+ if image is not None:
+ image_output = self.visual.forward_intermediates(
+ image,
+ indices=image_indices,
+ stop_early=stop_early,
+ normalize_intermediates=normalize_intermediates,
+ intermediates_only=intermediates_only,
+ output_fmt=image_output_fmt,
+ output_extra_tokens=image_output_extra_tokens,
+ )
+ if normalize and "image_features" in image_output:
+ image_output["image_features"] = F.normalize(image_output["image_features"], dim=-1)
+ output.update(image_output)
+
+ if text is not None:
+ text_output = self.text.forward_intermediates(
+ text,
+ indices=text_indices,
+ stop_early=stop_early,
+ normalize_intermediates=normalize_intermediates,
+ intermediates_only=intermediates_only,
+ output_fmt=text_output_fmt,
+ output_extra_tokens=text_output_extra_tokens,
+ )
+ if normalize and "text_features" in text_output:
+ text_output["text_features"] = F.normalize(text_output["text_features"], dim=-1)
+ output.update(text_output)
+
+ # FIXME text decoder
+ logit_scale_exp = self.logit_scale.exp() if output_logits or output_logit_scale_bias else None
+ if output_logit_scale_bias:
+ output["logit_scale"] = logit_scale_exp
+ if self.logit_bias is not None:
+ output['logit_bias'] = self.logit_bias
+
+ return output
+
+ def forward(
+ self,
+ image,
+ text: Optional[torch.Tensor] = None,
+ image_latent: Optional[torch.Tensor] = None,
+ image_embs: Optional[torch.Tensor] = None,
+ output_labels: bool = True,
+ ):
+ if image_latent is None or image_embs is None:
+ image_latent, image_embs = self._encode_image(image)
+
+ if text is None:
+ return {"image_features": image_latent, "image_embs": image_embs}
+
+ text_latent, token_embs = self._encode_text(text)
+
+ # FIXME this isn't an ideal solution, would like to improve -RW
+ labels: Optional[torch.Tensor] = text[:, 1:] if output_labels else None
+ if output_labels:
+ # align text_embs and thus logits with labels for teacher-forcing caption loss
+ token_embs = token_embs[:, :-1]
+
+ logits = self.text_decoder(image_embs, token_embs)
+ out_dict = {
+ "image_features": image_latent,
+ "text_features": text_latent,
+ "logits": logits,
+ "logit_scale": self.logit_scale.exp()
+ }
+ if labels is not None:
+ out_dict["labels"] = labels
+ if self.logit_bias is not None:
+ out_dict["logit_bias"] = self.logit_bias
+ return out_dict
+
+ def generate(
+ self,
+ image,
+ text=None,
+ seq_len=30,
+ max_seq_len=77,
+ temperature=1.,
+ generation_type="beam_search",
+ top_p=0.1, # keep tokens in the 1 - top_p quantile
+ top_k=1, # keeps the top_k most probable tokens
+ pad_token_id=None,
+ eos_token_id=None,
+ sot_token_id=None,
+ num_beams=6,
+ num_beam_groups=3,
+ min_seq_len=5,
+ stopping_criteria=None,
+ repetition_penalty=1.0,
+ fixed_output_length=False # if True output.shape == (batch_size, seq_len)
+ ):
+ # taking many ideas and components from HuggingFace GenerationMixin
+ # https://huggingface.co/docs/transformers/main/en/main_classes/text_generation
+ assert _has_transformers, "Please install transformers for generate functionality. `pip install transformers`."
+ assert seq_len > min_seq_len, "seq_len must be larger than min_seq_len"
+ device = image.device
+
+ with torch.no_grad():
+ sot_token_id = _token_to_tensor(49406 if sot_token_id is None else sot_token_id, device=device)
+ eos_token_id = _token_to_tensor(49407 if eos_token_id is None else eos_token_id, device=device)
+ pad_token_id = self.pad_id if pad_token_id is None else pad_token_id
+ logit_processor = LogitsProcessorList(
+ [
+ MinLengthLogitsProcessor(min_seq_len, eos_token_id),
+ RepetitionPenaltyLogitsProcessor(repetition_penalty),
+ ]
+ )
+
+ if stopping_criteria is None:
+ stopping_criteria = [MaxLengthCriteria(max_length=seq_len)]
+ stopping_criteria = StoppingCriteriaList(stopping_criteria)
+
+ if generation_type == "beam_search":
+ output = self._generate_beamsearch(
+ image_inputs=image,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ sot_token_id=sot_token_id,
+ num_beams=num_beams,
+ num_beam_groups=num_beam_groups,
+ min_seq_len=min_seq_len,
+ stopping_criteria=stopping_criteria,
+ logit_processor=logit_processor,
+ )
+ if fixed_output_length and output.shape[1] < seq_len:
+ pad_len = seq_len - output.shape[1]
+ return torch.cat((
+ output,
+ torch.ones(output.shape[0], pad_len, device=device, dtype=output.dtype) * pad_token_id
+ ),
+ dim=1
+ )
+ return output
+
+ elif generation_type == "top_p":
+ logit_warper = GENERATION_TYPES[generation_type](top_p)
+ elif generation_type == "top_k":
+ logit_warper = GENERATION_TYPES[generation_type](top_k)
+ else:
+ raise ValueError(
+ f"generation_type has to be one of "
+ f"{'| ' + ' | '.join(list(GENERATION_TYPES.keys())) + ' |'}."
+ )
+
+ image_latent, image_embs = self._encode_image(image)
+
+ if text is None:
+ text = torch.ones((image.shape[0], 1), device=device, dtype=torch.long) * sot_token_id
+
+ was_training = self.training
+ num_dims = len(text.shape)
+
+ if num_dims == 1:
+ text = text[None, :]
+
+ self.eval()
+ out = text
+
+ while True:
+ x = out[:, -max_seq_len:]
+ cur_len = x.shape[1]
+ logits = self(
+ image,
+ x,
+ image_latent=image_latent,
+ image_embs=image_embs,
+ output_labels=False,
+ )["logits"][:, -1]
+ mask = (out[:, -1] == eos_token_id) | (out[:, -1] == pad_token_id)
+ sample = torch.ones((out.shape[0], 1), device=device, dtype=torch.long) * pad_token_id
+
+ if mask.all():
+ if not fixed_output_length:
+ break
+ else:
+ logits = logits[~mask, :]
+ filtered_logits = logit_processor(x[~mask, :], logits)
+ filtered_logits = logit_warper(x[~mask, :], filtered_logits)
+ probs = F.softmax(filtered_logits / temperature, dim=-1)
+
+ if (cur_len + 1 == seq_len):
+ sample[~mask, :] = torch.ones((sum(~mask), 1), device=device, dtype=torch.long) * eos_token_id
+ else:
+ sample[~mask, :] = torch.multinomial(probs, 1)
+
+ out = torch.cat((out, sample), dim=-1)
+
+ cur_len += 1
+
+ if all(stopping_criteria(out, None)):
+ break
+
+ if num_dims == 1:
+ out = out.squeeze(0)
+
+ self.train(was_training)
+ return out
+
+ def _generate_beamsearch(
+ self,
+ image_inputs,
+ pad_token_id=None,
+ eos_token_id=None,
+ sot_token_id=None,
+ num_beams=6,
+ num_beam_groups=3,
+ min_seq_len=5,
+ stopping_criteria=None,
+ logit_processor=None,
+ logit_warper=None,
+ ):
+ device = image_inputs.device
+ batch_size = image_inputs.shape[0]
+ image_inputs = torch.repeat_interleave(image_inputs, num_beams, dim=0)
+ image_latent, image_embs = self._encode_image(image_inputs)
+
+ input_ids = torch.ones((batch_size * num_beams, 1), device=device, dtype=torch.long)
+ input_ids = input_ids * sot_token_id
+ beam_scorer = BeamSearchScorer(
+ batch_size=batch_size,
+ num_beams=num_beams,
+ device=device,
+ num_beam_groups=num_beam_groups,
+ )
+ # instantiate logits processors
+ logits_processor = (
+ LogitsProcessorList([MinLengthLogitsProcessor(min_seq_len, eos_token_id=eos_token_id)])
+ if logit_processor is None
+ else logit_processor
+ )
+
+ num_beams = beam_scorer.num_beams
+ num_beam_groups = beam_scorer.num_beam_groups
+ num_sub_beams = num_beams // num_beam_groups
+ batch_size = len(beam_scorer._beam_hyps) // num_beam_groups
+ batch_beam_size, cur_len = input_ids.shape
+ beam_indices = None
+
+ if num_beams * batch_size != batch_beam_size:
+ raise ValueError(
+ f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
+ )
+
+ beam_scores = torch.full((batch_size, num_beams), -1e9, dtype=torch.float, device=device)
+ # initialise score of first beam of each group with 0 and the rest with 1e-9. This ensures that the beams in
+ # the same group don't produce same tokens everytime.
+ beam_scores[:, ::num_sub_beams] = 0
+ beam_scores = beam_scores.view((batch_size * num_beams,))
+
+ while True:
+
+ # predicted tokens in cur_len step
+ current_tokens = torch.zeros(batch_size * num_beams, dtype=input_ids.dtype, device=device)
+
+ # indices which will form the beams in the next time step
+ reordering_indices = torch.zeros(batch_size * num_beams, dtype=torch.long, device=device)
+
+ # do one decoder step on all beams of all sentences in batch
+ model_inputs = prepare_inputs_for_generation(input_ids=input_ids, image_inputs=image_inputs)
+ outputs = self(
+ model_inputs['images'],
+ model_inputs['text'],
+ image_latent=image_latent,
+ image_embs=image_embs,
+ output_labels=False,
+ )
+
+ for beam_group_idx in range(num_beam_groups):
+ group_start_idx = beam_group_idx * num_sub_beams
+ group_end_idx = min(group_start_idx + num_sub_beams, num_beams)
+ group_size = group_end_idx - group_start_idx
+
+ # indices of beams of current group among all sentences in batch
+ batch_group_indices = []
+
+ for batch_idx in range(batch_size):
+ batch_group_indices.extend(
+ [batch_idx * num_beams + idx for idx in range(group_start_idx, group_end_idx)]
+ )
+ group_input_ids = input_ids[batch_group_indices]
+
+ # select outputs of beams of currentg group only
+ next_token_logits = outputs['logits'][batch_group_indices, -1, :]
+ vocab_size = next_token_logits.shape[-1]
+
+ next_token_scores_processed = logits_processor(
+ group_input_ids, next_token_logits, current_tokens=current_tokens, beam_group_idx=beam_group_idx
+ )
+ next_token_scores = next_token_scores_processed + beam_scores[batch_group_indices].unsqueeze(-1)
+ next_token_scores = next_token_scores.expand_as(next_token_scores_processed)
+
+ # reshape for beam search
+ next_token_scores = next_token_scores.view(batch_size, group_size * vocab_size)
+
+ next_token_scores, next_tokens = torch.topk(
+ next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True
+ )
+
+ next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
+ next_tokens = next_tokens % vocab_size
+
+ # stateless
+ process_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
+ beam_outputs = beam_scorer.process(
+ group_input_ids,
+ next_token_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ beam_indices=process_beam_indices,
+ group_index=beam_group_idx,
+ )
+ beam_scores[batch_group_indices] = beam_outputs["next_beam_scores"]
+ beam_next_tokens = beam_outputs["next_beam_tokens"]
+ beam_idx = beam_outputs["next_beam_indices"]
+
+ input_ids[batch_group_indices] = group_input_ids[beam_idx]
+ group_input_ids = torch.cat([group_input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
+ current_tokens[batch_group_indices] = group_input_ids[:, -1]
+
+ # (beam_idx // group_size) -> batch_idx
+ # (beam_idx % group_size) -> offset of idx inside the group
+ reordering_indices[batch_group_indices] = (
+ num_beams * torch.div(beam_idx, group_size, rounding_mode="floor") + group_start_idx + (beam_idx % group_size)
+ )
+
+ input_ids = torch.cat([input_ids, current_tokens.unsqueeze(-1)], dim=-1)
+
+ # increase cur_len
+ cur_len = cur_len + 1
+ if beam_scorer.is_done or all(stopping_criteria(input_ids, None)):
+ break
+
+ final_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
+ sequence_outputs = beam_scorer.finalize(
+ input_ids,
+ beam_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ max_length=stopping_criteria.max_length,
+ beam_indices=final_beam_indices,
+ )
+ return sequence_outputs['sequences']
+
+
+def prepare_inputs_for_generation(input_ids, image_inputs, past=None, **kwargs):
+ if past:
+ input_ids = input_ids[:, -1].unsqueeze(-1)
+
+ attention_mask = kwargs.get("attention_mask", None)
+ position_ids = kwargs.get("position_ids", None)
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ else:
+ position_ids = None
+ return {
+ "text": input_ids,
+ "images": image_inputs,
+ "past_key_values": past,
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ }
diff --git a/src/open_clip/constants.py b/src/open_clip/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bdfc2451286e448b98c45392de6b2cc03292ca0
--- /dev/null
+++ b/src/open_clip/constants.py
@@ -0,0 +1,11 @@
+OPENAI_DATASET_MEAN = (0.48145466, 0.4578275, 0.40821073)
+OPENAI_DATASET_STD = (0.26862954, 0.26130258, 0.27577711)
+IMAGENET_MEAN = (0.485, 0.456, 0.406)
+IMAGENET_STD = (0.229, 0.224, 0.225)
+INCEPTION_MEAN = (0.5, 0.5, 0.5)
+INCEPTION_STD = (0.5, 0.5, 0.5)
+
+# Default name for a weights file hosted on the Huggingface Hub.
+HF_WEIGHTS_NAME = "open_clip_pytorch_model.bin" # default pytorch pkl
+HF_SAFE_WEIGHTS_NAME = "open_clip_model.safetensors" # safetensors version
+HF_CONFIG_NAME = 'open_clip_config.json'
diff --git a/src/open_clip/convert.py b/src/open_clip/convert.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a9aeafdb75df7e67429feed2c73f0ef02bce480
--- /dev/null
+++ b/src/open_clip/convert.py
@@ -0,0 +1,206 @@
+""" Conversion functions for 3rd part state-dicts and non-torch native checkpoint formats.
+"""
+from typing import Union
+
+import torch
+import numpy as np
+
+from .model import CLIP, CustomTextCLIP
+from .transformer import TextTransformer, Transformer
+
+
+@torch.no_grad()
+def load_big_vision_weights(model: CustomTextCLIP, checkpoint_path: str):
+ """ Load weights from .npz checkpoints for official Google big_vision image-text models
+
+ Currently, the SigLIP source models are supported and a CustomTextCLIP destination model
+ w/ timm image encoder.
+ """
+ from timm.layers import resample_patch_embed, resample_abs_pos_embed
+
+ def _n2p(w, t=True, idx=None):
+ if idx is not None:
+ w = w[idx]
+ if w.ndim == 4 and w.shape[0] == w.shape[1] == w.shape[2] == 1:
+ w = w.flatten()
+ if t:
+ if w.ndim == 4:
+ w = w.transpose([3, 2, 0, 1])
+ elif w.ndim == 3:
+ w = w.transpose([2, 0, 1])
+ elif w.ndim == 2:
+ w = w.transpose([1, 0])
+ return torch.from_numpy(w)
+
+ w = np.load(checkpoint_path)
+ interpolation = 'bilinear'
+ antialias = False
+
+ def _convert_timm_img(module, prefix):
+ embed_conv_w = _n2p(w[f'{prefix}embedding/kernel'])
+ if embed_conv_w.shape[-2:] != module.patch_embed.proj.weight.shape[-2:]:
+ embed_conv_w = resample_patch_embed(
+ embed_conv_w,
+ module.patch_embed.proj.weight.shape[-2:],
+ interpolation=interpolation,
+ antialias=antialias,
+ verbose=True,
+ )
+ module.patch_embed.proj.weight.copy_(embed_conv_w)
+ module.patch_embed.proj.bias.copy_(_n2p(w[f'{prefix}embedding/bias']))
+
+ if module.cls_token is not None:
+ module.cls_token.copy_(_n2p(w[f'{prefix}cls'], t=False))
+
+ pos_embed_w = _n2p(w[f'{prefix}pos_embedding'], t=False)
+ if pos_embed_w.shape != module.pos_embed.shape:
+ assert False, f'{pos_embed_w.shape}, {module.pos_embed.shape}'
+ num_prefix_tokens = 0 if getattr(module, 'no_embed_class', False) else getattr(module, 'num_prefix_tokens', 1)
+ pos_embed_w = resample_abs_pos_embed( # resize pos embedding when different size from pretrained weights
+ pos_embed_w,
+ new_size=module.patch_embed.grid_size,
+ num_prefix_tokens=num_prefix_tokens,
+ interpolation=interpolation,
+ antialias=antialias,
+ verbose=True,
+ )
+ module.pos_embed.copy_(pos_embed_w)
+
+ mha_sub, b_sub, ln1_sub = (0, 0, 1)
+ for i, block in enumerate(module.blocks.children()):
+ if f'{prefix}Transformer/encoderblock/LayerNorm_0/scale' in w:
+ block_prefix = f'{prefix}Transformer/encoderblock/'
+ idx = i
+ else:
+ block_prefix = f'{prefix}Transformer/encoderblock_{i}/'
+ idx = None
+ mha_prefix = block_prefix + f'MultiHeadDotProductAttention_{mha_sub}/'
+ block.norm1.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/scale'], idx=idx))
+ block.norm1.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/bias'], idx=idx))
+ block.attn.qkv.weight.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/kernel'], t=False, idx=idx).flatten(1).T for n in ('query', 'key', 'value')]))
+ block.attn.qkv.bias.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/bias'], t=False, idx=idx).reshape(-1) for n in ('query', 'key', 'value')]))
+ block.attn.proj.weight.copy_(_n2p(w[f'{mha_prefix}out/kernel'], idx=idx).flatten(1))
+ block.attn.proj.bias.copy_(_n2p(w[f'{mha_prefix}out/bias'], idx=idx))
+ block.norm2.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_{ln1_sub}/scale'], idx=idx))
+ block.norm2.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_{ln1_sub}/bias'], idx=idx))
+ for r in range(2):
+ getattr(block.mlp, f'fc{r + 1}').weight.copy_(
+ _n2p(w[f'{block_prefix}MlpBlock_{b_sub}/Dense_{r}/kernel'], idx=idx))
+ getattr(block.mlp, f'fc{r + 1}').bias.copy_(
+ _n2p(w[f'{block_prefix}MlpBlock_{b_sub}/Dense_{r}/bias'], idx=idx))
+
+ module.norm.weight.copy_(_n2p(w[f'{prefix}Transformer/encoder_norm/scale']))
+ module.norm.bias.copy_(_n2p(w[f'{prefix}Transformer/encoder_norm/bias']))
+
+ if module.attn_pool is not None:
+ block_prefix = f'{prefix}MAPHead_0/'
+ mha_prefix = block_prefix + f'MultiHeadDotProductAttention_0/'
+ module.attn_pool.latent.copy_(_n2p(w[f'{block_prefix}probe'], t=False))
+ module.attn_pool.q.weight.copy_(_n2p(w[f'{mha_prefix}query/kernel'], t=False).flatten(1).T)
+ module.attn_pool.q.bias.copy_(_n2p(w[f'{mha_prefix}query/bias'], t=False).reshape(-1))
+ module.attn_pool.kv.weight.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/kernel'], t=False).flatten(1).T for n in ('key', 'value')]))
+ module.attn_pool.kv.bias.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/bias'], t=False).reshape(-1) for n in ('key', 'value')]))
+ module.attn_pool.proj.weight.copy_(_n2p(w[f'{mha_prefix}out/kernel']).flatten(1))
+ module.attn_pool.proj.bias.copy_(_n2p(w[f'{mha_prefix}out/bias']))
+ module.attn_pool.norm.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/scale']))
+ module.attn_pool.norm.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/bias']))
+ for r in range(2):
+ getattr(module.attn_pool.mlp, f'fc{r + 1}').weight.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_{r}/kernel']))
+ getattr(module.attn_pool.mlp, f'fc{r + 1}').bias.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_{r}/bias']))
+
+ def _convert_openclip_transformer(module: Transformer, prefix):
+ for i, block in enumerate(module.resblocks.children()):
+ if f'{prefix}encoderblock/LayerNorm_0/scale' in w:
+ block_prefix = f'{prefix}encoderblock/'
+ idx = i
+ else:
+ block_prefix = f'{prefix}encoderblock_{i}/'
+ idx = None
+ mha_prefix = block_prefix + f'MultiHeadDotProductAttention_0/'
+ block.ln_1.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/scale'], idx=idx))
+ block.ln_1.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/bias'], idx=idx))
+ block.attn.in_proj_weight.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/kernel'], t=False, idx=idx).flatten(1).T for n in ('query', 'key', 'value')]))
+ block.attn.in_proj_bias.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/bias'], t=False, idx=idx).reshape(-1) for n in ('query', 'key', 'value')]))
+ block.attn.out_proj.weight.copy_(_n2p(w[f'{mha_prefix}out/kernel'], idx=idx).flatten(1))
+ block.attn.out_proj.bias.copy_(_n2p(w[f'{mha_prefix}out/bias'], idx=idx))
+ block.ln_2.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_1/scale'], idx=idx))
+ block.ln_2.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_1/bias'], idx=idx))
+ block.mlp.c_fc.weight.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_0/kernel'], idx=idx))
+ block.mlp.c_fc.bias.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_0/bias'], idx=idx))
+ block.mlp.c_proj.weight.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_1/kernel'], idx=idx))
+ block.mlp.c_proj.bias.copy_(_n2p(w[f'{block_prefix}MlpBlock_0/Dense_1/bias'], idx=idx))
+
+ def _convert_openclip_txt(module: TextTransformer, prefix):
+ module.token_embedding.weight.copy_(_n2p(w[f'{prefix}Embed_0/embedding'], t=False))
+ pos_embed_w = _n2p(w[f'{prefix}pos_embedding'], t=False).squeeze(0)
+ module.positional_embedding.copy_(pos_embed_w)
+ _convert_openclip_transformer(module.transformer, prefix=prefix + 'Encoder_0/')
+ module.ln_final.weight.copy_(_n2p(w[f'{prefix}Encoder_0/encoder_norm/scale']))
+ module.ln_final.bias.copy_(_n2p(w[f'{prefix}Encoder_0/encoder_norm/bias']))
+ if module.text_projection is not None:
+ module.text_projection.weight.copy_(_n2p(w[f'{prefix}head/kernel']))
+ module.text_projection.bias.copy_(_n2p(w[f'{prefix}head/bias']))
+
+ root_prefix = 'params/' if 'params/b' in w else ''
+ _convert_timm_img(model.visual.trunk, f'{root_prefix}img/')
+ _convert_openclip_txt(model.text, f'{root_prefix}txt/')
+ model.logit_bias.copy_(_n2p(w[f'{root_prefix}b'])[0])
+ model.logit_scale.copy_(_n2p(w[f'{root_prefix}t'])[0])
+
+
+@torch.no_grad()
+def convert_mobile_clip_state_dict(model: CustomTextCLIP, state_dict, fastvit = True):
+
+ def _convert_timm_img(state_dict):
+ if fastvit:
+ from timm.models.fastvit import checkpoint_filter_fn
+ else:
+ from timm.models.vision_transformer_hybrid import checkpoint_filter_fn
+ timm_state_dict = checkpoint_filter_fn(state_dict, model.visual.trunk)
+ timm_state_dict = {'visual.trunk.' + k: v for k, v in timm_state_dict.items()}
+ return timm_state_dict
+
+ def _convert_openclip_txt(state_dict, prefix='text_encoder.'):
+ text_dict = {}
+ for k, v in state_dict.items():
+ if not k.startswith(prefix):
+ continue
+ k = k.replace(prefix, '')
+ k = k.replace('projection_layer', 'text_projection')
+ k = k.replace('embedding_layer', 'token_embedding')
+ if k.startswith('positional_embedding.pos_embed.pos_embed'):
+ k = k.replace('positional_embedding.pos_embed.pos_embed', 'positional_embedding')
+ v = v.squeeze()
+ k = k.replace('final_layer_norm', 'ln_final')
+ k = k.replace('pre_norm_mha.0', 'ln_1')
+ k = k.replace('pre_norm_mha.1', 'attn')
+ k = k.replace('pre_norm_ffn.0', 'ln_2')
+ k = k.replace('pre_norm_ffn.1', 'mlp.c_fc')
+ k = k.replace('pre_norm_ffn.4', 'mlp.c_proj')
+ k = k.replace('qkv_proj.weight', 'in_proj_weight')
+ k = k.replace('qkv_proj.bias', 'in_proj_bias')
+ k = k.replace('transformer.', 'transformer.resblocks.')
+ text_dict['text.' + k] = v
+ return text_dict
+
+ image_dict = _convert_timm_img(state_dict)
+ text_dict = _convert_openclip_txt(state_dict)
+ out_dict = {**image_dict, **text_dict}
+ out_dict['logit_scale'] = state_dict['logit_scale']
+ return out_dict
+
+
+def convert_state_dict(model: Union[CustomTextCLIP, CLIP], state_dict):
+ if 'image_encoder.model.patch_embed.0.rbr_conv.0.conv.weight' in state_dict:
+ # Apple MobileCLIP s1 & s2 state_dicts (s0 and b not currently supported)
+ state_dict = convert_mobile_clip_state_dict(model, state_dict)
+ if 'image_encoder.model.patch_emb.0.block.conv.weight' in state_dict:
+ # convert b model
+ state_dict = convert_mobile_clip_state_dict(model, state_dict, fastvit=False)
+ return state_dict
diff --git a/src/open_clip/factory.py b/src/open_clip/factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8a8c70eb97892305aec4feb7ec2b2c46b7afa6a
--- /dev/null
+++ b/src/open_clip/factory.py
@@ -0,0 +1,586 @@
+import json
+import logging
+import os
+import re
+import warnings
+from copy import deepcopy
+from dataclasses import asdict
+from pathlib import Path
+from typing import Any, Dict, Optional, Tuple, Union
+
+import torch
+
+from .convert import convert_state_dict
+from .model import CLIP, CustomTextCLIP, convert_weights_to_lp, convert_to_custom_text_state_dict,\
+ resize_pos_embed, get_cast_dtype, resize_text_pos_embed, set_model_preprocess_cfg
+from .coca_model import CoCa
+from .loss import ClipLoss, DistillClipLoss, CoCaLoss, SigLipLoss
+from .pretrained import is_pretrained_cfg, get_pretrained_cfg, download_pretrained,\
+ list_pretrained_tags_by_model, download_pretrained_from_hf
+from .transform import image_transform_v2, AugmentationCfg, PreprocessCfg, merge_preprocess_dict, merge_preprocess_kwargs
+from .tokenizer import HFTokenizer, SimpleTokenizer, SigLipTokenizer, DEFAULT_CONTEXT_LENGTH
+
+HF_HUB_PREFIX = 'hf-hub:'
+_MODEL_CONFIG_PATHS = [Path(__file__).parent / f"model_configs/"]
+_MODEL_CONFIGS = {} # directory (model_name: config) of model architecture configs
+
+
+def _natural_key(string_):
+ return [int(s) if s.isdigit() else s for s in re.split(r'(\d+)', string_.lower())]
+
+
+def _rescan_model_configs():
+ global _MODEL_CONFIGS
+
+ config_ext = ('.json',)
+ config_files = []
+ for config_path in _MODEL_CONFIG_PATHS:
+ if config_path.is_file() and config_path.suffix in config_ext:
+ config_files.append(config_path)
+ elif config_path.is_dir():
+ for ext in config_ext:
+ config_files.extend(config_path.glob(f'*{ext}'))
+
+ for cf in config_files:
+ with open(cf, 'r') as f:
+ model_cfg = json.load(f)
+ if all(a in model_cfg for a in ('embed_dim', 'vision_cfg', 'text_cfg')):
+ _MODEL_CONFIGS[cf.stem] = model_cfg
+
+ _MODEL_CONFIGS = {k: v for k, v in sorted(_MODEL_CONFIGS.items(), key=lambda x: _natural_key(x[0]))}
+
+
+_rescan_model_configs() # initial populate of model config registry
+
+
+def list_models():
+ """ enumerate available model architectures based on config files """
+ return list(_MODEL_CONFIGS.keys())
+
+
+def add_model_config(path):
+ """ add model config path or file and update registry """
+ if not isinstance(path, Path):
+ path = Path(path)
+ _MODEL_CONFIG_PATHS.append(path)
+ _rescan_model_configs()
+
+
+def get_model_config(model_name):
+ """ Fetch model config from builtin (local library) configs.
+ """
+ if model_name in _MODEL_CONFIGS:
+ return deepcopy(_MODEL_CONFIGS[model_name])
+ else:
+ return None
+
+
+def _get_hf_config(
+ model_id: str,
+ cache_dir: Optional[str] = None,
+):
+ """ Fetch model config from HuggingFace Hub.
+ """
+ config_path = download_pretrained_from_hf(
+ model_id,
+ filename='open_clip_config.json',
+ cache_dir=cache_dir,
+ )
+ with open(config_path, 'r', encoding='utf-8') as f:
+ config = json.load(f)
+ return config
+
+
+def get_tokenizer(
+ model_name: str = '',
+ context_length: Optional[int] = None,
+ cache_dir: Optional[str] = None,
+ **kwargs,
+):
+ if model_name.startswith(HF_HUB_PREFIX):
+ model_name = model_name[len(HF_HUB_PREFIX):]
+ try:
+ config = _get_hf_config(model_name, cache_dir=cache_dir)['model_cfg']
+ except Exception:
+ tokenizer = HFTokenizer(
+ model_name,
+ context_length=context_length or DEFAULT_CONTEXT_LENGTH,
+ cache_dir=cache_dir,
+ **kwargs,
+ )
+ return tokenizer
+ else:
+ config = get_model_config(model_name)
+ assert config is not None, f"No valid model config found for {model_name}."
+
+ text_config = config.get('text_cfg', {})
+ if 'tokenizer_kwargs' in text_config:
+ tokenizer_kwargs = dict(text_config['tokenizer_kwargs'], **kwargs)
+ else:
+ tokenizer_kwargs = kwargs
+
+ if context_length is None:
+ context_length = text_config.get('context_length', DEFAULT_CONTEXT_LENGTH)
+
+ model_name = model_name.lower()
+ if text_config.get('hf_tokenizer_name', ''):
+ tokenizer = HFTokenizer(
+ text_config['hf_tokenizer_name'],
+ context_length=context_length,
+ cache_dir=cache_dir,
+ **tokenizer_kwargs,
+ )
+ elif 'siglip' in model_name:
+ tn = 'gemma' if 'siglip2' in model_name else 'mc4' if 'i18n' in model_name else 'c4-en'
+ tokenizer = SigLipTokenizer(
+ tn,
+ context_length=context_length,
+ # **tokenizer_kwargs,
+ )
+ else:
+ tokenizer = SimpleTokenizer(
+ context_length=context_length,
+ **tokenizer_kwargs,
+ )
+
+ return tokenizer
+
+
+def load_state_dict(
+ checkpoint_path: str,
+ device='cpu',
+ weights_only=True,
+):
+ # Check if safetensors or not and load weights accordingly
+ if str(checkpoint_path).endswith(".safetensors"):
+ from safetensors.torch import load_file
+ checkpoint = load_file(checkpoint_path, device=device)
+ else:
+ try:
+ checkpoint = torch.load(checkpoint_path, map_location=device, weights_only=weights_only)
+ except TypeError:
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+
+ if isinstance(checkpoint, dict) and 'state_dict' in checkpoint:
+ state_dict = checkpoint['state_dict']
+ elif isinstance(checkpoint, torch.jit.ScriptModule):
+ state_dict = checkpoint.state_dict()
+ for key in ["input_resolution", "context_length", "vocab_size"]:
+ state_dict.pop(key, None)
+ else:
+ state_dict = checkpoint
+ if next(iter(state_dict.items()))[0].startswith('module'):
+ state_dict = {k[7:]: v for k, v in state_dict.items()}
+ return state_dict
+
+
+def load_checkpoint(
+ model: Union[CLIP, CustomTextCLIP],
+ checkpoint_path: str,
+ strict: bool = True,
+ weights_only: bool = True,
+ device='cpu',
+):
+ if Path(checkpoint_path).suffix in ('.npz', '.npy'):
+ # Separate path loading numpy big_vision (SigLIP) weights
+ from open_clip.convert import load_big_vision_weights
+ load_big_vision_weights(model, checkpoint_path)
+ return {}
+
+ state_dict = load_state_dict(checkpoint_path, device=device, weights_only=weights_only)
+
+ # Detect & convert 3rd party state_dicts -> open_clip
+ state_dict = convert_state_dict(model, state_dict)
+
+ # Detect old format and make compatible with new format
+ if 'positional_embedding' in state_dict and not hasattr(model, 'positional_embedding'):
+ state_dict = convert_to_custom_text_state_dict(state_dict)
+
+ # correct if logit_scale differs in being scaler vs 1d param
+ if 'logit_scale' in state_dict and model.logit_scale.ndim != state_dict['logit_scale'].ndim:
+ state_dict['logit_scale'] = state_dict['logit_scale'].reshape(model.logit_scale.shape)
+
+ # correct if logit_bias differs in being scaler vs 1d param
+ if 'logit_bias' in state_dict and model.logit_bias.ndim != state_dict['logit_bias'].ndim:
+ state_dict['logit_bias'] = state_dict['logit_bias'].reshape(model.logit_bias.shape)
+
+ # If loading a non-SigLIP model for SigLIP training. See https://github.com/mlfoundations/open_clip/issues/712
+ if 'logit_bias' not in state_dict and model.logit_bias is not None:
+ state_dict["logit_bias"] = torch.zeros_like(state_dict["logit_scale"])
+
+ # Certain text transformers no longer expect position_ids after transformers==4.31
+ position_id_key = 'text.transformer.embeddings.position_ids'
+ if position_id_key in state_dict and not hasattr(model, position_id_key):
+ del state_dict[position_id_key]
+
+ resize_pos_embed(state_dict, model)
+ resize_text_pos_embed(state_dict, model)
+
+ # Finally, load the massaged state_dict into model
+ incompatible_keys = model.load_state_dict(state_dict, strict=strict)
+ return incompatible_keys
+
+
+def create_model(
+ model_name: str,
+ pretrained: Optional[str] = None,
+ precision: str = 'fp32',
+ device: Union[str, torch.device] = 'cpu',
+ jit: bool = False,
+ force_quick_gelu: bool = False,
+ force_custom_text: bool = False,
+ force_patch_dropout: Optional[float] = None,
+ force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
+ force_preprocess_cfg: Optional[Dict[str, Any]] = None,
+ pretrained_image: bool = False,
+ pretrained_hf: bool = True,
+ cache_dir: Optional[str] = None,
+ output_dict: Optional[bool] = None,
+ require_pretrained: bool = False,
+ load_weights_only: bool = True,
+ **model_kwargs,
+):
+ """Creates and configures a contrastive vision-language model.
+
+ Args:
+ model_name: Name of the model architecture to create. Can be a local model name
+ or a Hugging Face model ID prefixed with 'hf-hub:'.
+ pretrained: Tag/path for pretrained model weights. Can be:
+ - A pretrained tag name (e.g., 'openai')
+ - A path to local weights
+ - None to initialize with random weights
+ precision: Model precision/AMP configuration. Options:
+ - 'fp32': 32-bit floating point
+ - 'fp16'/'bf16': Mixed precision with FP32 for certain layers
+ - 'pure_fp16'/'pure_bf16': Pure 16-bit precision
+ device: Device to load the model on ('cpu', 'cuda', or torch.device object)
+ jit: If True, JIT compile the model
+ force_quick_gelu: Force use of QuickGELU activation
+ force_custom_text: Force use of custom text encoder
+ force_patch_dropout: Override default patch dropout value
+ force_image_size: Override default image size for vision encoder
+ force_preprocess_cfg: Override default preprocessing configuration
+ pretrained_image: Load pretrained weights for timm vision models
+ pretrained_hf: Load pretrained weights for HF text models when not loading CLIP weights
+ cache_dir: Override default cache directory for downloaded model files
+ output_dict: If True and model supports it, return dictionary of features
+ require_pretrained: Raise error if pretrained weights cannot be loaded
+ load_weights_only: Only deserialize model weights and unpickling torch checkpoints (for safety)
+ **model_kwargs: Additional keyword arguments passed to model constructor
+
+ Returns:
+ Created and configured model instance
+
+ Raises:
+ RuntimeError: If model config is not found or required pretrained weights
+ cannot be loaded
+
+ Examples:
+ # Create basic CLIP model
+ model = create_model('ViT-B/32')
+
+ # Create CLIP model with mixed precision on GPU
+ model = create_model('ViT-B/32', precision='fp16', device='cuda')
+
+ # Load pretrained OpenAI weights
+ model = create_model('ViT-B/32', pretrained='openai')
+
+ # Load Hugging Face model
+ model = create_model('hf-hub:organization/model-name')
+ """
+
+ force_preprocess_cfg = force_preprocess_cfg or {}
+ preprocess_cfg = asdict(PreprocessCfg())
+ has_hf_hub_prefix = model_name.startswith(HF_HUB_PREFIX)
+ if has_hf_hub_prefix:
+ model_id = model_name[len(HF_HUB_PREFIX):]
+ checkpoint_path = download_pretrained_from_hf(model_id, cache_dir=cache_dir)
+ config = _get_hf_config(model_id, cache_dir=cache_dir)
+ preprocess_cfg = merge_preprocess_dict(preprocess_cfg, config['preprocess_cfg'])
+ model_cfg = config['model_cfg']
+ pretrained_hf = False # override, no need to load original HF text weights
+ else:
+ model_name = model_name.replace('/', '-') # for callers using old naming with / in ViT names
+ checkpoint_path = None
+ model_cfg = None
+
+ if isinstance(device, str):
+ device = torch.device(device)
+
+ model_cfg = model_cfg or get_model_config(model_name)
+ if model_cfg is not None:
+ logging.info(f'Loaded {model_name} model config.')
+ else:
+ logging.error(f'Model config for {model_name} not found; available models {list_models()}.')
+ raise RuntimeError(f'Model config for {model_name} not found.')
+
+ if force_quick_gelu:
+ # override for use of QuickGELU on non-OpenAI transformer models
+ model_cfg["quick_gelu"] = True
+
+ if force_patch_dropout is not None:
+ # override the default patch dropout value
+ model_cfg["vision_cfg"]["patch_dropout"] = force_patch_dropout
+
+ if force_image_size is not None:
+ # override model config's image size
+ model_cfg["vision_cfg"]["image_size"] = force_image_size
+
+ is_timm_model = 'timm_model_name' in model_cfg.get('vision_cfg', {})
+ if pretrained_image:
+ if is_timm_model:
+ # pretrained weight loading for timm models set via vision_cfg
+ model_cfg['vision_cfg']['timm_model_pretrained'] = True
+ else:
+ assert False, 'pretrained image towers currently only supported for timm models'
+
+ # cast_dtype set for fp16 and bf16 (manual mixed-precision), not set for 'amp' or 'pure' modes
+ cast_dtype = get_cast_dtype(precision)
+ is_hf_model = 'hf_model_name' in model_cfg.get('text_cfg', {})
+ if is_hf_model:
+ # load pretrained weights for HF text model IFF no CLIP weights being loaded
+ model_cfg['text_cfg']['hf_model_pretrained'] = pretrained_hf and not pretrained
+ custom_text = model_cfg.pop('custom_text', False) or force_custom_text or is_hf_model
+
+ model_cfg = dict(model_cfg, **model_kwargs) # merge cfg dict w/ kwargs (kwargs overrides cfg)
+ if custom_text:
+ if "multimodal_cfg" in model_cfg:
+ model = CoCa(**model_cfg, cast_dtype=cast_dtype)
+ else:
+ model = CustomTextCLIP(**model_cfg, cast_dtype=cast_dtype)
+ else:
+ model = CLIP(**model_cfg, cast_dtype=cast_dtype)
+
+ if precision in ("fp16", "bf16"):
+ dtype = torch.float16 if 'fp16' in precision else torch.bfloat16
+ # manual mixed precision that matches original OpenAI behaviour
+ if is_timm_model:
+ # FIXME this is a bit janky, create timm based model in low-precision and
+ # then cast only LayerNormFp32 instances back to float32 so they don't break.
+ # Why? The convert_weights_to_lp fn only works with native models.
+ model.to(device=device, dtype=dtype)
+ from .transformer import LayerNormFp32
+
+ def _convert_ln(m):
+ if isinstance(m, LayerNormFp32):
+ m.weight.data = m.weight.data.to(torch.float32)
+ m.bias.data = m.bias.data.to(torch.float32)
+ model.apply(_convert_ln)
+ else:
+ model.to(device=device)
+ convert_weights_to_lp(model, dtype=dtype)
+ elif precision in ("pure_fp16", "pure_bf16"):
+ dtype = torch.float16 if 'fp16' in precision else torch.bfloat16
+ model.to(device=device, dtype=dtype)
+ else:
+ model.to(device=device)
+
+ pretrained_loaded = False
+ if pretrained:
+ checkpoint_path = ''
+ pretrained_cfg = get_pretrained_cfg(model_name, pretrained)
+ if pretrained_cfg:
+ checkpoint_path = download_pretrained(pretrained_cfg, cache_dir=cache_dir)
+ preprocess_cfg = merge_preprocess_dict(preprocess_cfg, pretrained_cfg)
+ pretrained_quick_gelu = pretrained_cfg.get('quick_gelu', False)
+ model_quick_gelu = model_cfg.get('quick_gelu', False)
+ if pretrained_quick_gelu and not model_quick_gelu:
+ warnings.warn(
+ f'These pretrained weights were trained with QuickGELU activation but the model config does '
+ f'not have that enabled. Consider using a model config with a "-quickgelu" suffix or enable with a flag.')
+ elif not pretrained_quick_gelu and model_quick_gelu:
+ warnings.warn(
+ f'The pretrained weights were not trained with QuickGELU but this activation is enabled in the '
+ f'model config, consider using a model config without QuickGELU or disable override flags.')
+ elif os.path.exists(pretrained):
+ checkpoint_path = pretrained
+
+ if checkpoint_path:
+ logging.info(f'Loading pretrained {model_name} weights ({pretrained}).')
+ load_checkpoint(model, checkpoint_path, weights_only=load_weights_only)
+ else:
+ error_str = (
+ f'Pretrained weights ({pretrained}) not found for model {model_name}.'
+ f' Available pretrained tags ({list_pretrained_tags_by_model(model_name)}.')
+ logging.warning(error_str)
+ raise RuntimeError(error_str)
+ pretrained_loaded = True
+ elif has_hf_hub_prefix:
+ logging.info(f'Loading pretrained {model_name} weights ({checkpoint_path}).')
+ load_checkpoint(model, checkpoint_path, weights_only=load_weights_only)
+ pretrained_loaded = True
+
+ if require_pretrained and not pretrained_loaded:
+ # callers of create_model_from_pretrained always expect pretrained weights
+ raise RuntimeError(
+ f'Pretrained weights were required for (model: {model_name}, pretrained: {pretrained}) but not loaded.')
+
+ if output_dict and hasattr(model, "output_dict"):
+ model.output_dict = True
+
+ if jit:
+ model = torch.jit.script(model)
+
+ # set image preprocessing configuration in model attributes for convenience
+ if getattr(model.visual, 'image_size', None) is not None:
+ # use image_size set on model creation (via config or force_image_size arg)
+ force_preprocess_cfg['size'] = model.visual.image_size
+ set_model_preprocess_cfg(model, merge_preprocess_dict(preprocess_cfg, force_preprocess_cfg))
+
+ return model
+
+
+def create_loss(args):
+ if args.distill:
+ return DistillClipLoss(
+ local_loss=args.local_loss,
+ gather_with_grad=args.gather_with_grad,
+ cache_labels=True,
+ rank=args.rank,
+ world_size=args.world_size,
+ use_horovod=args.horovod,
+ )
+ elif "coca" in args.model.lower():
+ return CoCaLoss(
+ caption_loss_weight=args.coca_caption_loss_weight,
+ clip_loss_weight=args.coca_contrastive_loss_weight,
+ local_loss=args.local_loss,
+ gather_with_grad=args.gather_with_grad,
+ cache_labels=True,
+ rank=args.rank,
+ world_size=args.world_size,
+ use_horovod=args.horovod,
+ )
+ elif args.siglip:
+ assert not args.horovod, "Horovod not currently supported for SigLip"
+ return SigLipLoss(
+ rank=args.rank,
+ world_size=args.world_size,
+ dist_impl=args.loss_dist_impl, # siglip has multiple distributed implementations to choose from
+ )
+
+ return ClipLoss(
+ local_loss=args.local_loss,
+ gather_with_grad=args.gather_with_grad,
+ cache_labels=True,
+ rank=args.rank,
+ world_size=args.world_size,
+ use_horovod=args.horovod,
+ )
+
+
+def create_model_and_transforms(
+ model_name: str,
+ pretrained: Optional[str] = None,
+ precision: str = 'fp32',
+ device: Union[str, torch.device] = 'cpu',
+ jit: bool = False,
+ force_quick_gelu: bool = False,
+ force_custom_text: bool = False,
+ force_patch_dropout: Optional[float] = None,
+ force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
+ image_mean: Optional[Tuple[float, ...]] = None,
+ image_std: Optional[Tuple[float, ...]] = None,
+ image_interpolation: Optional[str] = None,
+ image_resize_mode: Optional[str] = None, # only effective for inference
+ aug_cfg: Optional[Union[Dict[str, Any], AugmentationCfg]] = None,
+ pretrained_image: bool = False,
+ pretrained_hf: bool = True,
+ cache_dir: Optional[str] = None,
+ output_dict: Optional[bool] = None,
+ load_weights_only: bool = True,
+ **model_kwargs,
+):
+ force_preprocess_cfg = merge_preprocess_kwargs(
+ {},
+ mean=image_mean,
+ std=image_std,
+ interpolation=image_interpolation,
+ resize_mode=image_resize_mode,
+ )
+
+ model = create_model(
+ model_name,
+ pretrained,
+ precision=precision,
+ device=device,
+ jit=jit,
+ force_quick_gelu=force_quick_gelu,
+ force_custom_text=force_custom_text,
+ force_patch_dropout=force_patch_dropout,
+ force_image_size=force_image_size,
+ force_preprocess_cfg=force_preprocess_cfg,
+ pretrained_image=pretrained_image,
+ pretrained_hf=pretrained_hf,
+ cache_dir=cache_dir,
+ output_dict=output_dict,
+ load_weights_only=load_weights_only,
+ **model_kwargs,
+ )
+
+ pp_cfg = PreprocessCfg(**model.visual.preprocess_cfg)
+
+ preprocess_train = image_transform_v2(
+ pp_cfg,
+ is_train=True,
+ aug_cfg=aug_cfg,
+ )
+ preprocess_val = image_transform_v2(
+ pp_cfg,
+ is_train=False,
+ )
+
+ return model, preprocess_train, preprocess_val
+
+
+def create_model_from_pretrained(
+ model_name: str,
+ pretrained: Optional[str] = None,
+ precision: str = 'fp32',
+ device: Union[str, torch.device] = 'cpu',
+ jit: bool = False,
+ force_quick_gelu: bool = False,
+ force_custom_text: bool = False,
+ force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
+ image_mean: Optional[Tuple[float, ...]] = None,
+ image_std: Optional[Tuple[float, ...]] = None,
+ image_interpolation: Optional[str] = None,
+ image_resize_mode: Optional[str] = None, # only effective for inference
+ return_transform: bool = True,
+ cache_dir: Optional[str] = None,
+ load_weights_only: bool = True,
+ **model_kwargs,
+):
+ force_preprocess_cfg = merge_preprocess_kwargs(
+ {},
+ mean=image_mean,
+ std=image_std,
+ interpolation=image_interpolation,
+ resize_mode=image_resize_mode,
+ )
+
+ model = create_model(
+ model_name,
+ pretrained,
+ precision=precision,
+ device=device,
+ jit=jit,
+ force_quick_gelu=force_quick_gelu,
+ force_custom_text=force_custom_text,
+ force_image_size=force_image_size,
+ force_preprocess_cfg=force_preprocess_cfg,
+ cache_dir=cache_dir,
+ require_pretrained=True,
+ load_weights_only=load_weights_only,
+ **model_kwargs,
+ )
+
+ if not return_transform:
+ return model
+
+ preprocess = image_transform_v2(
+ PreprocessCfg(**model.visual.preprocess_cfg),
+ is_train=False,
+ )
+
+ return model, preprocess
diff --git a/src/open_clip/hf_configs.py b/src/open_clip/hf_configs.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d2067476500a7c16511af18696fc5e23b066aff
--- /dev/null
+++ b/src/open_clip/hf_configs.py
@@ -0,0 +1,67 @@
+# HF architecture dict:
+arch_dict = {
+ # https://huggingface.co/docs/transformers/model_doc/roberta#roberta
+ "roberta": {
+ "config_names": {
+ "context_length": "max_position_embeddings",
+ "vocab_size": "vocab_size",
+ "width": "hidden_size",
+ "heads": "num_attention_heads",
+ "layers": "num_hidden_layers",
+ "layer_attr": "layer",
+ "token_embeddings_attr": "embeddings"
+ },
+ "pooler": "mean_pooler",
+ },
+ # https://huggingface.co/docs/transformers/model_doc/xlm-roberta#transformers.XLMRobertaConfig
+ "xlm-roberta": {
+ "config_names": {
+ "context_length": "max_position_embeddings",
+ "vocab_size": "vocab_size",
+ "width": "hidden_size",
+ "heads": "num_attention_heads",
+ "layers": "num_hidden_layers",
+ "layer_attr": "layer",
+ "token_embeddings_attr": "embeddings"
+ },
+ "pooler": "mean_pooler",
+ },
+ # https://huggingface.co/docs/transformers/model_doc/mt5#mt5
+ "mt5": {
+ "config_names": {
+ # unlimited seqlen
+ # https://github.com/google-research/text-to-text-transfer-transformer/issues/273
+ # https://github.com/huggingface/transformers/blob/v4.24.0/src/transformers/models/t5/modeling_t5.py#L374
+ "context_length": "",
+ "vocab_size": "vocab_size",
+ "width": "d_model",
+ "heads": "num_heads",
+ "layers": "num_layers",
+ "layer_attr": "block",
+ "token_embeddings_attr": "embed_tokens"
+ },
+ "pooler": "mean_pooler",
+ },
+ # https://huggingface.co/docs/transformers/model_doc/bert
+ "bert": {
+ "config_names": {
+ "context_length": "max_position_embeddings",
+ "vocab_size": "vocab_size",
+ "width": "hidden_size",
+ "heads": "num_attention_heads",
+ "layers": "num_hidden_layers",
+ },
+ "pooler": "cls_pooler",
+ },
+ # https://huggingface.co/docs/transformers/model_doc/m2m_100
+ "m2m_100": {
+ "config_names": {
+ "context_length": "max_position_embeddings",
+ "vocab_size": "vocab_size",
+ "width": "d_model",
+ "heads": "encoder_attention_heads",
+ "layers": "encoder_layers",
+ },
+ "pooler": "cls_pooler",
+ },
+}
diff --git a/src/open_clip/hf_model.py b/src/open_clip/hf_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..281a06cc5f16f41e17ba0e6ea9b5b29fab5bc076
--- /dev/null
+++ b/src/open_clip/hf_model.py
@@ -0,0 +1,193 @@
+""" huggingface model adapter
+
+Wraps HuggingFace transformers (https://github.com/huggingface/transformers) models for use as a text tower in CLIP model.
+"""
+import re
+
+import torch
+import torch.nn as nn
+from torch import TensorType
+
+try:
+ import transformers
+ from transformers import AutoModel, AutoTokenizer, AutoConfig, PretrainedConfig
+ from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, \
+ BaseModelOutputWithPoolingAndCrossAttentions
+except ImportError as e:
+ transformers = None
+
+
+ class BaseModelOutput:
+ pass
+
+
+ class PretrainedConfig:
+ pass
+
+from .hf_configs import arch_dict
+
+
+# utils
+def _camel2snake(s):
+ return re.sub(r'(? torch.Tensor:
+ # calculated ground-truth and cache if enabled
+ if self.prev_num_logits != num_logits or device not in self.labels:
+ labels = torch.arange(num_logits, device=device, dtype=torch.long)
+ if self.world_size > 1 and self.local_loss:
+ labels = labels + num_logits * self.rank
+ if self.cache_labels:
+ self.labels[device] = labels
+ self.prev_num_logits = num_logits
+ else:
+ labels = self.labels[device]
+ return labels
+
+ def get_logits(self, image_features, text_features, logit_scale):
+ if self.world_size > 1:
+ all_image_features, all_text_features = gather_features(
+ image_features,
+ text_features,
+ local_loss=self.local_loss,
+ gather_with_grad=self.gather_with_grad,
+ rank=self.rank,
+ world_size=self.world_size,
+ use_horovod=self.use_horovod,
+ )
+
+ if self.local_loss:
+ logits_per_image = logit_scale * image_features @ all_text_features.T
+ logits_per_text = logit_scale * text_features @ all_image_features.T
+ else:
+ logits_per_image = logit_scale * all_image_features @ all_text_features.T
+ logits_per_text = logits_per_image.T
+ else:
+ logits_per_image = logit_scale * image_features @ text_features.T
+ logits_per_text = logit_scale * text_features @ image_features.T
+
+ return logits_per_image, logits_per_text
+
+ def forward(self, image_features, text_features, logit_scale, output_dict=False):
+ device = image_features.device
+ logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
+ labels = self.get_ground_truth(device, logits_per_image.shape[0])
+
+ total_loss = (
+ F.cross_entropy(logits_per_image, labels) +
+ F.cross_entropy(logits_per_text, labels)
+ ) / 2
+
+ return {"contrastive_loss": total_loss} if output_dict else total_loss
+
+
+class CoCaLoss(ClipLoss):
+ def __init__(
+ self,
+ caption_loss_weight,
+ clip_loss_weight,
+ pad_id=0, # pad_token for open_clip custom tokenizer
+ local_loss=False,
+ gather_with_grad=False,
+ cache_labels=False,
+ rank=0,
+ world_size=1,
+ use_horovod=False,
+ ):
+ super().__init__(
+ local_loss=local_loss,
+ gather_with_grad=gather_with_grad,
+ cache_labels=cache_labels,
+ rank=rank,
+ world_size=world_size,
+ use_horovod=use_horovod
+ )
+
+ self.clip_loss_weight = clip_loss_weight
+ self.caption_loss_weight = caption_loss_weight
+ self.caption_loss = nn.CrossEntropyLoss(ignore_index=pad_id)
+
+ def forward(self, image_features, text_features, logits, labels, logit_scale, output_dict=False):
+ if self.clip_loss_weight:
+ clip_loss = super().forward(image_features, text_features, logit_scale)
+ clip_loss = self.clip_loss_weight * clip_loss
+ else:
+ clip_loss = torch.tensor(0, device=logits.device)
+
+ caption_loss = self.caption_loss(
+ logits.permute(0, 2, 1),
+ labels,
+ )
+ caption_loss = caption_loss * self.caption_loss_weight
+
+ if output_dict:
+ return {"contrastive_loss": clip_loss, "caption_loss": caption_loss}
+
+ return clip_loss, caption_loss
+
+
+class DistillClipLoss(ClipLoss):
+
+ def dist_loss(self, teacher_logits, student_logits):
+ return -(teacher_logits.softmax(dim=1) * student_logits.log_softmax(dim=1)).sum(dim=1).mean(dim=0)
+
+ def forward(
+ self,
+ image_features,
+ text_features,
+ logit_scale,
+ dist_image_features,
+ dist_text_features,
+ dist_logit_scale,
+ output_dict=False,
+ ):
+ logits_per_image, logits_per_text = \
+ self.get_logits(image_features, text_features, logit_scale)
+
+ dist_logits_per_image, dist_logits_per_text = \
+ self.get_logits(dist_image_features, dist_text_features, dist_logit_scale)
+
+ labels = self.get_ground_truth(image_features.device, logits_per_image.shape[0])
+
+ contrastive_loss = (
+ F.cross_entropy(logits_per_image, labels) +
+ F.cross_entropy(logits_per_text, labels)
+ ) / 2
+
+ distill_loss = (
+ self.dist_loss(dist_logits_per_image, logits_per_image) +
+ self.dist_loss(dist_logits_per_text, logits_per_text)
+ ) / 2
+
+ if output_dict:
+ return {"contrastive_loss": contrastive_loss, "distill_loss": distill_loss}
+
+ return contrastive_loss, distill_loss
+
+
+def neighbour_exchange(from_rank, to_rank, tensor, group=None):
+ tensor_recv = torch.zeros_like(tensor)
+ send_op = torch.distributed.P2POp(
+ torch.distributed.isend,
+ tensor,
+ to_rank,
+ group=group,
+ )
+ recv_op = torch.distributed.P2POp(
+ torch.distributed.irecv,
+ tensor_recv,
+ from_rank,
+ group=group,
+ )
+ reqs = torch.distributed.batch_isend_irecv([send_op, recv_op])
+ for req in reqs:
+ req.wait()
+ return tensor_recv
+
+
+def neighbour_exchange_bidir(left_rank, right_rank, tensor_to_left, tensor_to_right, group=None):
+ tensor_from_left = torch.zeros_like(tensor_to_right)
+ tensor_from_right = torch.zeros_like(tensor_to_left)
+ send_op_left = torch.distributed.P2POp(
+ torch.distributed.isend,
+ tensor_to_left,
+ left_rank,
+ group=group,
+ )
+ send_op_right = torch.distributed.P2POp(
+ torch.distributed.isend,
+ tensor_to_right,
+ right_rank,
+ group=group,
+ )
+ recv_op_left = torch.distributed.P2POp(
+ torch.distributed.irecv,
+ tensor_from_left,
+ left_rank,
+ group=group,
+ )
+ recv_op_right = torch.distributed.P2POp(
+ torch.distributed.irecv,
+ tensor_from_right,
+ right_rank,
+ group=group,
+ )
+ reqs = torch.distributed.batch_isend_irecv([send_op_right, send_op_left, recv_op_right, recv_op_left])
+ for req in reqs:
+ req.wait()
+ return tensor_from_right, tensor_from_left
+
+
+class NeighbourExchange(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, from_rank, to_rank, group, tensor):
+ ctx.group = group
+ ctx.from_rank = from_rank
+ ctx.to_rank = to_rank
+ return neighbour_exchange(from_rank, to_rank, tensor, group=group)
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ return (None, None, None) + (NeighbourExchange.apply(ctx.to_rank, ctx.from_rank, ctx.group, grad_output),)
+
+
+def neighbour_exchange_with_grad(from_rank, to_rank, tensor, group=None):
+ return NeighbourExchange.apply(from_rank, to_rank, group, tensor)
+
+
+class NeighbourExchangeBidir(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, left_rank, right_rank, group, tensor_to_left, tensor_to_right):
+ ctx.group = group
+ ctx.left_rank = left_rank
+ ctx.right_rank = right_rank
+ return neighbour_exchange_bidir(left_rank, right_rank, tensor_to_left, tensor_to_right, group=group)
+
+ @staticmethod
+ def backward(ctx, *grad_outputs):
+ return (None, None, None) + \
+ NeighbourExchangeBidir.apply(ctx.right_rank, ctx.left_rank, ctx.group, *grad_outputs)
+
+
+def neighbour_exchange_bidir_with_grad(left_rank, right_rank, tensor_to_left, tensor_to_right, group=None):
+ return NeighbourExchangeBidir.apply(left_rank, right_rank, group, tensor_to_left, tensor_to_right)
+
+
+class SigLipLoss(nn.Module):
+ """ Sigmoid Loss for Language Image Pre-Training (SigLIP) - https://arxiv.org/abs/2303.15343
+
+ @article{zhai2023sigmoid,
+ title={Sigmoid loss for language image pre-training},
+ author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
+ journal={arXiv preprint arXiv:2303.15343},
+ year={2023}
+ }
+ """
+ def __init__(
+ self,
+ cache_labels: bool = False,
+ rank: int = 0,
+ world_size: int = 1,
+ dist_impl: Optional[str] = None,
+ ):
+ super().__init__()
+ self.cache_labels = cache_labels
+ self.rank = rank
+ self.world_size = world_size
+ self.dist_impl = dist_impl or 'bidir' # default to bidir exchange for now, this will likely change
+ assert self.dist_impl in ('bidir', 'shift', 'reduce', 'gather')
+
+ # cache state FIXME cache not currently used, worthwhile?
+ self.prev_num_logits = 0
+ self.labels = {}
+
+ def get_ground_truth(self, device, dtype, num_logits, negative_only=False) -> torch.Tensor:
+ labels = -torch.ones((num_logits, num_logits), device=device, dtype=dtype)
+ if not negative_only:
+ labels = 2 * torch.eye(num_logits, device=device, dtype=dtype) + labels
+ return labels
+
+ def get_logits(self, image_features, text_features, logit_scale, logit_bias=None):
+ logits = logit_scale * image_features @ text_features.T
+ if logit_bias is not None:
+ logits += logit_bias
+ return logits
+
+ def _loss(self, image_features, text_features, logit_scale, logit_bias=None, negative_only=False):
+ logits = self.get_logits(image_features, text_features, logit_scale, logit_bias)
+ labels = self.get_ground_truth(
+ image_features.device,
+ image_features.dtype,
+ image_features.shape[0],
+ negative_only=negative_only,
+ )
+ loss = -F.logsigmoid(labels * logits).sum() / image_features.shape[0]
+ return loss
+
+ def forward(self, image_features, text_features, logit_scale, logit_bias, output_dict=False):
+ loss = self._loss(image_features, text_features, logit_scale, logit_bias)
+
+ if self.world_size > 1:
+ if self.dist_impl == 'bidir':
+ right_rank = (self.rank + 1) % self.world_size
+ left_rank = (self.rank - 1 + self.world_size) % self.world_size
+ text_features_to_right = text_features_to_left = text_features
+ num_bidir, remainder = divmod(self.world_size - 1, 2)
+ for i in range(num_bidir):
+ text_features_recv = neighbour_exchange_bidir_with_grad(
+ left_rank,
+ right_rank,
+ text_features_to_left,
+ text_features_to_right,
+ )
+ for f in text_features_recv:
+ loss += self._loss(
+ image_features,
+ f,
+ logit_scale,
+ logit_bias,
+ negative_only=True,
+ )
+ text_features_to_left, text_features_to_right = text_features_recv
+
+ if remainder:
+ text_features_recv = neighbour_exchange_with_grad(
+ left_rank,
+ right_rank,
+ text_features_to_right
+ )
+ loss += self._loss(
+ image_features,
+ text_features_recv,
+ logit_scale,
+ logit_bias,
+ negative_only=True,
+ )
+ elif self.dist_impl == "shift":
+ right_rank = (self.rank + 1) % self.world_size
+ left_rank = (self.rank - 1 + self.world_size) % self.world_size
+ text_features_to_right = text_features
+ for i in range(self.world_size - 1):
+ text_features_from_left = neighbour_exchange_with_grad(
+ left_rank,
+ right_rank,
+ text_features_to_right,
+ )
+ loss += self._loss(
+ image_features,
+ text_features_from_left,
+ logit_scale,
+ logit_bias,
+ negative_only=True,
+ )
+ text_features_to_right = text_features_from_left
+ elif self.dist_impl == "reduce":
+ for i in range(self.world_size):
+ text_from_other = torch.distributed.nn.all_reduce(
+ text_features * (self.rank == i),
+ torch.distributed.ReduceOp.SUM,
+ )
+ loss += float(i != self.rank) * self._loss(
+ image_features,
+ text_from_other,
+ logit_scale,
+ logit_bias,
+ negative_only=True,
+ )
+ elif self.dist_impl == "gather":
+ all_text = torch.distributed.nn.all_gather(text_features)
+ for i in range(self.world_size):
+ loss += float(i != self.rank) * self._loss(
+ image_features,
+ all_text[i],
+ logit_scale,
+ logit_bias,
+ negative_only=True,
+ )
+ else:
+ assert False
+
+ return {"contrastive_loss": loss} if output_dict else loss
diff --git a/src/open_clip/model.py b/src/open_clip/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..50208e95e081661016952273e70e2c7a592d07a7
--- /dev/null
+++ b/src/open_clip/model.py
@@ -0,0 +1,919 @@
+""" CLIP Model
+
+Adapted from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
+"""
+import copy
+import logging
+import math
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch import nn
+from torch.utils.checkpoint import checkpoint
+from functools import partial
+
+from .hf_model import HFTextEncoder
+from .modified_resnet import ModifiedResNet
+from .timm_model import TimmModel
+from .transformer import LayerNormFp32, LayerNorm, QuickGELU, Attention, VisionTransformer, TextTransformer,\
+ text_global_pool
+from .utils import to_2tuple
+
+
+@dataclass
+class CLIPVisionCfg:
+ layers: Union[Tuple[int, int, int, int], int] = 12
+ width: int = 768
+ head_width: int = 64
+ mlp_ratio: float = 4.0
+ patch_size: int = 16
+ image_size: Union[Tuple[int, int], int] = 224
+ in_chans: int = 3
+
+ ls_init_value: Optional[float] = None # layer scale initial value
+ patch_dropout: float = 0. # what fraction of patches to dropout during training (0 would mean disabled and no patches dropped) - 0.5 to 0.75 recommended in the paper for optimal results
+ attentional_pool: bool = False # whether to use attentional pooler in the last embedding layer (overrides pool_type)
+ attn_pooler_queries: int = 256 # n_queries for attentional pooler
+ attn_pooler_heads: int = 8 # n heads for attentional_pooling
+ no_ln_pre: bool = False # disable pre transformer LayerNorm
+ pos_embed_type: str = 'learnable'
+ final_ln_after_pool: bool = False # apply final LayerNorm after pooling
+ pool_type: str = 'tok'
+ output_tokens: bool = False
+ act_kwargs: Optional[dict] = None
+ norm_kwargs: Optional[dict] = None
+
+ timm_model_name: Optional[str] = None # a valid model name overrides layers, width, patch_size
+ timm_model_pretrained: bool = False # use (imagenet) pretrained weights for named model
+ timm_pool: str = 'avg' # feature pooling for timm model ('abs_attn', 'rot_attn', 'avg', '')
+ timm_proj: str = 'linear' # linear projection for timm model output ('linear', 'mlp', '')
+ timm_proj_bias: bool = False # enable bias final projection
+ timm_drop: float = 0. # head dropout
+ timm_drop_path: Optional[float] = None # backbone stochastic depth
+
+
+@dataclass
+class CLIPTextCfg:
+ context_length: int = 77
+ vocab_size: int = 49408
+ hf_tokenizer_name: Optional[str] = None
+ tokenizer_kwargs: Optional[dict] = None
+
+ width: int = 512
+ heads: int = 8
+ layers: int = 12
+ mlp_ratio: float = 4.0
+ ls_init_value: Optional[float] = None # layer scale initial value
+ embed_cls: bool = False
+ pad_id: int = 0
+ no_causal_mask: bool = False # disable causal masking
+ final_ln_after_pool: bool = False # apply final LayerNorm after pooling
+ pool_type: str = 'argmax'
+ proj_bias: bool = False
+ proj_type: str = 'linear' # control final text projection, 'none' forces no projection
+ output_tokens: bool = False
+ act_kwargs: dict = None
+ norm_kwargs: dict = None
+
+ # HuggingFace specific text tower config
+ hf_model_name: Optional[str] = None
+ hf_model_pretrained: bool = True
+ hf_proj_type: str = 'mlp'
+ hf_pooler_type: str = 'mean_pooler' # attentional pooling for HF models
+
+
+def get_cast_dtype(precision: str):
+ cast_dtype = None
+ if precision == 'bf16':
+ cast_dtype = torch.bfloat16
+ elif precision == 'fp16':
+ cast_dtype = torch.float16
+ return cast_dtype
+
+
+def get_input_dtype(precision: str):
+ input_dtype = None
+ if precision in ('bf16', 'pure_bf16'):
+ input_dtype = torch.bfloat16
+ elif precision in ('fp16', 'pure_fp16'):
+ input_dtype = torch.float16
+ return input_dtype
+
+
+def _build_vision_tower(
+ embed_dim: int,
+ vision_cfg: CLIPVisionCfg,
+ quick_gelu: bool = False,
+ cast_dtype: Optional[torch.dtype] = None
+):
+ if isinstance(vision_cfg, dict):
+ vision_cfg = CLIPVisionCfg(**vision_cfg)
+
+ # OpenAI models are pretrained w/ QuickGELU but native nn.GELU is both faster and more
+ # memory efficient in recent PyTorch releases (>= 1.10).
+ # NOTE: timm models always use native GELU regardless of quick_gelu flag.
+ act_layer = QuickGELU if quick_gelu else nn.GELU
+
+ if vision_cfg.timm_model_name:
+ visual = TimmModel(
+ vision_cfg.timm_model_name,
+ pretrained=vision_cfg.timm_model_pretrained,
+ pool=vision_cfg.timm_pool,
+ proj=vision_cfg.timm_proj,
+ proj_bias=vision_cfg.timm_proj_bias,
+ drop=vision_cfg.timm_drop,
+ drop_path=vision_cfg.timm_drop_path,
+ patch_drop=vision_cfg.patch_dropout if vision_cfg.patch_dropout > 0 else None,
+ embed_dim=embed_dim,
+ image_size=vision_cfg.image_size,
+ )
+ elif isinstance(vision_cfg.layers, (tuple, list)):
+ vision_heads = vision_cfg.width * 32 // vision_cfg.head_width
+ visual = ModifiedResNet(
+ layers=vision_cfg.layers,
+ output_dim=embed_dim,
+ heads=vision_heads,
+ image_size=vision_cfg.image_size,
+ width=vision_cfg.width,
+ )
+ else:
+ vision_heads = vision_cfg.width // vision_cfg.head_width
+ norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
+ if vision_cfg.norm_kwargs:
+ norm_layer = partial(norm_layer, **vision_cfg.norm_kwargs)
+ if vision_cfg.act_kwargs is not None:
+ act_layer = partial(act_layer, **vision_cfg.act_kwargs)
+
+ visual = VisionTransformer(
+ image_size=vision_cfg.image_size,
+ patch_size=vision_cfg.patch_size,
+ width=vision_cfg.width,
+ layers=vision_cfg.layers,
+ heads=vision_heads,
+ mlp_ratio=vision_cfg.mlp_ratio,
+ ls_init_value=vision_cfg.ls_init_value,
+ patch_dropout=vision_cfg.patch_dropout,
+ attentional_pool=vision_cfg.attentional_pool,
+ attn_pooler_queries=vision_cfg.attn_pooler_queries,
+ attn_pooler_heads=vision_cfg.attn_pooler_heads,
+ pos_embed_type=vision_cfg.pos_embed_type,
+ no_ln_pre=vision_cfg.no_ln_pre,
+ final_ln_after_pool=vision_cfg.final_ln_after_pool,
+ pool_type=vision_cfg.pool_type,
+ output_tokens=vision_cfg.output_tokens,
+ output_dim=embed_dim,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ in_chans=vision_cfg.in_chans,
+ )
+
+ return visual
+
+
+def _build_text_tower(
+ embed_dim: int,
+ text_cfg: CLIPTextCfg,
+ quick_gelu: bool = False,
+ cast_dtype: Optional[torch.dtype] = None,
+):
+ if isinstance(text_cfg, dict):
+ text_cfg = CLIPTextCfg(**text_cfg)
+
+ if text_cfg.hf_model_name:
+ text = HFTextEncoder(
+ text_cfg.hf_model_name,
+ output_dim=embed_dim,
+ proj_type=text_cfg.hf_proj_type,
+ pooler_type=text_cfg.hf_pooler_type,
+ pretrained=text_cfg.hf_model_pretrained,
+ output_tokens=text_cfg.output_tokens,
+ )
+ else:
+ act_layer = QuickGELU if quick_gelu else nn.GELU
+ norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
+ if text_cfg.norm_kwargs:
+ norm_layer = partial(norm_layer, **text_cfg.norm_kwargs)
+ if text_cfg.act_kwargs is not None:
+ act_layer = partial(act_layer, **text_cfg.act_kwargs)
+
+ text = TextTransformer(
+ context_length=text_cfg.context_length,
+ vocab_size=text_cfg.vocab_size,
+ width=text_cfg.width,
+ heads=text_cfg.heads,
+ layers=text_cfg.layers,
+ mlp_ratio=text_cfg.mlp_ratio,
+ ls_init_value=text_cfg.ls_init_value,
+ output_dim=embed_dim,
+ embed_cls=text_cfg.embed_cls,
+ no_causal_mask=text_cfg.no_causal_mask,
+ pad_id=text_cfg.pad_id,
+ pool_type=text_cfg.pool_type,
+ proj_type=text_cfg.proj_type,
+ proj_bias=text_cfg.proj_bias,
+ output_tokens=text_cfg.output_tokens,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ )
+ return text
+
+
+
+class TrunkNet(nn.Module):
+ def __init__(self, input_dim: int, hidden_dim: int, output_dim: int):
+ super().__init__()
+ self.net = nn.Sequential(
+ nn.Linear(input_dim, hidden_dim),
+ LayerNorm(hidden_dim),
+ nn.GELU(),
+ nn.Linear(hidden_dim, hidden_dim),
+ LayerNorm(hidden_dim),
+ nn.GELU(),
+ nn.Linear(hidden_dim, output_dim)
+ )
+
+ def forward(self, x):
+
+ for i, layer in enumerate(self.net):
+ x = layer(x)
+
+ return x
+
+
+class MultiTrunkNet(nn.Module):
+ def __init__(self, embed_dim: int):
+ super().__init__()
+ self.embed_dim = embed_dim
+
+ self.compound_trunk = TrunkNet(input_dim=159, hidden_dim=embed_dim, output_dim=embed_dim)
+ self.concentration_trunk = TrunkNet(input_dim=2, hidden_dim=embed_dim, output_dim=embed_dim)
+ self.time_trunk = TrunkNet(input_dim=1, hidden_dim=embed_dim, output_dim=embed_dim)
+
+ total_dim = embed_dim * 3
+ self.projection = nn.Linear(total_dim, embed_dim)
+
+ def forward(self, compound_embedding: torch.Tensor, concentration: torch.Tensor, time: torch.Tensor):
+
+ # Process each input through its own trunk
+ compound_features = self.compound_trunk(compound_embedding)
+
+ concentration_features = self.concentration_trunk(concentration)
+
+ time = time.unsqueeze(-1) if time.dim() == 1 else time
+ time_features = self.time_trunk(time)
+
+ # Concatenate all features
+ return compound_features, concentration_features, time_features
+
+
+class CLIP(nn.Module):
+ output_dict: torch.jit.Final[bool]
+
+ def __init__(
+ self,
+ embed_dim: int,
+ vision_cfg: CLIPVisionCfg,
+ text_cfg: CLIPTextCfg,
+ quick_gelu: bool = False,
+ init_logit_scale: float = np.log(1 / 0.07),
+ init_logit_bias: Optional[float] = None,
+ nonscalar_logit_scale: bool = False,
+ cast_dtype: Optional[torch.dtype] = None,
+ output_dict: bool = False,
+ ):
+ super().__init__()
+ self.output_dict = output_dict
+
+ self.visual = _build_vision_tower(embed_dim, vision_cfg, quick_gelu, cast_dtype)
+
+ text = _build_text_tower(int(embed_dim/4), text_cfg, quick_gelu, cast_dtype)
+ self.transformer = text.transformer
+ self.context_length = text.context_length
+ self.vocab_size = text.vocab_size
+ self.token_embedding = text.token_embedding
+ self.positional_embedding = text.positional_embedding
+ self.ln_final = text.ln_final
+ self.text_projection = text.text_projection
+ self.text_pool_type = text.pool_type
+ self.register_buffer('attn_mask', text.attn_mask, persistent=False)
+
+ # Add multi-trunk net for additional inputs
+ self.multi_trunk = MultiTrunkNet(int(embed_dim/4))
+
+ # # Add projection layer for concatenated features
+ # self.fusion_projection = nn.Linear(embed_dim * 4, embed_dim)
+
+ lshape = [1] if nonscalar_logit_scale else []
+ self.logit_scale = nn.Parameter(torch.ones(lshape) * init_logit_scale)
+ if init_logit_bias is not None:
+ self.logit_bias = nn.Parameter(torch.ones(lshape) * init_logit_bias)
+ else:
+ self.logit_bias = None
+
+ def lock_image_tower(self, unlocked_groups=0, freeze_bn_stats=False):
+ # lock image tower as per LiT - https://arxiv.org/abs/2111.07991
+ self.visual.lock(unlocked_groups=unlocked_groups, freeze_bn_stats=freeze_bn_stats)
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable=True):
+ self.visual.set_grad_checkpointing(enable)
+ self.transformer.grad_checkpointing = enable
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ # for timm optimizers, 1d params like logit_scale, logit_bias, ln/bn scale, biases are excluded by default
+ no_wd = {'positional_embedding'}
+ if hasattr(self.visual, 'no_weight_decay'):
+ for n in self.visual.no_weight_decay():
+ no_wd.add('visual.' + n)
+ return no_wd
+
+ def encode_image(self, image, normalize: bool = False):
+ features = self.visual(image)
+ return F.normalize(features, dim=-1) if normalize else features
+
+ def encode_text(self, text, normalize: bool = False, concentration: Optional[torch.Tensor] = None,
+ time: Optional[torch.Tensor] = None, compound_embedding: Optional[torch.Tensor] = None):
+ cast_dtype = self.transformer.get_cast_dtype()
+
+ x = self.token_embedding(text).to(cast_dtype)
+ x = x + self.positional_embedding.to(cast_dtype)
+ x = self.transformer(x, attn_mask=self.attn_mask)
+ x = self.ln_final(x)
+ x = text_global_pool(x, text, self.text_pool_type)
+
+ if self.text_projection is not None:
+ if isinstance(self.text_projection, nn.Linear):
+ x = self.text_projection(x)
+ else:
+ x = x @ self.text_projection
+
+ if compound_embedding is not None and concentration is not None and time is not None:
+ compound_features, concentration_features, time_features = self.multi_trunk(compound_embedding, concentration, time)
+ x = torch.cat([x, compound_features, concentration_features, time_features], dim=-1)
+
+ if normalize:
+ x = F.normalize(x, dim=-1)
+
+ return x
+
+ def get_logits(self, image, text, concentration: Optional[torch.Tensor] = None,
+ time: Optional[torch.Tensor] = None,
+ compound_embedding: Optional[torch.Tensor] = None):
+ image_features = self.encode_image(image, normalize=True)
+ text_features = self.encode_text(text, normalize=True,
+ concentration=concentration,
+ time=time,
+ compound_embedding=compound_embedding)
+ image_logits = self.logit_scale.exp() * image_features @ text_features.T
+ if self.logit_bias is not None:
+ image_logits += self.logit_bias
+ text_logits = image_logits.T
+ return image_logits, text_logits
+
+ def forward_intermediates(
+ self,
+ image: Optional[torch.Tensor] = None,
+ text: Optional[torch.Tensor] = None,
+ image_indices: Optional[Union[int, List[int]]] = None,
+ text_indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize: bool = True,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ image_output_fmt: str = 'NCHW',
+ image_output_extra_tokens: bool = False,
+ text_output_fmt: str = 'NLC',
+ text_output_extra_tokens: bool = False,
+ output_logits: bool = False,
+ output_logit_scale_bias: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ image: Input image tensor
+ text: Input text tensor
+ image_indices: For image tower, Take last n blocks if int, all if None, select matching indices if sequence
+ text_indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize_intermediates: Apply final norm layer to all intermediates
+ normalize: L2 Normalize final features
+ intermediates_only: Only return intermediate features, do not return final features
+ image_output_fmt: Shape of intermediate image feature outputs
+ image_output_extra_tokens: Return both prefix and spatial intermediate tokens
+ text_output_fmt: Shape of intermediate text feature outputs (ignored for this model)
+ text_output_extra_tokens: Return both prefix and spatial intermediate tokens (ignored for this model)
+ output_logits: Include logits in output
+ output_logit_scale_bias: Include the logit scale bias in the output
+ Returns:
+
+ """
+ output = {}
+ if intermediates_only:
+ # intermediates only disables final feature normalization, and include logits
+ normalize = False
+ output_logits = False
+ if output_logits:
+ assert image is not None and text is not None, 'Both image and text inputs are required to compute logits'
+
+ if image is not None:
+ image_output = self.visual.forward_intermediates(
+ image,
+ indices=image_indices,
+ stop_early=stop_early,
+ normalize_intermediates=normalize_intermediates,
+ intermediates_only=intermediates_only,
+ output_fmt=image_output_fmt,
+ output_extra_tokens=image_output_extra_tokens,
+ )
+ if normalize and "image_features" in image_output:
+ image_output["image_features"] = F.normalize(image_output["image_features"], dim=-1)
+ output.update(image_output)
+
+ if text is not None:
+ cast_dtype = self.transformer.get_cast_dtype()
+ x = self.token_embedding(text).to(cast_dtype) # [batch_size, n_ctx, d_model]
+ x = x + self.positional_embedding.to(cast_dtype)
+ x, intermediates = self.transformer.forward_intermediates(
+ x,
+ attn_mask=self.attn_mask,
+ indices=text_indices
+ )
+ if normalize_intermediates:
+ intermediates = [self.ln_final(xi) for xi in intermediates]
+
+ # NOTE this model doesn't support cls embed in text transformer, no need for extra intermediate tokens
+ output["text_intermediates"] = intermediates
+
+ if not intermediates_only:
+ x = self.ln_final(x) # [batch_size, n_ctx, transformer.width]
+ x = text_global_pool(x, text, self.text_pool_type)
+ if self.text_projection is not None:
+ if isinstance(self.text_projection, nn.Linear):
+ x = self.text_projection(x)
+ else:
+ x = x @ self.text_projection
+ if normalize:
+ x = F.normalize(x, dim=-1)
+ output["text_features"] = x
+
+ logit_scale_exp = self.logit_scale.exp() if output_logits or output_logit_scale_bias else None
+
+ if output_logits:
+ image_logits = logit_scale_exp * output["image_features"] @ output["text_features"].T
+ if self.logit_bias is not None:
+ image_logits += self.logit_bias
+ text_logits = image_logits.T
+ output["image_logits"] = image_logits
+ output["text_logits"] = text_logits
+
+ if output_logit_scale_bias:
+ output["logit_scale"] = logit_scale_exp
+ if self.logit_bias is not None:
+ output['logit_bias'] = self.logit_bias
+
+ return output
+
+
+ def forward(
+ self,
+ image: Optional[torch.Tensor] = None,
+ text: Optional[torch.Tensor] = None,
+ concentration: Optional[torch.Tensor] = None,
+ time: Optional[torch.Tensor] = None,
+ compound_embedding: Optional[torch.Tensor] = None,
+ ):
+
+ image_features = self.encode_image(image, normalize=True) if image is not None else None
+ text_features = self.encode_text(text, normalize=True, concentration=concentration, time=time, compound_embedding=compound_embedding)
+ if self.output_dict:
+ out_dict = {
+ "image_features": image_features,
+ "text_features": text_features,
+ "logit_scale": self.logit_scale.exp()
+ }
+ if self.logit_bias is not None:
+ out_dict['logit_bias'] = self.logit_bias
+ return out_dict
+
+ if self.logit_bias is not None:
+ return image_features, text_features, self.logit_scale.exp(), self.logit_bias
+ return image_features, text_features, self.logit_scale.exp()
+
+
+class CustomTextCLIP(nn.Module):
+ output_dict: torch.jit.Final[bool]
+
+ def __init__(
+ self,
+ embed_dim: int,
+ vision_cfg: CLIPVisionCfg,
+ text_cfg: CLIPTextCfg,
+ quick_gelu: bool = False,
+ init_logit_scale: float = np.log(1 / 0.07),
+ init_logit_bias: Optional[float] = None,
+ nonscalar_logit_scale: bool = False,
+ cast_dtype: Optional[torch.dtype] = None,
+ output_dict: bool = False,
+ ):
+ super().__init__()
+ self.output_dict = output_dict
+ self.visual = _build_vision_tower(embed_dim, vision_cfg, quick_gelu, cast_dtype)
+ self.text = _build_text_tower(embed_dim, text_cfg, quick_gelu, cast_dtype)
+ self.context_length = self.text.context_length
+ self.vocab_size = self.text.vocab_size
+
+ lshape = [1] if nonscalar_logit_scale else []
+ self.logit_scale = nn.Parameter(torch.ones(lshape) * init_logit_scale)
+ if init_logit_bias is not None:
+ self.logit_bias = nn.Parameter(torch.ones(lshape) * init_logit_bias)
+ else:
+ self.logit_bias = None
+
+ def lock_image_tower(self, unlocked_groups=0, freeze_bn_stats=False):
+ # lock image tower as per LiT - https://arxiv.org/abs/2111.07991
+ self.visual.lock(unlocked_groups=unlocked_groups, freeze_bn_stats=freeze_bn_stats)
+
+ def lock_text_tower(self, unlocked_layers: int = 0, freeze_layer_norm: bool = True):
+ self.text.lock(unlocked_layers, freeze_layer_norm)
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable=True):
+ self.visual.set_grad_checkpointing(enable)
+ self.text.set_grad_checkpointing(enable)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ # for timm optimizers, 1d params like logit_scale, logit_bias, ln/bn scale, biases are excluded by default
+ no_wd = set()
+ if hasattr(self.visual, 'no_weight_decay'):
+ for n in self.visual.no_weight_decay():
+ no_wd.add('visual.' + n)
+ if hasattr(self.text, 'no_weight_decay'):
+ for n in self.visual.no_weight_decay():
+ no_wd.add('text.' + n)
+ return no_wd
+
+ def encode_image(self, image, normalize: bool = False):
+ features = self.visual(image)
+ return F.normalize(features, dim=-1) if normalize else features
+
+ def encode_text(self, text, normalize: bool = False):
+ features = self.text(text)
+ return F.normalize(features, dim=-1) if normalize else features
+
+ def get_logits(self, image, text):
+ image_features = self.encode_image(image, normalize=True)
+ text_features = self.encode_text(text, normalize=True)
+ image_logits = self.logit_scale.exp() * image_features @ text_features.T
+ if self.logit_bias is not None:
+ image_logits += self.logit_bias
+ text_logits = image_logits.T
+ return image_logits, text_logits
+
+ def forward_intermediates(
+ self,
+ image: Optional[torch.Tensor] = None,
+ text: Optional[torch.Tensor] = None,
+ image_indices: Optional[Union[int, List[int]]] = None,
+ text_indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize: bool = True,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ image_output_fmt: str = 'NCHW',
+ image_output_extra_tokens: bool = False,
+ text_output_fmt: str = 'NLC',
+ text_output_extra_tokens: bool = False,
+ output_logits: bool = False,
+ output_logit_scale_bias: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ image: Input image tensor
+ text: Input text tensor
+ image_indices: For image tower, Take last n blocks if int, all if None, select matching indices if sequence
+ text_indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize: L2 Normalize final image and text features (if present)
+ normalize_intermediates: Apply final encoder norm layer to all intermediates (if possible)
+ intermediates_only: Only return intermediate features, do not return final features
+ image_output_fmt: Shape of intermediate image feature outputs
+ image_output_extra_tokens: Return both prefix and spatial intermediate tokens
+ text_output_fmt: Shape of intermediate text feature outputs
+ text_output_extra_tokens: Return both prefix and spatial intermediate tokens
+ output_logits: Include logits in output
+ output_logit_scale_bias: Include the logit scale bias in the output
+ Returns:
+
+ """
+ output = {}
+ if intermediates_only:
+ # intermediates only disables final feature normalization, and include logits
+ normalize = False
+ output_logits = False
+ if output_logits:
+ assert image is not None and text is not None, 'Both image and text inputs are required to compute logits'
+
+ if image is not None:
+ image_output = self.visual.forward_intermediates(
+ image,
+ indices=image_indices,
+ stop_early=stop_early,
+ normalize_intermediates=normalize_intermediates,
+ intermediates_only=intermediates_only,
+ output_fmt=image_output_fmt,
+ output_extra_tokens=image_output_extra_tokens,
+ )
+ if normalize and "image_features" in image_output:
+ image_output["image_features"] = F.normalize(image_output["image_features"], dim=-1)
+ output.update(image_output)
+
+ if text is not None:
+ text_output = self.text.forward_intermediates(
+ text,
+ indices=text_indices,
+ stop_early=stop_early,
+ normalize_intermediates=normalize_intermediates,
+ intermediates_only=intermediates_only,
+ output_fmt=text_output_fmt,
+ output_extra_tokens=text_output_extra_tokens,
+ )
+ if normalize and "text_features" in text_output:
+ text_output["text_features"] = F.normalize(text_output["text_features"], dim=-1)
+ output.update(text_output)
+
+ logit_scale_exp = self.logit_scale.exp() if output_logits or output_logit_scale_bias else None
+
+ if output_logits:
+ image_logits = logit_scale_exp * output["image_features"] @ output["text_features"].T
+ if self.logit_bias is not None:
+ image_logits += self.logit_bias
+ text_logits = image_logits.T
+ output["image_logits"] = image_logits
+ output["text_logits"] = text_logits
+
+ if output_logit_scale_bias:
+ output["logit_scale"] = logit_scale_exp
+ if self.logit_bias is not None:
+ output['logit_bias'] = self.logit_bias
+
+ return output
+
+ def forward(
+ self,
+ image: Optional[torch.Tensor] = None,
+ text: Optional[torch.Tensor] = None,
+ ):
+ image_features = self.encode_image(image, normalize=True) if image is not None else None
+ text_features = self.encode_text(text, normalize=True) if text is not None else None
+
+ if self.output_dict:
+ out_dict = {
+ "image_features": image_features,
+ "text_features": text_features,
+ "logit_scale": self.logit_scale.exp()
+ }
+ if self.logit_bias is not None:
+ out_dict['logit_bias'] = self.logit_bias
+ return out_dict
+
+ if self.logit_bias is not None:
+ return image_features, text_features, self.logit_scale.exp(), self.logit_bias
+ return image_features, text_features, self.logit_scale.exp()
+
+
+def convert_weights_to_lp(model: nn.Module, dtype=torch.float16):
+ """Convert applicable model parameters to low-precision (bf16 or fp16)"""
+
+ def _convert_weights(l):
+ if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
+ l.weight.data = l.weight.data.to(dtype)
+ if l.bias is not None:
+ l.bias.data = l.bias.data.to(dtype)
+
+ if isinstance(l, (nn.MultiheadAttention, Attention)):
+ for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
+ tensor = getattr(l, attr)
+ if tensor is not None:
+ tensor.data = tensor.data.to(dtype)
+
+ if isinstance(l, (CLIP, TextTransformer)):
+ # convert text nn.Parameter projections
+ attr = getattr(l, "text_projection", None)
+ if attr is not None:
+ attr.data = attr.data.to(dtype)
+
+ if isinstance(l, VisionTransformer):
+ # convert vision nn.Parameter projections
+ attr = getattr(l, "proj", None)
+ if attr is not None:
+ attr.data = attr.data.to(dtype)
+
+ model.apply(_convert_weights)
+
+
+convert_weights_to_fp16 = convert_weights_to_lp # backwards compat
+
+
+# used to maintain checkpoint compatibility
+def convert_to_custom_text_state_dict(state_dict: dict):
+ if 'text_projection' in state_dict:
+ # old format state_dict, move text tower -> .text
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ if any(k.startswith(p) for p in (
+ 'text_projection',
+ 'positional_embedding',
+ 'token_embedding',
+ 'transformer',
+ 'ln_final',
+ )):
+ k = 'text.' + k
+ new_state_dict[k] = v
+ return new_state_dict
+ return state_dict
+
+
+def build_model_from_openai_state_dict(
+ state_dict: dict,
+ quick_gelu=True,
+ cast_dtype=torch.float16,
+):
+ vit = "visual.proj" in state_dict
+
+ if vit:
+ vision_width = state_dict["visual.conv1.weight"].shape[0]
+ vision_layers = len(
+ [k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
+ vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
+ grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
+ image_size = vision_patch_size * grid_size
+ else:
+ counts: list = [
+ len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
+ vision_layers = tuple(counts)
+ vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
+ output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
+ vision_patch_size = None
+ assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
+ image_size = output_width * 32
+
+ embed_dim = state_dict["text_projection"].shape[1]
+ context_length = state_dict["positional_embedding"].shape[0]
+ vocab_size = state_dict["token_embedding.weight"].shape[0]
+ transformer_width = state_dict["ln_final.weight"].shape[0]
+ transformer_heads = transformer_width // 64
+ transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
+
+ vision_cfg = CLIPVisionCfg(
+ layers=vision_layers,
+ width=vision_width,
+ patch_size=vision_patch_size,
+ image_size=image_size,
+ )
+ text_cfg = CLIPTextCfg(
+ context_length=context_length,
+ vocab_size=vocab_size,
+ width=transformer_width,
+ heads=transformer_heads,
+ layers=transformer_layers,
+ )
+ model = CLIP(
+ embed_dim,
+ vision_cfg=vision_cfg,
+ text_cfg=text_cfg,
+ quick_gelu=quick_gelu, # OpenAI models were trained with QuickGELU
+ cast_dtype=cast_dtype,
+ )
+
+ for key in ["input_resolution", "context_length", "vocab_size"]:
+ state_dict.pop(key, None)
+ convert_weights_to_fp16(model) # OpenAI state dicts are partially converted to float16
+ model.load_state_dict(state_dict)
+ return model.eval()
+
+
+def trace_model(model, batch_size=256, device=torch.device('cpu')):
+ model.eval()
+ image_size = model.visual.image_size
+ example_images = torch.ones((batch_size, 2, image_size, image_size), device=device)
+ example_text = torch.zeros((batch_size, model.context_length), dtype=torch.int, device=device)
+ example_concentration = torch.rand((batch_size, 2), device=device)
+ example_time = torch.rand((batch_size, 1), device=device)
+ example_compound_embedding = torch.rand((batch_size, 159), device=device)
+ model = torch.jit.trace_module(
+ model,
+ inputs=dict(
+ forward=(example_images, example_text, example_concentration, example_time, example_compound_embedding),
+ encode_text=(example_text, True, example_concentration, example_time, example_compound_embedding),
+ encode_image=(example_images,)
+ ))
+ model.visual.image_size = image_size
+ return model
+
+
+def resize_pos_embed(state_dict, model, interpolation: str = 'bicubic', antialias: bool = True):
+ # Rescale the grid of position embeddings when loading from state_dict
+ old_pos_embed = state_dict.get('visual.positional_embedding', None)
+ if old_pos_embed is None or not hasattr(model.visual, 'grid_size'):
+ return
+ grid_size = to_2tuple(model.visual.grid_size)
+ extra_tokens = 1 # FIXME detect different token configs (ie no class token, or more)
+ new_seq_len = grid_size[0] * grid_size[1] + extra_tokens
+ if new_seq_len == old_pos_embed.shape[0]:
+ return
+
+ if extra_tokens:
+ pos_emb_tok, pos_emb_img = old_pos_embed[:extra_tokens], old_pos_embed[extra_tokens:]
+ else:
+ pos_emb_tok, pos_emb_img = None, old_pos_embed
+ old_grid_size = to_2tuple(int(math.sqrt(len(pos_emb_img))))
+
+ logging.info('Resizing position embedding grid-size from %s to %s', old_grid_size, grid_size)
+ pos_emb_img = pos_emb_img.reshape(1, old_grid_size[0], old_grid_size[1], -1).permute(0, 3, 1, 2)
+ pos_emb_img = F.interpolate(
+ pos_emb_img,
+ size=grid_size,
+ mode=interpolation,
+ antialias=antialias,
+ align_corners=False,
+ )
+ pos_emb_img = pos_emb_img.permute(0, 2, 3, 1).reshape(1, grid_size[0] * grid_size[1], -1)[0]
+ if pos_emb_tok is not None:
+ new_pos_embed = torch.cat([pos_emb_tok, pos_emb_img], dim=0)
+ else:
+ new_pos_embed = pos_emb_img
+ state_dict['visual.positional_embedding'] = new_pos_embed
+
+
+def resize_text_pos_embed(state_dict, model, interpolation: str = 'linear', antialias: bool = False):
+ old_pos_embed = state_dict.get('positional_embedding', None)
+ if old_pos_embed is None:
+ return
+ # FIXME add support for text cls_token
+ model_pos_embed = getattr(model, 'positional_embedding', None)
+ if model_pos_embed is None:
+ model_pos_embed = getattr(model.text, 'positional_embedding', None)
+
+ old_num_pos = old_pos_embed.shape[0]
+ old_width = old_pos_embed.shape[1]
+ num_pos = model_pos_embed.shape[0]
+ width = model_pos_embed.shape[1]
+ assert old_width == width, 'text pos_embed width changed!'
+ if old_num_pos == num_pos:
+ return
+
+ logging.info('Resizing text position embedding num_pos from %s to %s', old_num_pos, num_pos)
+ old_pos_embed = old_pos_embed.reshape(1, old_num_pos, old_width).permute(0, 2, 1)
+ old_pos_embed = F.interpolate(
+ old_pos_embed,
+ size=num_pos,
+ mode=interpolation,
+ antialias=antialias,
+ align_corners=False,
+ )
+ old_pos_embed = old_pos_embed.permute(0, 2, 1)[0]
+ new_pos_embed = old_pos_embed
+
+ state_dict['positional_embedding'] = new_pos_embed
+
+
+def get_model_preprocess_cfg(model):
+ module = getattr(model, 'visual', model)
+ preprocess_cfg = getattr(module, 'preprocess_cfg', {})
+ if not preprocess_cfg:
+ # use separate legacy attributes if preprocess_cfg dict not found
+ size = getattr(module, 'image_size')
+ if size is not None:
+ preprocess_cfg['size'] = size
+ mean = getattr(module, 'image_mean', None)
+ if mean is not None:
+ preprocess_cfg['mean'] = mean
+ std = getattr(module, 'image_std', None)
+ if std is not None:
+ preprocess_cfg['std'] = std
+ return preprocess_cfg
+
+
+def set_model_preprocess_cfg(model, preprocess_cfg: Dict[str, Any]):
+ module = getattr(model, 'visual', model)
+ module.image_mean = preprocess_cfg['mean'] # legacy attribute, keeping for bwd compat
+ module.image_std = preprocess_cfg['std'] # legacy attribute, keeping for bwd compat
+ module.preprocess_cfg = copy.deepcopy(preprocess_cfg) # new attr, package all pp cfg as dict
+
+
+def get_model_tokenize_cfg(model):
+ module = getattr(model, 'text', model)
+ cfg = {}
+ context_length = getattr(module, 'context_length', None)
+ if context_length is not None:
+ cfg['context_length'] = context_length
+ vocab_size = getattr(module, 'vocab_size', None)
+ if vocab_size is not None:
+ cfg['vocab_size'] = vocab_size
+ return cfg
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA01-g-14-plus.json b/src/open_clip/model_configs/EVA01-g-14-plus.json
new file mode 100644
index 0000000000000000000000000000000000000000..73f46a71e664fce987218b8eb48903e7bd895f41
--- /dev/null
+++ b/src/open_clip/model_configs/EVA01-g-14-plus.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva_giant_patch14_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA01-g-14.json b/src/open_clip/model_configs/EVA01-g-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..9d0e80f290d9491b7c46fafd576201b1258165aa
--- /dev/null
+++ b/src/open_clip/model_configs/EVA01-g-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva_giant_patch14_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA02-B-16.json b/src/open_clip/model_configs/EVA02-B-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..3f92357287e1f6600da1e7f391cb6370d7f66de4
--- /dev/null
+++ b/src/open_clip/model_configs/EVA02-B-16.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva02_base_patch16_clip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA02-E-14-plus.json b/src/open_clip/model_configs/EVA02-E-14-plus.json
new file mode 100644
index 0000000000000000000000000000000000000000..e250c2a404c86ff168c54cfcf71bc2492be1b74c
--- /dev/null
+++ b/src/open_clip/model_configs/EVA02-E-14-plus.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva02_enormous_patch14_clip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1280,
+ "heads": 20,
+ "layers": 32
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA02-E-14.json b/src/open_clip/model_configs/EVA02-E-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..4b6648e25092b151a9095e0a66956c7ebf835b16
--- /dev/null
+++ b/src/open_clip/model_configs/EVA02-E-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva02_enormous_patch14_clip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA02-L-14-336.json b/src/open_clip/model_configs/EVA02-L-14-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..2bb07f3c082fd88c4e86131b272163aaacfaef9e
--- /dev/null
+++ b/src/open_clip/model_configs/EVA02-L-14-336.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 336,
+ "timm_model_name": "eva02_large_patch14_clip_336",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/EVA02-L-14.json b/src/open_clip/model_configs/EVA02-L-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..b4c7f377bc543aa92a145358f2630a58ae9be989
--- /dev/null
+++ b/src/open_clip/model_configs/EVA02-L-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "eva02_large_patch14_clip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/MobileCLIP-B.json b/src/open_clip/model_configs/MobileCLIP-B.json
new file mode 100644
index 0000000000000000000000000000000000000000..9907d86b37a60918405e5e3f2cf237bad889a0ce
--- /dev/null
+++ b/src/open_clip/model_configs/MobileCLIP-B.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "vit_base_mci_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "token",
+ "timm_proj": null,
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.0,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "no_causal_mask": false
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/MobileCLIP-S1.json b/src/open_clip/model_configs/MobileCLIP-S1.json
new file mode 100644
index 0000000000000000000000000000000000000000..80780c5eac6f3f9e7b09bc891abb63599e4464f3
--- /dev/null
+++ b/src/open_clip/model_configs/MobileCLIP-S1.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "fastvit_mci1",
+ "timm_model_pretrained": false,
+ "timm_pool": "avg",
+ "timm_proj": null,
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.0,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "no_causal_mask": true
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/MobileCLIP-S2.json b/src/open_clip/model_configs/MobileCLIP-S2.json
new file mode 100644
index 0000000000000000000000000000000000000000..66ebc16aaab350091f29c8330c15ead59c228609
--- /dev/null
+++ b/src/open_clip/model_configs/MobileCLIP-S2.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "fastvit_mci2",
+ "timm_model_pretrained": false,
+ "timm_pool": "avg",
+ "timm_proj": null,
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.0,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "no_causal_mask": true
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN101-quickgelu.json b/src/open_clip/model_configs/RN101-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..d0db2c161d13138788c4609d373b023b8454d624
--- /dev/null
+++ b/src/open_clip/model_configs/RN101-quickgelu.json
@@ -0,0 +1,22 @@
+{
+ "embed_dim": 512,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": [
+ 3,
+ 4,
+ 23,
+ 3
+ ],
+ "width": 64,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN101.json b/src/open_clip/model_configs/RN101.json
new file mode 100644
index 0000000000000000000000000000000000000000..b88b4d3acbaa701c614ab0ea65fc88fcfe289c32
--- /dev/null
+++ b/src/open_clip/model_configs/RN101.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": [
+ 3,
+ 4,
+ 23,
+ 3
+ ],
+ "width": 64,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50-quickgelu.json b/src/open_clip/model_configs/RN50-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..8c2f91260cdeb043434dc1e893cce81d4ce7f0d1
--- /dev/null
+++ b/src/open_clip/model_configs/RN50-quickgelu.json
@@ -0,0 +1,22 @@
+{
+ "embed_dim": 1024,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": [
+ 3,
+ 4,
+ 6,
+ 3
+ ],
+ "width": 64,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
diff --git a/src/open_clip/model_configs/RN50.json b/src/open_clip/model_configs/RN50.json
new file mode 100644
index 0000000000000000000000000000000000000000..33aa884d54fee0076c33676831e49d5e1ffcb8f2
--- /dev/null
+++ b/src/open_clip/model_configs/RN50.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": [
+ 3,
+ 4,
+ 6,
+ 3
+ ],
+ "width": 64,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x16-quickgelu.json b/src/open_clip/model_configs/RN50x16-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..989bb87c669a31e2b82e9902f9d6f24d825c6b03
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x16-quickgelu.json
@@ -0,0 +1,22 @@
+{
+ "embed_dim": 768,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "layers": [
+ 6,
+ 8,
+ 18,
+ 8
+ ],
+ "width": 96,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x16.json b/src/open_clip/model_configs/RN50x16.json
new file mode 100644
index 0000000000000000000000000000000000000000..3161e1a2c9a839161e652a4d729c2cdc971161db
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x16.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 384,
+ "layers": [
+ 6,
+ 8,
+ 18,
+ 8
+ ],
+ "width": 96,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x4-quickgelu.json b/src/open_clip/model_configs/RN50x4-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..9bf11fc3afabf0072df3e1e6b9d1677852c9b262
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x4-quickgelu.json
@@ -0,0 +1,22 @@
+{
+ "embed_dim": 640,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 288,
+ "layers": [
+ 4,
+ 6,
+ 10,
+ 6
+ ],
+ "width": 80,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x4.json b/src/open_clip/model_configs/RN50x4.json
new file mode 100644
index 0000000000000000000000000000000000000000..e155237f8ce1026aaaeecc80751eabe6f329f0bb
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x4.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "image_size": 288,
+ "layers": [
+ 4,
+ 6,
+ 10,
+ 6
+ ],
+ "width": 80,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x64-quickgelu.json b/src/open_clip/model_configs/RN50x64-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..6da9d7e219b8e3ed233909055308f994187ebae7
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x64-quickgelu.json
@@ -0,0 +1,22 @@
+{
+ "embed_dim": 1024,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 448,
+ "layers": [
+ 3,
+ 15,
+ 36,
+ 10
+ ],
+ "width": 128,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/RN50x64.json b/src/open_clip/model_configs/RN50x64.json
new file mode 100644
index 0000000000000000000000000000000000000000..f5aaa2ee3de21ddb03cbd12766a3419bf34898c7
--- /dev/null
+++ b/src/open_clip/model_configs/RN50x64.json
@@ -0,0 +1,21 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 448,
+ "layers": [
+ 3,
+ 15,
+ 36,
+ 10
+ ],
+ "width": 128,
+ "patch_size": null
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP-256.json b/src/open_clip/model_configs/ViT-B-16-SigLIP-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..d7ad3acba6bd37701ff8f19ca5f791c6342b73d6
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP-256.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_base_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP-384.json b/src/open_clip/model_configs/ViT-B-16-SigLIP-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..df9a25cdca5207a8954801c0f2cf28514c15a1cd
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP-384.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_base_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP-512.json b/src/open_clip/model_configs/ViT-B-16-SigLIP-512.json
new file mode 100644
index 0000000000000000000000000000000000000000..88b018528b2e7806cd11b95d5808136786ea0f97
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP-512.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 512,
+ "timm_model_name": "vit_base_patch16_siglip_512",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP-i18n-256.json b/src/open_clip/model_configs/ViT-B-16-SigLIP-i18n-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..7a28797a7e1487af986540872447a68da0dd69b2
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP-i18n-256.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_base_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 250000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP-i18n-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP.json b/src/open_clip/model_configs/ViT-B-16-SigLIP.json
new file mode 100644
index 0000000000000000000000000000000000000000..a9f2b654a671c9bd235f351b2a253ca889758549
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "vit_base_patch16_siglip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP2-256.json b/src/open_clip/model_configs/ViT-B-16-SigLIP2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..adc3e62a04ec6f6913bc0dbf5030b84952ed602a
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP2-256.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_base_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP2-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP2-384.json b/src/open_clip/model_configs/ViT-B-16-SigLIP2-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..5a1c445b71d25084eb8b76d82d7ec2c87769f128
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP2-384.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_base_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP2-384",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP2-512.json b/src/open_clip/model_configs/ViT-B-16-SigLIP2-512.json
new file mode 100644
index 0000000000000000000000000000000000000000..913ff0ccd88bbfac0b5e3d4195334ed35c44ccf3
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP2-512.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 512,
+ "timm_model_name": "vit_base_patch16_siglip_512",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP2-512",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-SigLIP2.json b/src/open_clip/model_configs/ViT-B-16-SigLIP2.json
new file mode 100644
index 0000000000000000000000000000000000000000..ae5ff69d5a1ae39785c601f36b37625696a19511
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-SigLIP2.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "vit_base_patch16_siglip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP2",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-plus-240.json b/src/open_clip/model_configs/ViT-B-16-plus-240.json
new file mode 100644
index 0000000000000000000000000000000000000000..5bbd12bcd01f64d6d0a0aa8316b129327a0d169a
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-plus-240.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "image_size": 240,
+ "layers": 12,
+ "width": 896,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-plus.json b/src/open_clip/model_configs/ViT-B-16-plus.json
new file mode 100644
index 0000000000000000000000000000000000000000..5dc1e09baccef2b15055c1bffeb9903e760101c6
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-plus.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 896,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16-quickgelu.json b/src/open_clip/model_configs/ViT-B-16-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..ff5431ea3065d18094de94d3c87d8814d3f651fe
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16-quickgelu.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-16.json b/src/open_clip/model_configs/ViT-B-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..9b348a57e777c7871345f389373b8e4182a25bbc
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-16.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 512,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 16,
+ "in_chans": 2
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-32-256.json b/src/open_clip/model_configs/ViT-B-32-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..80a2597d8f7d5d500df2aacbded9507196dad6da
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-32-256.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 256,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
diff --git a/src/open_clip/model_configs/ViT-B-32-SigLIP2-256.json b/src/open_clip/model_configs/ViT-B-32-SigLIP2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..a88d6bd621ff146d1969bc2c0affd246d8a4b8bd
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-32-SigLIP2-256.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 768,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_base_patch32_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-B-32-SigLIP2-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
diff --git a/src/open_clip/model_configs/ViT-B-32-plus-256.json b/src/open_clip/model_configs/ViT-B-32-plus-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..2f09c857de9a4c01ae51297a7e2451984879f9de
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-32-plus-256.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "image_size": 256,
+ "layers": 12,
+ "width": 896,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-32-quickgelu.json b/src/open_clip/model_configs/ViT-B-32-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..ce6bd923593293ed50dfcfb28b73ca7403bcf3c5
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-32-quickgelu.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-B-32.json b/src/open_clip/model_configs/ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..b05134a4da5a4f42f66109f5b71e23ffc7cc636c
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-B-32.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 512,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32,
+ "in_chans": 2
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14-378-quickgelu.json b/src/open_clip/model_configs/ViT-H-14-378-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..e2b2ecf9ae278eeb4f6b20d16e17a6523f961580
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14-378-quickgelu.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 378,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14-378.json b/src/open_clip/model_configs/ViT-H-14-378.json
new file mode 100644
index 0000000000000000000000000000000000000000..04b2e62d60d031b1a5762e365e070e52b6fea7b1
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14-378.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 378,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14-CLIPA-336.json b/src/open_clip/model_configs/ViT-H-14-CLIPA-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..01fabb29db2bcbd9513e903064d61e3e1974d580
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14-CLIPA-336.json
@@ -0,0 +1,26 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 336,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14-CLIPA.json b/src/open_clip/model_configs/ViT-H-14-CLIPA.json
new file mode 100644
index 0000000000000000000000000000000000000000..7df0338844bfff4d30f3ca08711311f645dda866
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14-CLIPA.json
@@ -0,0 +1,26 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14-quickgelu.json b/src/open_clip/model_configs/ViT-H-14-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..41f22f65bb002c320111790e0cd0f2425a575df7
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14-quickgelu.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-14.json b/src/open_clip/model_configs/ViT-H-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..3e3a7e934e7f02e41f4829996c4950e05f015a74
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-14.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-H-16.json b/src/open_clip/model_configs/ViT-H-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..78e5ebdb26acf45ac2d48ecad8b8f581974c30a2
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-H-16.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 512,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 16,
+ "in_chans": 2
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-280.json b/src/open_clip/model_configs/ViT-L-14-280.json
new file mode 100644
index 0000000000000000000000000000000000000000..2262deaefa82792d35d73c0d7c8e620525092581
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-280.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 280,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-336-quickgelu.json b/src/open_clip/model_configs/ViT-L-14-336-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..d928c0284c692dfe738be8cbf4a0e2eb939bcf41
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-336-quickgelu.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 768,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 336,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-336.json b/src/open_clip/model_configs/ViT-L-14-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..8d1f74c2639c3a3705df9865b9c08215675ddc97
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-336.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 336,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-CLIPA-336.json b/src/open_clip/model_configs/ViT-L-14-CLIPA-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..60a4df589b9e9ed269807204ec9788e613026382
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-CLIPA-336.json
@@ -0,0 +1,25 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 336,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-CLIPA.json b/src/open_clip/model_configs/ViT-L-14-CLIPA.json
new file mode 100644
index 0000000000000000000000000000000000000000..b4dde7b546b6c53d5c55f2abe50b599ff2519964
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-CLIPA.json
@@ -0,0 +1,25 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14-quickgelu.json b/src/open_clip/model_configs/ViT-L-14-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..d5a3fd36aa9cd9cc4a3dc29e362945cec13a02f3
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14-quickgelu.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 768,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-14.json b/src/open_clip/model_configs/ViT-L-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..d4a4bbb1dd4ed4edb317d3ace4f3ad13b211c241
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-14.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-320.json b/src/open_clip/model_configs/ViT-L-16-320.json
new file mode 100644
index 0000000000000000000000000000000000000000..fc2d13ca9ec7f0b56a886ddaf66c4a7ba7a442ba
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-320.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 320,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-SigLIP-256.json b/src/open_clip/model_configs/ViT-L-16-SigLIP-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..5ba8f7abb68e5a798d38f976a828c63f74b94ae8
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-SigLIP-256.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 1024,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_large_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-SigLIP-384.json b/src/open_clip/model_configs/ViT-L-16-SigLIP-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..fd2cc2e346f7110a5de01cfaf7eae8c94360de3a
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-SigLIP-384.json
@@ -0,0 +1,29 @@
+{
+ "embed_dim": 1024,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_large_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-SigLIP2-256.json b/src/open_clip/model_configs/ViT-L-16-SigLIP2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..32f248ba7370117fb06107229b72e819a7302c24
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-SigLIP2-256.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 1024,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_large_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-L-16-SigLIP2-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-SigLIP2-384.json b/src/open_clip/model_configs/ViT-L-16-SigLIP2-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..888dfcc57b1762bec9a779de00887d1dd7c23c8d
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-SigLIP2-384.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 1024,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_large_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-L-16-SigLIP2-384",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16-SigLIP2-512.json b/src/open_clip/model_configs/ViT-L-16-SigLIP2-512.json
new file mode 100644
index 0000000000000000000000000000000000000000..f3ba25fe770321c683aae1314e48ef67f62f8134
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16-SigLIP2-512.json
@@ -0,0 +1,32 @@
+{
+ "embed_dim": 1024,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 512,
+ "timm_model_name": "vit_large_patch16_siglip_512",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-L-16-SigLIP2-512",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1024,
+ "heads": 16,
+ "layers": 24,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-L-16.json b/src/open_clip/model_configs/ViT-L-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..0163fd15fe139000316ce23f1f7cc05fa029617c
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-L-16.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 512,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 16,
+ "in_chans": 2
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-M-16-alt.json b/src/open_clip/model_configs/ViT-M-16-alt.json
new file mode 100644
index 0000000000000000000000000000000000000000..1a317aad8e02d9c26d2decc7cc49a18dfdf9e0d8
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-M-16-alt.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 384,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 512,
+ "patch_size": 16,
+ "ls_init_value": 1e-4
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 384,
+ "heads": 6,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-M-16.json b/src/open_clip/model_configs/ViT-M-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..f2f3225a46e09237730a151d161f70c86b985172
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-M-16.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 512,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-M-32-alt.json b/src/open_clip/model_configs/ViT-M-32-alt.json
new file mode 100644
index 0000000000000000000000000000000000000000..fd222aeac0f582ef6a1a33f1b3fec70a5b386ac0
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-M-32-alt.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 384,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 512,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 384,
+ "heads": 6,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-M-32.json b/src/open_clip/model_configs/ViT-M-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..4f718642821035d9776d1e006817d65ede074366
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-M-32.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 512,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-S-16-alt.json b/src/open_clip/model_configs/ViT-S-16-alt.json
new file mode 100644
index 0000000000000000000000000000000000000000..a8c056555e4da3ba0d1475a61fc316362ecce76f
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-S-16-alt.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 256,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 384,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 256,
+ "heads": 4,
+ "layers": 10
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-S-16.json b/src/open_clip/model_configs/ViT-S-16.json
new file mode 100644
index 0000000000000000000000000000000000000000..1d8504e59658803f3093e5b05de45f30a09b8185
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-S-16.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 384,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 384,
+ "patch_size": 16
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 384,
+ "heads": 6,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-S-32-alt.json b/src/open_clip/model_configs/ViT-S-32-alt.json
new file mode 100644
index 0000000000000000000000000000000000000000..e1dfdec9824df09a2010e991ccfa1d9ee2f45807
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-S-32-alt.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 256,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 384,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 256,
+ "heads": 4,
+ "layers": 10
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-S-32.json b/src/open_clip/model_configs/ViT-S-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..9b8b4191b268de267268cfcb90fc01c6b9df07d8
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-S-32.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 384,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 384,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 384,
+ "heads": 6,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-378.json b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-378.json
new file mode 100644
index 0000000000000000000000000000000000000000..6bc14fabc30a9e11cbc9ca53d353f2d1216f9d2c
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-378.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 378,
+ "timm_model_name": "vit_so400m_patch14_siglip_378",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-384.json b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..4c527f581230938d7b39baf36b6bd749b0e7f169
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP-384.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_so400m_patch14_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-14-SigLIP.json b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP.json
new file mode 100644
index 0000000000000000000000000000000000000000..564eb78a49c8ff31cac047277b9344bbe85fef40
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "vit_so400m_patch14_siglip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 16,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2-378.json b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2-378.json
new file mode 100644
index 0000000000000000000000000000000000000000..2497712413300dc269247ef100e321a5b63f5de6
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2-378.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 378,
+ "timm_model_name": "vit_so400m_patch14_siglip_378",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-SO400M-14-SigLIP2-378",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2.json b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2.json
new file mode 100644
index 0000000000000000000000000000000000000000..b77eb316a632180ff1ca0077e8a6192286beeb17
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-14-SigLIP2.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "timm_model_name": "vit_so400m_patch14_siglip_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-SO400M-14-SigLIP2",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-16-SigLIP-i18n-256.json b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP-i18n-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..4e39b1b46fa2d2b8616c013bf8f972e2047a31c7
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP-i18n-256.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_so400m_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 250000,
+ "hf_tokenizer_name": "timm/ViT-B-16-SigLIP-i18n-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "pool_type": "last",
+ "proj_type": "none",
+ "norm_kwargs":{
+ "eps": 1e-6
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-256.json b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..c8b70931f8f804847270deb2ffbd4eb447e08e2d
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-256.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_so400m_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-SO400M-16-SigLIP2-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-384.json b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..628e8af01057a320b567a83418532afa7a5f366f
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-384.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_so400m_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-SO400M-16-SigLIP2-384",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-512.json b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-512.json
new file mode 100644
index 0000000000000000000000000000000000000000..f5d2c191d3877b7130a10980ce3f79d6cc3c32d1
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-SO400M-16-SigLIP2-512.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1152,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 512,
+ "timm_model_name": "vit_so400m_patch16_siglip_512",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-SO400M-16-SigLIP2-512",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-bigG-14-CLIPA-336.json b/src/open_clip/model_configs/ViT-bigG-14-CLIPA-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..75ba7675c643cd482f06886e58ded6fb934233fc
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-bigG-14-CLIPA-336.json
@@ -0,0 +1,27 @@
+{
+ "embed_dim": 1280,
+ "vision_cfg": {
+ "image_size": 336,
+ "layers": 48,
+ "width": 1664,
+ "head_width": 104,
+ "mlp_ratio": 4.9231,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 1280,
+ "heads": 20,
+ "layers": 32,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-bigG-14-CLIPA.json b/src/open_clip/model_configs/ViT-bigG-14-CLIPA.json
new file mode 100644
index 0000000000000000000000000000000000000000..83ec709f8b8362d892067adafde9a0d78ce4db14
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-bigG-14-CLIPA.json
@@ -0,0 +1,27 @@
+{
+ "embed_dim": 1280,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 48,
+ "width": 1664,
+ "head_width": 104,
+ "mlp_ratio": 4.9231,
+ "patch_size": 14,
+ "no_ln_pre": true,
+ "pool_type": "avg",
+ "final_ln_after_pool": true
+ },
+ "text_cfg": {
+ "context_length": 32,
+ "vocab_size": 32000,
+ "hf_tokenizer_name": "bert-base-uncased",
+ "tokenizer_kwargs": {
+ "strip_sep_token": true
+ },
+ "width": 1280,
+ "heads": 20,
+ "layers": 32,
+ "pool_type": "last",
+ "no_causal_mask": true
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-bigG-14-quickgelu.json b/src/open_clip/model_configs/ViT-bigG-14-quickgelu.json
new file mode 100644
index 0000000000000000000000000000000000000000..fed567cc670274e50e7ecd69954097cca1d5b081
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-bigG-14-quickgelu.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 1280,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 48,
+ "width": 1664,
+ "head_width": 104,
+ "mlp_ratio": 4.9231,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1280,
+ "heads": 20,
+ "layers": 32
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-bigG-14.json b/src/open_clip/model_configs/ViT-bigG-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..2cfba479a2e8f3737e71ce240732bf3bc743d8b7
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-bigG-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1280,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 48,
+ "width": 1664,
+ "head_width": 104,
+ "mlp_ratio": 4.9231,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1280,
+ "heads": 20,
+ "layers": 32
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-e-14.json b/src/open_clip/model_configs/ViT-e-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..91a0fe14d25a107fb8ec48dd7faae313fd26ed7b
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-e-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1280,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 56,
+ "width": 1792,
+ "head_width": 112,
+ "mlp_ratio": 8.5715,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1280,
+ "heads": 20,
+ "layers": 36
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-g-14.json b/src/open_clip/model_configs/ViT-g-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..8c4b7325cc75b6112be7107d36ae2cb5762d9091
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-g-14.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 40,
+ "width": 1408,
+ "head_width": 88,
+ "mlp_ratio": 4.3637,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-256.json b/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..df1ec2db3b3d33012c28826848dc081a0915eb7f
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-256.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1536,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 256,
+ "timm_model_name": "vit_giantopt_patch16_siglip_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-gopt-16-SigLIP2-256",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-384.json b/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..d31ab5b2d47dc46e832e062b05e2098674c7f870
--- /dev/null
+++ b/src/open_clip/model_configs/ViT-gopt-16-SigLIP2-384.json
@@ -0,0 +1,33 @@
+{
+ "embed_dim": 1536,
+ "init_logit_bias": -10,
+ "custom_text": true,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_giantopt_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "context_length": 64,
+ "vocab_size": 256000,
+ "hf_tokenizer_name": "timm/ViT-gopt-16-SigLIP2-384",
+ "tokenizer_kwargs": {
+ "clean": "canonicalize"
+ },
+ "width": 1152,
+ "heads": 16,
+ "layers": 27,
+ "mlp_ratio": 3.7362,
+ "no_causal_mask": true,
+ "proj_bias": true,
+ "pool_type": "last",
+ "norm_kwargs":{
+ "eps": 1e-6
+ },
+ "act_kwargs": {
+ "approximate": "tanh"
+ }
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-B-LTT.json b/src/open_clip/model_configs/ViTamin-B-LTT.json
new file mode 100644
index 0000000000000000000000000000000000000000..775621409becce43a1b1aa5bd61cdaf93c578733
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-B-LTT.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_base_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-B.json b/src/open_clip/model_configs/ViTamin-B.json
new file mode 100644
index 0000000000000000000000000000000000000000..bf09a8e698b2f133f531d1567755e9f9d3510047
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-B.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_base_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L-256.json b/src/open_clip/model_configs/ViTamin-L-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..66990842e98241bcc269f06e21ed78c9f94c235d
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L-256.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L-336.json b/src/open_clip/model_configs/ViTamin-L-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..63aa8cebef0f19d5276e99b104380b01f0a8c58e
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L-336.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large_336",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 336
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L-384.json b/src/open_clip/model_configs/ViTamin-L-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..1278d8393686b9818c7635c2ec3e97a4ae5e57e9
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L-384.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 384
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
diff --git a/src/open_clip/model_configs/ViTamin-L.json b/src/open_clip/model_configs/ViTamin-L.json
new file mode 100644
index 0000000000000000000000000000000000000000..c74e56e9df1b5548863ef42a3a08f12fb28f09bd
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L2-256.json b/src/open_clip/model_configs/ViTamin-L2-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..68465befbe72ab02dd31248fd322fd8d1950d2d0
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L2-256.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large2_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L2-336.json b/src/open_clip/model_configs/ViTamin-L2-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..4b48a526322de8c23912e258019c1737fb9336c8
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L2-336.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large2_336",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 336
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-L2-384.json b/src/open_clip/model_configs/ViTamin-L2-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..cc0faaae7b3a17f571b91fa98b0748261ad16fcd
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L2-384.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large2_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 384
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
diff --git a/src/open_clip/model_configs/ViTamin-L2.json b/src/open_clip/model_configs/ViTamin-L2.json
new file mode 100644
index 0000000000000000000000000000000000000000..3d14b710906775c89143b9f227bc38414ee9ad11
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-L2.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_large2_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-S-LTT.json b/src/open_clip/model_configs/ViTamin-S-LTT.json
new file mode 100644
index 0000000000000000000000000000000000000000..b01c95b4132620e3908716f3a549e398b7d5089e
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-S-LTT.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_small_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-S.json b/src/open_clip/model_configs/ViTamin-S.json
new file mode 100644
index 0000000000000000000000000000000000000000..1fb6cd24a681500d94284b29f645595ca2727e2a
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-S.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 384,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_small_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 384,
+ "heads": 6,
+ "layers": 12
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-XL-256.json b/src/open_clip/model_configs/ViTamin-XL-256.json
new file mode 100644
index 0000000000000000000000000000000000000000..68f672f0cc3c3564f4c7ec6e25255034e5af45cb
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-XL-256.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1152,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_xlarge_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1152,
+ "heads": 16,
+ "layers": 27
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-XL-336.json b/src/open_clip/model_configs/ViTamin-XL-336.json
new file mode 100644
index 0000000000000000000000000000000000000000..116c30e7301a5b7c3869c7adf3ecf6fc82436c17
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-XL-336.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1152,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_xlarge_336",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 336
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1152,
+ "heads": 16,
+ "layers": 27
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/ViTamin-XL-384.json b/src/open_clip/model_configs/ViTamin-XL-384.json
new file mode 100644
index 0000000000000000000000000000000000000000..3070f70e7ec62308fc1aa373f123bc57c2c21451
--- /dev/null
+++ b/src/open_clip/model_configs/ViTamin-XL-384.json
@@ -0,0 +1,20 @@
+{
+ "embed_dim": 1152,
+ "vision_cfg": {
+ "timm_model_name": "vitamin_xlarge_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1152,
+ "heads": 16,
+ "layers": 27
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/coca_ViT-B-32.json b/src/open_clip/model_configs/coca_ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..7e7eb520a6a0096e5602d509ecd6186e278f4725
--- /dev/null
+++ b/src/open_clip/model_configs/coca_ViT-B-32.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32,
+ "attentional_pool": true,
+ "attn_pooler_heads": 8,
+ "output_tokens": true
+ },
+ "text_cfg": {
+ "context_length": 76,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "embed_cls": true,
+ "output_tokens": true
+ },
+ "multimodal_cfg": {
+ "context_length": 76,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12,
+ "attn_pooler_heads": 8
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/coca_ViT-L-14.json b/src/open_clip/model_configs/coca_ViT-L-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..3d5ca4ca2338540f06852df5ff35ea6277e64555
--- /dev/null
+++ b/src/open_clip/model_configs/coca_ViT-L-14.json
@@ -0,0 +1,30 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 24,
+ "width": 1024,
+ "patch_size": 14,
+ "attentional_pool": true,
+ "attn_pooler_heads": 8,
+ "output_tokens": true
+ },
+ "text_cfg": {
+ "context_length": 76,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "embed_cls": true,
+ "output_tokens": true
+ },
+ "multimodal_cfg": {
+ "context_length": 76,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12,
+ "attn_pooler_heads": 12
+ },
+ "custom_text": true
+}
diff --git a/src/open_clip/model_configs/coca_base.json b/src/open_clip/model_configs/coca_base.json
new file mode 100644
index 0000000000000000000000000000000000000000..cf8c6cecb78a49d7e7140145a0307cbd561077c2
--- /dev/null
+++ b/src/open_clip/model_configs/coca_base.json
@@ -0,0 +1,31 @@
+{
+ "embed_dim": 512,
+ "multimodal_cfg": {
+ "width": 768,
+ "context_length": 76,
+ "vocab_size": 64000,
+ "mlp_ratio": 4,
+ "layers": 12,
+ "dim_head": 64,
+ "heads": 12,
+ "n_queries": 256,
+ "attn_pooler_heads": 8
+ },
+ "vision_cfg": {
+ "image_size": 288,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 18,
+ "output_tokens": true
+ },
+ "text_cfg": {
+ "context_length": 76,
+ "vocab_size": 64000,
+ "layers": 12,
+ "heads": 12,
+ "width": 768,
+ "embed_cls": true,
+ "output_tokens": true
+ },
+ "custom_text": true
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/coca_roberta-ViT-B-32.json b/src/open_clip/model_configs/coca_roberta-ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..aa9d3f562057f849e6ced8b495de2dd73387fe61
--- /dev/null
+++ b/src/open_clip/model_configs/coca_roberta-ViT-B-32.json
@@ -0,0 +1,24 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32,
+ "output_tokens": true
+ },
+ "text_cfg": {
+ "hf_model_name": "roberta-base",
+ "hf_tokenizer_name": "roberta-base",
+ "hf_proj_type": "linear",
+ "width": 768,
+ "output_tokens": true
+ },
+ "multimodal_cfg": {
+ "context_length": 76,
+ "width": 768,
+ "heads": 8,
+ "layers": 12
+ },
+ "custom_text": true
+}
diff --git a/src/open_clip/model_configs/convnext_base.json b/src/open_clip/model_configs/convnext_base.json
new file mode 100644
index 0000000000000000000000000000000000000000..bb6dba181d950ea5081155c90d47e72c94816b80
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_base.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "convnext_base",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_base_w.json b/src/open_clip/model_configs/convnext_base_w.json
new file mode 100644
index 0000000000000000000000000000000000000000..82ea7ae3659e5514f37ff982f0ab1141dff4bd18
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_base_w.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "timm_model_name": "convnext_base",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_base_w_320.json b/src/open_clip/model_configs/convnext_base_w_320.json
new file mode 100644
index 0000000000000000000000000000000000000000..0a07c4e16abaa4015ecc5f82ec845de16e1f9d88
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_base_w_320.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "timm_model_name": "convnext_base",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 320
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_large.json b/src/open_clip/model_configs/convnext_large.json
new file mode 100644
index 0000000000000000000000000000000000000000..c4a1fea73dbead71c218a0e74b9b15f9b252e3ef
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_large.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "convnext_large",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_large_d.json b/src/open_clip/model_configs/convnext_large_d.json
new file mode 100644
index 0000000000000000000000000000000000000000..ae8fed21b58e1a6a411daf8b792ee50f0ab42346
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_large_d.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "convnext_large",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "mlp",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 16
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_large_d_320.json b/src/open_clip/model_configs/convnext_large_d_320.json
new file mode 100644
index 0000000000000000000000000000000000000000..54c3df36a6f56ace0b12ada24c13058de96feed8
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_large_d_320.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 768,
+ "vision_cfg": {
+ "timm_model_name": "convnext_large",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "mlp",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 320
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 768,
+ "heads": 12,
+ "layers": 16
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_small.json b/src/open_clip/model_configs/convnext_small.json
new file mode 100644
index 0000000000000000000000000000000000000000..3592c2a5cd21aae8d2544931773cf7603f67ea28
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_small.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "convnext_small",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_tiny.json b/src/open_clip/model_configs/convnext_tiny.json
new file mode 100644
index 0000000000000000000000000000000000000000..ad11470f5ec40ffec771096971ce58d3d5b9249b
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_tiny.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "convnext_tiny",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_xlarge.json b/src/open_clip/model_configs/convnext_xlarge.json
new file mode 100644
index 0000000000000000000000000000000000000000..2a909965932eef994177c829fefc2bdc1c219b3f
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_xlarge.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "convnext_xlarge",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 20
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_xxlarge.json b/src/open_clip/model_configs/convnext_xxlarge.json
new file mode 100644
index 0000000000000000000000000000000000000000..23a55a681c346d1a315d8a163c1cb6ad495e6a91
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_xxlarge.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "convnext_xxlarge",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/convnext_xxlarge_320.json b/src/open_clip/model_configs/convnext_xxlarge_320.json
new file mode 100644
index 0000000000000000000000000000000000000000..ac5134ca12cbaa97772cde059270d345386a74c7
--- /dev/null
+++ b/src/open_clip/model_configs/convnext_xxlarge_320.json
@@ -0,0 +1,19 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "timm_model_name": "convnext_xxlarge",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "timm_drop": 0.0,
+ "timm_drop_path": 0.1,
+ "image_size": 320
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 1024,
+ "heads": 16,
+ "layers": 24
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/mt5-base-ViT-B-32.json b/src/open_clip/model_configs/mt5-base-ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..e22366897aa0a6719a09ff4dc168ef9724a3486c
--- /dev/null
+++ b/src/open_clip/model_configs/mt5-base-ViT-B-32.json
@@ -0,0 +1,14 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "hf_model_name": "google/mt5-base",
+ "hf_tokenizer_name": "google/mt5-base",
+ "hf_pooler_type": "mean_pooler"
+ }
+}
diff --git a/src/open_clip/model_configs/mt5-xl-ViT-H-14.json b/src/open_clip/model_configs/mt5-xl-ViT-H-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..f58717cdd5d4980ca2e099d15d5ee1ab7623c230
--- /dev/null
+++ b/src/open_clip/model_configs/mt5-xl-ViT-H-14.json
@@ -0,0 +1,15 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "hf_model_name": "google/mt5-xl",
+ "hf_tokenizer_name": "google/mt5-xl",
+ "hf_pooler_type": "mean_pooler"
+ }
+}
diff --git a/src/open_clip/model_configs/nllb-clip-base-siglip.json b/src/open_clip/model_configs/nllb-clip-base-siglip.json
new file mode 100644
index 0000000000000000000000000000000000000000..f7152d0bb6b9fd3333b46cb75934e500f1aab348
--- /dev/null
+++ b/src/open_clip/model_configs/nllb-clip-base-siglip.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 768,
+ "custom_text": true,
+ "init_logit_bias": -10,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_base_patch16_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "hf_model_name": "facebook/nllb-200-distilled-600M",
+ "hf_tokenizer_name": "facebook/nllb-200-distilled-600M",
+ "hf_proj_type": "linear",
+ "hf_pooler_type": "cls_pooler"
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/nllb-clip-base.json b/src/open_clip/model_configs/nllb-clip-base.json
new file mode 100644
index 0000000000000000000000000000000000000000..57265b33f7cfd21b07741744d50cbf30208017d1
--- /dev/null
+++ b/src/open_clip/model_configs/nllb-clip-base.json
@@ -0,0 +1,15 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "hf_model_name": "facebook/nllb-200-distilled-600M",
+ "hf_tokenizer_name": "facebook/nllb-200-distilled-600M",
+ "hf_proj_type": "linear",
+ "hf_pooler_type": "cls_pooler"
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/nllb-clip-large-siglip.json b/src/open_clip/model_configs/nllb-clip-large-siglip.json
new file mode 100644
index 0000000000000000000000000000000000000000..0ac3485762b5117597839b3274ed85340a2c76c2
--- /dev/null
+++ b/src/open_clip/model_configs/nllb-clip-large-siglip.json
@@ -0,0 +1,18 @@
+{
+ "embed_dim": 1152,
+ "custom_text": true,
+ "init_logit_bias": -10,
+ "vision_cfg": {
+ "image_size": 384,
+ "timm_model_name": "vit_so400m_patch14_siglip_384",
+ "timm_model_pretrained": false,
+ "timm_pool": "map",
+ "timm_proj": "none"
+ },
+ "text_cfg": {
+ "hf_model_name": "facebook/nllb-200-distilled-1.3B",
+ "hf_tokenizer_name": "facebook/nllb-200-distilled-1.3B",
+ "hf_proj_type": "linear",
+ "hf_pooler_type": "cls_pooler"
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/nllb-clip-large.json b/src/open_clip/model_configs/nllb-clip-large.json
new file mode 100644
index 0000000000000000000000000000000000000000..72d04a73316e513135581f563c74f8cb69dac1c9
--- /dev/null
+++ b/src/open_clip/model_configs/nllb-clip-large.json
@@ -0,0 +1,16 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "hf_model_name": "facebook/nllb-200-distilled-1.3B",
+ "hf_tokenizer_name": "facebook/nllb-200-distilled-1.3B",
+ "hf_proj_type": "linear",
+ "hf_pooler_type": "cls_pooler"
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/roberta-ViT-B-32.json b/src/open_clip/model_configs/roberta-ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..c0c7a55995d50230c6b0f0af5fbd81d5889a3d59
--- /dev/null
+++ b/src/open_clip/model_configs/roberta-ViT-B-32.json
@@ -0,0 +1,15 @@
+{
+ "embed_dim": 512,
+ "quick_gelu": true,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "hf_model_name": "roberta-base",
+ "hf_tokenizer_name": "roberta-base",
+ "hf_pooler_type": "mean_pooler"
+ }
+}
diff --git a/src/open_clip/model_configs/swin_base_patch4_window7_224.json b/src/open_clip/model_configs/swin_base_patch4_window7_224.json
new file mode 100644
index 0000000000000000000000000000000000000000..bd6820f0cf2aa655e0a2723287f4b78895a58e6a
--- /dev/null
+++ b/src/open_clip/model_configs/swin_base_patch4_window7_224.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 640,
+ "vision_cfg": {
+ "timm_model_name": "swin_base_patch4_window7_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 640,
+ "heads": 10,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/vit_medium_patch16_gap_256.json b/src/open_clip/model_configs/vit_medium_patch16_gap_256.json
new file mode 100644
index 0000000000000000000000000000000000000000..8843eaf08cad16c3e7b5f496fd650715c9573f65
--- /dev/null
+++ b/src/open_clip/model_configs/vit_medium_patch16_gap_256.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "vit_medium_patch16_gap_256",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "image_size": 256
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/vit_relpos_medium_patch16_cls_224.json b/src/open_clip/model_configs/vit_relpos_medium_patch16_cls_224.json
new file mode 100644
index 0000000000000000000000000000000000000000..ed217b202d5e6071c5307f4547c97ff4cfe2abd1
--- /dev/null
+++ b/src/open_clip/model_configs/vit_relpos_medium_patch16_cls_224.json
@@ -0,0 +1,17 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "timm_model_name": "vit_relpos_medium_patch16_cls_224",
+ "timm_model_pretrained": false,
+ "timm_pool": "",
+ "timm_proj": "linear",
+ "image_size": 224
+ },
+ "text_cfg": {
+ "context_length": 77,
+ "vocab_size": 49408,
+ "width": 512,
+ "heads": 8,
+ "layers": 12
+ }
+}
\ No newline at end of file
diff --git a/src/open_clip/model_configs/xlm-roberta-base-ViT-B-32.json b/src/open_clip/model_configs/xlm-roberta-base-ViT-B-32.json
new file mode 100644
index 0000000000000000000000000000000000000000..375fa9e12f1629ef049a715d43ba2a8b1822ff1c
--- /dev/null
+++ b/src/open_clip/model_configs/xlm-roberta-base-ViT-B-32.json
@@ -0,0 +1,14 @@
+{
+ "embed_dim": 512,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 12,
+ "width": 768,
+ "patch_size": 32
+ },
+ "text_cfg": {
+ "hf_model_name": "xlm-roberta-base",
+ "hf_tokenizer_name": "xlm-roberta-base",
+ "hf_pooler_type": "mean_pooler"
+ }
+}
diff --git a/src/open_clip/model_configs/xlm-roberta-large-ViT-H-14.json b/src/open_clip/model_configs/xlm-roberta-large-ViT-H-14.json
new file mode 100644
index 0000000000000000000000000000000000000000..c56b4e89883506ce41d0295d9a700b4a3dd2775f
--- /dev/null
+++ b/src/open_clip/model_configs/xlm-roberta-large-ViT-H-14.json
@@ -0,0 +1,15 @@
+{
+ "embed_dim": 1024,
+ "vision_cfg": {
+ "image_size": 224,
+ "layers": 32,
+ "width": 1280,
+ "head_width": 80,
+ "patch_size": 14
+ },
+ "text_cfg": {
+ "hf_model_name": "xlm-roberta-large",
+ "hf_tokenizer_name": "xlm-roberta-large",
+ "hf_pooler_type": "mean_pooler"
+ }
+}
diff --git a/src/open_clip/modified_resnet.py b/src/open_clip/modified_resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f0ad78f5746bdf1463423b68d94f74c04229d7c
--- /dev/null
+++ b/src/open_clip/modified_resnet.py
@@ -0,0 +1,236 @@
+from collections import OrderedDict
+from typing import Dict, List, Optional, Union
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from .utils import freeze_batch_norm_2d, feature_take_indices
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1):
+ super().__init__()
+
+ # all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
+ self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.act1 = nn.ReLU(inplace=True)
+
+ self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.act2 = nn.ReLU(inplace=True)
+
+ self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
+
+ self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
+ self.bn3 = nn.BatchNorm2d(planes * self.expansion)
+ self.act3 = nn.ReLU(inplace=True)
+
+ self.downsample = None
+ self.stride = stride
+
+ if stride > 1 or inplanes != planes * Bottleneck.expansion:
+ # downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
+ self.downsample = nn.Sequential(OrderedDict([
+ ("-1", nn.AvgPool2d(stride)),
+ ("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
+ ("1", nn.BatchNorm2d(planes * self.expansion))
+ ]))
+
+ def forward(self, x: torch.Tensor):
+ identity = x
+
+ out = self.act1(self.bn1(self.conv1(x)))
+ out = self.act2(self.bn2(self.conv2(out)))
+ out = self.avgpool(out)
+ out = self.bn3(self.conv3(out))
+
+ if self.downsample is not None:
+ identity = self.downsample(x)
+
+ out += identity
+ out = self.act3(out)
+ return out
+
+
+class AttentionPool2d(nn.Module):
+ def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
+ super().__init__()
+ self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
+ self.k_proj = nn.Linear(embed_dim, embed_dim)
+ self.q_proj = nn.Linear(embed_dim, embed_dim)
+ self.v_proj = nn.Linear(embed_dim, embed_dim)
+ self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
+ self.num_heads = num_heads
+
+ def forward(self, x):
+ x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3]).permute(2, 0, 1) # NCHW -> (HW)NC
+ x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
+ x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
+ x, _ = F.multi_head_attention_forward(
+ query=x, key=x, value=x,
+ embed_dim_to_check=x.shape[-1],
+ num_heads=self.num_heads,
+ q_proj_weight=self.q_proj.weight,
+ k_proj_weight=self.k_proj.weight,
+ v_proj_weight=self.v_proj.weight,
+ in_proj_weight=None,
+ in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
+ bias_k=None,
+ bias_v=None,
+ add_zero_attn=False,
+ dropout_p=0.,
+ out_proj_weight=self.c_proj.weight,
+ out_proj_bias=self.c_proj.bias,
+ use_separate_proj_weight=True,
+ training=self.training,
+ need_weights=False
+ )
+
+ return x[0]
+
+
+class ModifiedResNet(nn.Module):
+ """
+ A ResNet class that is similar to torchvision's but contains the following changes:
+ - There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.
+ - Performs antialiasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
+ - The final pooling layer is a QKV attention instead of an average pool
+ """
+
+ def __init__(
+ self,
+ layers: List[int],
+ output_dim: int,
+ heads: int,
+ image_size: int = 224,
+ width: int = 64,
+ ):
+ super().__init__()
+ self.output_dim = output_dim
+ self.image_size = image_size
+
+ # the 3-layer stem
+ self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(width // 2)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
+ self.bn2 = nn.BatchNorm2d(width // 2)
+ self.act2 = nn.ReLU(inplace=True)
+ self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(width)
+ self.act3 = nn.ReLU(inplace=True)
+ self.avgpool = nn.AvgPool2d(2)
+
+ # residual layers
+ self._inplanes = width # this is a *mutable* variable used during construction
+ self.layer1 = self._make_layer(width, layers[0])
+ self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
+ self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
+ self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
+
+ embed_dim = width * 32 # the ResNet feature dimension
+ self.attnpool = AttentionPool2d(image_size // 32, embed_dim, heads, output_dim)
+
+ self.init_parameters()
+
+ def _make_layer(self, planes, blocks, stride=1):
+ layers = [Bottleneck(self._inplanes, planes, stride)]
+
+ self._inplanes = planes * Bottleneck.expansion
+ for _ in range(1, blocks):
+ layers.append(Bottleneck(self._inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def init_parameters(self):
+ if self.attnpool is not None:
+ std = self.attnpool.c_proj.in_features ** -0.5
+ nn.init.normal_(self.attnpool.q_proj.weight, std=std)
+ nn.init.normal_(self.attnpool.k_proj.weight, std=std)
+ nn.init.normal_(self.attnpool.v_proj.weight, std=std)
+ nn.init.normal_(self.attnpool.c_proj.weight, std=std)
+
+ for resnet_block in [self.layer1, self.layer2, self.layer3, self.layer4]:
+ for name, param in resnet_block.named_parameters():
+ if name.endswith("bn3.weight"):
+ nn.init.zeros_(param)
+
+ def lock(self, unlocked_groups=0, freeze_bn_stats=False):
+ assert unlocked_groups == 0, 'partial locking not currently supported for this model'
+ for param in self.parameters():
+ param.requires_grad = False
+ if freeze_bn_stats:
+ freeze_batch_norm_2d(self)
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable=True):
+ # FIXME support for non-transformer
+ pass
+
+ def stem(self, x):
+ x = self.act1(self.bn1(self.conv1(x)))
+ x = self.act2(self.bn2(self.conv2(x)))
+ x = self.act3(self.bn3(self.conv3(x)))
+ x = self.avgpool(x)
+ return x
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ output_fmt: str = 'NCHW',
+ output_extra_tokens: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ x: Input image tensor
+ indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize_intermediates: Apply final norm layer to all intermediates
+ intermediates_only: Only return intermediate features
+ output_fmt: Shape of intermediate feature outputs
+ output_extra_tokens: Return both extra class, eot tokens
+ Returns:
+
+ """
+ assert output_fmt in ('NCHW',), 'Output format must be == NCHW.'
+ # NOTE normalize_intermediates and return_extra_tokens don't apply
+ take_indices, max_index = feature_take_indices(5, indices)
+
+ output = {}
+ intermediates = []
+ blocks = [self.stem, self.layer1, self.layer2, self.layer3, self.layer4]
+ if torch.jit.is_scripting() or not stop_early: # can't slice blocks in torchscript
+ blocks = blocks[:max_index + 1]
+ for i, blk in enumerate(blocks):
+ x = blk(x)
+ if i in take_indices:
+ intermediates.append(x)
+
+ output['image_intermediates'] = intermediates
+
+ if intermediates_only:
+ return output
+
+ x = self.attnpool(x)
+ output['image_features'] = x
+
+ return output
+
+ def forward(self, x):
+ x = self.stem(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+ x = self.attnpool(x)
+
+ return x
diff --git a/src/open_clip/openai.py b/src/open_clip/openai.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c2c0235245c2e4f1217b3b2bfaf2acf78e74981
--- /dev/null
+++ b/src/open_clip/openai.py
@@ -0,0 +1,90 @@
+""" OpenAI pretrained model functions
+
+Adapted from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
+"""
+
+import os
+import warnings
+from typing import List, Optional, Union
+
+import torch
+
+from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
+from .model import build_model_from_openai_state_dict, convert_weights_to_lp, get_cast_dtype
+from .pretrained import get_pretrained_url, list_pretrained_models_by_tag, download_pretrained_from_url
+
+__all__ = ["list_openai_models", "load_openai_model"]
+
+
+def list_openai_models() -> List[str]:
+ """Returns the names of available CLIP models"""
+ return list_pretrained_models_by_tag('openai')
+
+
+def load_openai_model(
+ name: str,
+ precision: Optional[str] = None,
+ device: Optional[Union[str, torch.device]] = None,
+ cache_dir: Optional[str] = None,
+):
+ """Load a CLIP model
+
+ Parameters
+ ----------
+ name : str
+ A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
+ precision: str
+ Model precision, if None defaults to 'fp32' if device == 'cpu' else 'fp16'.
+ device : Union[str, torch.device]
+ The device to put the loaded model
+ cache_dir : Optional[str]
+ The directory to cache the downloaded model weights
+
+ Returns
+ -------
+ model : torch.nn.Module
+ The CLIP model
+ preprocess : Callable[[PIL.Image], torch.Tensor]
+ A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
+ """
+ if device is None:
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ if precision is None:
+ precision = 'fp32' if device == 'cpu' else 'fp16'
+
+ if get_pretrained_url(name, 'openai'):
+ model_path = download_pretrained_from_url(get_pretrained_url(name, 'openai'), cache_dir=cache_dir)
+ elif os.path.isfile(name):
+ model_path = name
+ else:
+ raise RuntimeError(f"Model {name} not found; available models = {list_openai_models()}")
+
+ try:
+ # loading JIT archive
+ model = torch.jit.load(model_path, map_location="cpu").eval()
+ state_dict = None
+ except RuntimeError:
+ # loading saved state dict
+ state_dict = torch.load(model_path, map_location="cpu")
+
+ # Build a non-jit model from the OpenAI jitted model state dict
+ cast_dtype = get_cast_dtype(precision)
+ try:
+ model = build_model_from_openai_state_dict(state_dict or model.state_dict(), cast_dtype=cast_dtype)
+ except KeyError:
+ sd = {k[7:]: v for k, v in state_dict["state_dict"].items()}
+ model = build_model_from_openai_state_dict(sd, cast_dtype=cast_dtype)
+
+ # model from OpenAI state dict is in manually cast fp16 mode, must be converted for AMP/fp32/bf16 use
+ model = model.to(device)
+ # FIXME support pure fp16/bf16 precision modes
+ if precision != 'fp16':
+ model.float()
+ if precision == 'bf16':
+ # for bf16, convert back to low-precision
+ convert_weights_to_lp(model, dtype=torch.bfloat16)
+
+ # add mean / std attributes for consistency with OpenCLIP models
+ model.visual.image_mean = OPENAI_DATASET_MEAN
+ model.visual.image_std = OPENAI_DATASET_STD
+ return model
diff --git a/src/open_clip/pos_embed.py b/src/open_clip/pos_embed.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c8082b34df2318dd25a4ec8346b3f9a888f38de
--- /dev/null
+++ b/src/open_clip/pos_embed.py
@@ -0,0 +1,96 @@
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+# --------------------------------------------------------
+# Position embedding utils
+# --------------------------------------------------------
+
+import numpy as np
+
+import torch
+
+# --------------------------------------------------------
+# 2D sine-cosine position embedding
+# References:
+# Transformer: https://github.com/tensorflow/models/blob/master/official/nlp/transformer/model_utils.py
+# MoCo v3: https://github.com/facebookresearch/moco-v3
+# --------------------------------------------------------
+def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False):
+ """
+ grid_size: int of the grid height and width
+ return:
+ pos_embed: [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
+ """
+ grid_h = np.arange(grid_size, dtype=np.float32)
+ grid_w = np.arange(grid_size, dtype=np.float32)
+ grid = np.meshgrid(grid_w, grid_h) # here w goes first
+ grid = np.stack(grid, axis=0)
+
+ grid = grid.reshape([2, 1, grid_size, grid_size])
+ pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
+ if cls_token:
+ pos_embed = np.concatenate([np.zeros([1, embed_dim]), pos_embed], axis=0)
+ return pos_embed
+
+
+def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
+ assert embed_dim % 2 == 0
+
+ # use half of dimensions to encode grid_h
+ emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
+ emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
+
+ emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
+ return emb
+
+
+def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
+ """
+ embed_dim: output dimension for each position
+ pos: a list of positions to be encoded: size (M,)
+ out: (M, D)
+ """
+ assert embed_dim % 2 == 0
+ omega = np.arange(embed_dim // 2, dtype=float)
+ omega /= embed_dim / 2.
+ omega = 1. / 10000**omega # (D/2,)
+
+ pos = pos.reshape(-1) # (M,)
+ out = np.einsum('m,d->md', pos, omega) # (M, D/2), outer product
+
+ emb_sin = np.sin(out) # (M, D/2)
+ emb_cos = np.cos(out) # (M, D/2)
+
+ emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
+ return emb
+
+
+# --------------------------------------------------------
+# Interpolate position embeddings for high-resolution
+# References:
+# DeiT: https://github.com/facebookresearch/deit
+# --------------------------------------------------------
+def interpolate_pos_embed(model, checkpoint_model):
+ if 'pos_embed' in checkpoint_model:
+ pos_embed_checkpoint = checkpoint_model['pos_embed']
+ embedding_size = pos_embed_checkpoint.shape[-1]
+ num_patches = model.patch_embed.num_patches
+ num_extra_tokens = model.pos_embed.shape[-2] - num_patches
+ # height (== width) for the checkpoint position embedding
+ orig_size = int((pos_embed_checkpoint.shape[-2] - num_extra_tokens) ** 0.5)
+ # height (== width) for the new position embedding
+ new_size = int(num_patches ** 0.5)
+ # class_token and dist_token are kept unchanged
+ if orig_size != new_size:
+ print("Position interpolate from %dx%d to %dx%d" % (orig_size, orig_size, new_size, new_size))
+ extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
+ # only the position tokens are interpolated
+ pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
+ pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size, embedding_size).permute(0, 3, 1, 2)
+ pos_tokens = torch.nn.functional.interpolate(
+ pos_tokens, size=(new_size, new_size), mode='bicubic', align_corners=False)
+ pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
+ new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
+ checkpoint_model['pos_embed'] = new_pos_embed
diff --git a/src/open_clip/pretrained.py b/src/open_clip/pretrained.py
new file mode 100644
index 0000000000000000000000000000000000000000..721f6a23f7f7df9d86bb48f43c2bc913ba9e120e
--- /dev/null
+++ b/src/open_clip/pretrained.py
@@ -0,0 +1,845 @@
+import copy
+import hashlib
+import os
+import urllib
+import warnings
+from functools import partial
+from typing import Dict, Iterable, Optional, Union
+
+from tqdm import tqdm
+
+
+try:
+ import safetensors.torch
+ _has_safetensors = True
+except ImportError:
+ _has_safetensors = False
+
+
+from .constants import (
+ IMAGENET_MEAN,
+ IMAGENET_STD,
+ INCEPTION_MEAN,
+ INCEPTION_STD,
+ OPENAI_DATASET_MEAN,
+ OPENAI_DATASET_STD,
+ HF_WEIGHTS_NAME,
+ HF_SAFE_WEIGHTS_NAME,
+)
+from .version import __version__
+
+try:
+ from huggingface_hub import hf_hub_download
+ hf_hub_download = partial(hf_hub_download, library_name="open_clip", library_version=__version__)
+ _has_hf_hub = True
+except ImportError:
+ hf_hub_download = None
+ _has_hf_hub = False
+
+
+def _pcfg(url='', hf_hub='', **kwargs):
+ # OpenAI / OpenCLIP defaults
+ return {
+ 'url': url,
+ 'hf_hub': hf_hub,
+ 'mean': OPENAI_DATASET_MEAN,
+ 'std': OPENAI_DATASET_STD,
+ 'interpolation': 'bicubic',
+ 'resize_mode': 'shortest',
+ **kwargs,
+ }
+
+
+def _slpcfg(url='', hf_hub='', **kwargs):
+ # SiGLIP defaults
+ return {
+ 'url': url,
+ 'hf_hub': hf_hub,
+ 'mean': INCEPTION_MEAN,
+ 'std': INCEPTION_STD,
+ 'interpolation': 'bicubic',
+ 'resize_mode': 'squash',
+ **kwargs,
+ }
+
+
+def _apcfg(url='', hf_hub='', **kwargs):
+ # CLIPA defaults
+ return {
+ 'url': url,
+ 'hf_hub': hf_hub,
+ 'mean': IMAGENET_MEAN,
+ 'std': IMAGENET_STD,
+ 'interpolation': 'bilinear',
+ 'resize_mode': 'squash',
+ **kwargs,
+ }
+
+
+def _mccfg(url='', hf_hub='', **kwargs):
+ # MobileCLIP
+ return {
+ 'url': url,
+ 'hf_hub': hf_hub,
+ 'mean': (0., 0., 0.),
+ 'std': (1., 1., 1.),
+ 'interpolation': 'bilinear',
+ 'resize_mode': 'shortest',
+ **kwargs,
+ }
+
+
+
+_RN50 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
+ hf_hub="timm/resnet50_clip.openai/",
+ quick_gelu=True,
+ ),
+ yfcc15m=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-yfcc15m-455df137.pt",
+ hf_hub="timm/resnet50_clip.yfcc15m/",
+ quick_gelu=True,
+ ),
+ cc12m=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-cc12m-f000538c.pt",
+ hf_hub="timm/resnet50_clip.cc12m/",
+ quick_gelu=True,
+ ),
+)
+
+_RN101 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
+ hf_hub="timm/resnet101_clip.openai/",
+ quick_gelu=True,
+ ),
+ yfcc15m=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn101-quickgelu-yfcc15m-3e04b30e.pt",
+ hf_hub="timm/resnet101_clip.yfcc15m/",
+ quick_gelu=True,
+ ),
+)
+
+_RN50x4 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
+ hf_hub="timm/resnet50x4_clip.openai/",
+ quick_gelu=True,
+ ),
+)
+
+_RN50x16 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
+ hf_hub="timm/resnet50x16_clip.openai/",
+ quick_gelu=True,
+ ),
+)
+
+_RN50x64 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
+ hf_hub="timm/resnet50x64_clip.openai/",
+ quick_gelu=True,
+ ),
+)
+
+_VITB32 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
+ hf_hub="timm/vit_base_patch32_clip_224.openai/",
+ quick_gelu=True,
+ ),
+ # LAION 400M (quick gelu)
+ laion400m_e31=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_32-quickgelu-laion400m_e31-d867053b.pt",
+ hf_hub="timm/vit_base_patch32_clip_224.laion400m_e31/",
+ quick_gelu=True,
+ ),
+ laion400m_e32=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_32-quickgelu-laion400m_e32-46683a32.pt",
+ hf_hub="timm/vit_base_patch32_clip_224.laion400m_e32/",
+ quick_gelu=True,
+ ),
+ # LAION 2B-en
+ laion2b_e16=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_32-laion2b_e16-af8dbd0c.pth",
+ hf_hub="timm/vit_base_patch32_clip_224.laion2b_e16/",
+ ),
+ laion2b_s34b_b79k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-laion2B-s34B-b79K/'),
+ # DataComp-XL models
+ datacomp_xl_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-DataComp.XL-s13B-b90K/'),
+ # DataComp-M models
+ datacomp_m_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-DataComp.M-s128M-b4K/'),
+ commonpool_m_clip_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M.clip-s128M-b4K/'),
+ commonpool_m_laion_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M.laion-s128M-b4K/'),
+ commonpool_m_image_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M.image-s128M-b4K/'),
+ commonpool_m_text_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M.text-s128M-b4K/'),
+ commonpool_m_basic_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M.basic-s128M-b4K/'),
+ commonpool_m_s128m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.M-s128M-b4K/'),
+ # DataComp-S models
+ datacomp_s_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-DataComp.S-s13M-b4K/'),
+ commonpool_s_clip_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S.clip-s13M-b4K/'),
+ commonpool_s_laion_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S.laion-s13M-b4K/'),
+ commonpool_s_image_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S.image-s13M-b4K/'),
+ commonpool_s_text_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S.text-s13M-b4K/'),
+ commonpool_s_basic_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S.basic-s13M-b4K/'),
+ commonpool_s_s13m_b4k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-CommonPool.S-s13M-b4K/'),
+ # MetaClip models (NOTE quick-gelu activation used)
+ metaclip_400m=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/b32_400m.pt",
+ hf_hub="timm/vit_base_patch32_clip_224.metaclip_400m/",
+ quick_gelu=True,
+ ),
+ metaclip_fullcc=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/b32_fullcc2.5b.pt",
+ hf_hub="timm/vit_base_patch32_clip_224.metaclip_2pt5b/",
+ quick_gelu=True,
+ ),
+)
+
+_VITB32_256 = dict(
+ datacomp_s34b_b86k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-256x256-DataComp-s34B-b86K/'),
+)
+
+_VITB16 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
+ hf_hub="timm/vit_base_patch16_clip_224.openai/",
+ quick_gelu=True,
+ ),
+ # LAION-400M
+ laion400m_e31=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_16-laion400m_e31-00efa78f.pt",
+ hf_hub="timm/vit_base_patch16_clip_224.laion400m_e31/",
+ ),
+ laion400m_e32=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_16-laion400m_e32-55e67d44.pt",
+ hf_hub="timm/vit_base_patch16_clip_224.laion400m_e32/",
+ ),
+ # LAION-2B
+ laion2b_s34b_b88k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-laion2B-s34B-b88K/'),
+ # DataComp-XL models
+ datacomp_xl_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-DataComp.XL-s13B-b90K/'),
+ # DataComp-L models
+ datacomp_l_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-DataComp.L-s1B-b8K/'),
+ commonpool_l_clip_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L.clip-s1B-b8K/'),
+ commonpool_l_laion_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L.laion-s1B-b8K/'),
+ commonpool_l_image_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L.image-s1B-b8K/'),
+ commonpool_l_text_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L.text-s1B-b8K/'),
+ commonpool_l_basic_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L.basic-s1B-b8K/'),
+ commonpool_l_s1b_b8k=_pcfg(hf_hub='laion/CLIP-ViT-B-16-CommonPool.L-s1B-b8K/'),
+ # DFN
+ dfn2b=_pcfg(
+ hf_hub='apple/DFN2B-CLIP-ViT-B-16/',
+ quick_gelu=True,
+ ),
+ # MetaCLIP (these are quick-gelu)
+ metaclip_400m=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/b16_400m.pt",
+ hf_hub="timm/vit_base_patch16_clip_224.metaclip_400m/",
+ quick_gelu=True,
+ ),
+ metaclip_fullcc=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/b16_fullcc2.5b.pt",
+ hf_hub="timm/vit_base_patch16_clip_224.metaclip_2pt5b/",
+ quick_gelu=True,
+ ),
+)
+
+_VITB16_PLUS_240 = dict(
+ laion400m_e31=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_16_plus_240-laion400m_e31-8fb26589.pt",
+ hf_hub="timm/vit_base_patch16_plus_clip_240.laion400m_e31/",
+ ),
+ laion400m_e32=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_b_16_plus_240-laion400m_e32-699c4b84.pt",
+ hf_hub="timm/vit_base_patch16_plus_clip_240.laion400m_e31/",
+ ),
+)
+
+_VITL14 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
+ hf_hub="timm/vit_large_patch14_clip_224.openai/",
+ quick_gelu=True,
+ ),
+ # LAION-400M
+ laion400m_e31=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_l_14-laion400m_e31-69988bb6.pt",
+ hf_hub="timm/vit_large_patch14_clip_224.laion400m_e31/",
+ ),
+ laion400m_e32=_pcfg(
+ url="https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/vit_l_14-laion400m_e32-3d133497.pt",
+ hf_hub="timm/vit_large_patch14_clip_224.laion400m_e32/",
+ ),
+ # LAION-2B-en
+ laion2b_s32b_b82k=_pcfg(
+ hf_hub='laion/CLIP-ViT-L-14-laion2B-s32B-b82K/',
+ mean=INCEPTION_MEAN, std=INCEPTION_STD),
+ # DataComp-XL models
+ datacomp_xl_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K/'),
+ commonpool_xl_clip_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K/'),
+ commonpool_xl_laion_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K/'),
+ commonpool_xl_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K/'),
+ # MetaCLIP
+ metaclip_400m=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/l14_400m.pt",
+ hf_hub="timm/vit_large_patch14_clip_224.metaclip_400m/",
+ quick_gelu=True,
+ ),
+ metaclip_fullcc=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/l14_fullcc2.5b.pt",
+ hf_hub="timm/vit_large_patch14_clip_224.metaclip_2pt5b/",
+ quick_gelu=True,
+ ),
+ # DFN-2B (quick-gelu)
+ dfn2b=_pcfg(
+ hf_hub='apple/DFN2B-CLIP-ViT-L-14/',
+ quick_gelu=True,
+ ),
+ # DFN-2B 39B SS
+ dfn2b_s39b=_pcfg(
+ hf_hub='apple/DFN2B-CLIP-ViT-L-14-39B/',
+ ),
+)
+
+_VITL14_336 = dict(
+ openai=_pcfg(
+ url="https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
+ hf_hub="timm/vit_large_patch14_clip_336.openai/",
+ quick_gelu=True,
+ ),
+)
+
+_VITH14 = dict(
+ # LAION-2B-en
+ laion2b_s32b_b79k=_pcfg(hf_hub='laion/CLIP-ViT-H-14-laion2B-s32B-b79K/'),
+ # MetaCLIP (quick-gelu)
+ metaclip_fullcc=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/h14_fullcc2.5b.pt",
+ hf_hub="timm/vit_huge_patch14_clip_224.metaclip_2pt5b/",
+ quick_gelu=True,
+ ),
+ metaclip_altogether=_pcfg(
+ url="https://dl.fbaipublicfiles.com/MMPT/metaclip/h14_v1.2_altogether.pt",
+ hf_hub="timm/vit_huge_patch14_clip_224.metaclip_altogether/",
+ # NOTE unlike other MetaCLIP models, this is not using QuickGELU, yay!
+ ),
+ # DFN-5B (quick-gelu)
+ dfn5b=_pcfg(
+ hf_hub='apple/DFN5B-CLIP-ViT-H-14/',
+ quick_gelu=True,
+ interpolation="bicubic",
+ resize_mode="squash"
+ ),
+)
+
+_VITH14_378 = dict(
+ # DFN-5B (quick-gelu)
+ dfn5b=_pcfg(
+ hf_hub='apple/DFN5B-CLIP-ViT-H-14-378/',
+ quick_gelu=True,
+ interpolation="bicubic",
+ resize_mode="squash"
+ ),
+)
+
+_VITg14 = dict(
+ laion2b_s12b_b42k=_pcfg(hf_hub='laion/CLIP-ViT-g-14-laion2B-s12B-b42K/'),
+ laion2b_s34b_b88k=_pcfg(hf_hub='laion/CLIP-ViT-g-14-laion2B-s34B-b88K/'),
+)
+
+_VITbigG14 = dict(
+ # LAION-2B-en
+ laion2b_s39b_b160k=_pcfg(hf_hub='laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/'),
+ # MetaCLIP (quick-gelu)
+ metaclip_fullcc=_pcfg(
+ url='https://dl.fbaipublicfiles.com/MMPT/metaclip/G14_fullcc2.5b.pt',
+ hf_hub="timm/vit_gigantic_patch14_clip_224.metaclip_2pt5b/",
+ quick_gelu=True,
+ ),
+)
+
+_robertaViTB32 = dict(
+ laion2b_s12b_b32k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k/'),
+)
+
+_xlmRobertaBaseViTB32 = dict(
+ laion5b_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90k/'),
+)
+
+_xlmRobertaLargeFrozenViTH14 = dict(
+ frozen_laion5b_s13b_b90k=_pcfg(hf_hub='laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k/'),
+)
+
+_convnext_base = dict(
+ laion400m_s13b_b51k=_pcfg(hf_hub='laion/CLIP-convnext_base-laion400M-s13B-b51K/'),
+)
+
+_convnext_base_w = dict(
+ laion2b_s13b_b82k=_pcfg(hf_hub='laion/CLIP-convnext_base_w-laion2B-s13B-b82K/'),
+ laion2b_s13b_b82k_augreg=_pcfg(hf_hub='laion/CLIP-convnext_base_w-laion2B-s13B-b82K-augreg/'),
+ laion_aesthetic_s13b_b82k=_pcfg(hf_hub='laion/CLIP-convnext_base_w-laion_aesthetic-s13B-b82K/'),
+)
+
+_convnext_base_w_320 = dict(
+ laion_aesthetic_s13b_b82k=_pcfg(hf_hub='laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K/'),
+ laion_aesthetic_s13b_b82k_augreg=_pcfg(hf_hub='laion/CLIP-convnext_base_w_320-laion_aesthetic-s13B-b82K-augreg/'),
+)
+
+_convnext_large_d = dict(
+ laion2b_s26b_b102k_augreg=_pcfg(hf_hub='laion/CLIP-convnext_large_d.laion2B-s26B-b102K-augreg/'),
+)
+
+_convnext_large_d_320 = dict(
+ laion2b_s29b_b131k_ft=_pcfg(hf_hub='laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft/'),
+ laion2b_s29b_b131k_ft_soup=_pcfg(hf_hub='laion/CLIP-convnext_large_d_320.laion2B-s29B-b131K-ft-soup/'),
+)
+
+_convnext_xxlarge = dict(
+ laion2b_s34b_b82k_augreg=_pcfg(hf_hub='laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg/'),
+ laion2b_s34b_b82k_augreg_rewind=_pcfg(hf_hub='laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-rewind/'),
+ laion2b_s34b_b82k_augreg_soup=_pcfg(hf_hub='laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-soup/'),
+)
+
+_coca_VITB32 = dict(
+ laion2b_s13b_b90k=_pcfg(hf_hub='laion/CoCa-ViT-B-32-laion2B-s13B-b90k/'),
+ mscoco_finetuned_laion2b_s13b_b90k=_pcfg(hf_hub='laion/mscoco_finetuned_CoCa-ViT-B-32-laion2B-s13B-b90k/')
+)
+
+_coca_VITL14 = dict(
+ laion2b_s13b_b90k=_pcfg(hf_hub='laion/CoCa-ViT-L-14-laion2B-s13B-b90k/'),
+ mscoco_finetuned_laion2b_s13b_b90k=_pcfg(hf_hub='laion/mscoco_finetuned_CoCa-ViT-L-14-laion2B-s13B-b90k/')
+)
+
+
+_PRETRAINED = {
+ "RN50": _RN50,
+ "RN101": _RN101,
+ "RN50x4": _RN50x4,
+ "RN50x16": _RN50x16,
+ "RN50x64": _RN50x64,
+
+ "ViT-B-32": _VITB32,
+ "ViT-B-32-256": _VITB32_256,
+ "ViT-B-16": _VITB16,
+ "ViT-B-16-plus-240": _VITB16_PLUS_240,
+ "ViT-L-14": _VITL14,
+ "ViT-L-14-336": _VITL14_336,
+ "ViT-H-14": _VITH14,
+ "ViT-H-14-378": _VITH14_378,
+ "ViT-g-14": _VITg14,
+ "ViT-bigG-14": _VITbigG14,
+
+ "roberta-ViT-B-32": _robertaViTB32,
+ "xlm-roberta-base-ViT-B-32": _xlmRobertaBaseViTB32,
+ "xlm-roberta-large-ViT-H-14": _xlmRobertaLargeFrozenViTH14,
+
+ "convnext_base": _convnext_base,
+ "convnext_base_w": _convnext_base_w,
+ "convnext_base_w_320": _convnext_base_w_320,
+ "convnext_large_d": _convnext_large_d,
+ "convnext_large_d_320": _convnext_large_d_320,
+ "convnext_xxlarge": _convnext_xxlarge,
+
+ "coca_ViT-B-32": _coca_VITB32,
+ "coca_ViT-L-14": _coca_VITL14,
+
+ "EVA01-g-14": dict(
+ # from QuanSun/EVA-CLIP/EVA01_CLIP_g_14_psz14_s11B.pt
+ laion400m_s11b_b41k=_pcfg(hf_hub='timm/eva_giant_patch14_clip_224.laion400m_s11b_b41k/'),
+ ),
+ "EVA01-g-14-plus": dict(
+ # from QuanSun/EVA-CLIP/EVA01_CLIP_g_14_plus_psz14_s11B.pt
+ merged2b_s11b_b114k=_pcfg(hf_hub='timm/eva_giant_patch14_plus_clip_224.merged2b_s11b_b114k/'),
+ ),
+ "EVA02-B-16": dict(
+ # from QuanSun/EVA-CLIP/EVA02_CLIP_B_psz16_s8B.pt
+ merged2b_s8b_b131k=_pcfg(hf_hub='timm/eva02_base_patch16_clip_224.merged2b_s8b_b131k/'),
+ ),
+ "EVA02-L-14": dict(
+ # from QuanSun/EVA-CLIP/EVA02_CLIP_L_psz14_s4B.pt
+ merged2b_s4b_b131k=_pcfg(hf_hub='timm/eva02_large_patch14_clip_224.merged2b_s4b_b131k/'),
+ ),
+ "EVA02-L-14-336": dict(
+ # from QuanSun/EVA-CLIP/EVA02_CLIP_L_336_psz14_s6B.pt
+ merged2b_s6b_b61k=_pcfg(hf_hub='timm/eva02_large_patch14_clip_336.merged2b_s6b_b61k/'),
+ ),
+ "EVA02-E-14": dict(
+ # from QuanSun/EVA-CLIP/EVA02_CLIP_E_psz14_s4B.pt
+ laion2b_s4b_b115k=_pcfg(hf_hub='timm/eva02_enormous_patch14_clip_224.laion2b_s4b_b115k/'),
+ ),
+ "EVA02-E-14-plus": dict(
+ # from QuanSun/EVA-CLIP/EVA02_CLIP_E_psz14_plus_s9B.pt
+ laion2b_s9b_b144k=_pcfg(hf_hub='timm/eva02_enormous_patch14_plus_clip_224.laion2b_s9b_b144k/'),
+ ),
+
+ "ViT-B-16-SigLIP": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP/'),
+ ),
+ "ViT-B-16-SigLIP-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP-256/'),
+ ),
+ "ViT-B-16-SigLIP-i18n-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP-i18n-256/'),
+ ),
+ "ViT-B-16-SigLIP-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP-384/'),
+ ),
+ "ViT-B-16-SigLIP-512": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP-512/'),
+ ),
+ "ViT-L-16-SigLIP-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-L-16-SigLIP-256/'),
+ ),
+ "ViT-L-16-SigLIP-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-L-16-SigLIP-384/'),
+ ),
+ "ViT-SO400M-14-SigLIP": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-14-SigLIP/'),
+ ),
+ "ViT-SO400M-16-SigLIP-i18n-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-16-SigLIP-i18n-256/'),
+ ),
+ "ViT-SO400M-14-SigLIP-378": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-14-SigLIP-384/'), # NOTE using 384 weights, but diff img_size used
+ ),
+ "ViT-SO400M-14-SigLIP-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-14-SigLIP-384/'),
+ ),
+
+ "ViT-B-32-SigLIP2-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-32-SigLIP2-256/'),
+ ),
+ "ViT-B-16-SigLIP2": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP2/'),
+ ),
+ "ViT-B-16-SigLIP2-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP2-256/'),
+ ),
+ "ViT-B-16-SigLIP2-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP2-384/'),
+ ),
+ "ViT-B-16-SigLIP2-512": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-B-16-SigLIP2-512/'),
+ ),
+ "ViT-L-16-SigLIP2-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-L-16-SigLIP2-256/'),
+ ),
+ "ViT-L-16-SigLIP2-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-L-16-SigLIP2-384/'),
+ ),
+ "ViT-L-16-SigLIP2-512": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-L-16-SigLIP2-512/'),
+ ),
+ "ViT-SO400M-14-SigLIP2": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-14-SigLIP2/'),
+ ),
+ "ViT-SO400M-14-SigLIP2-378": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-14-SigLIP2-378/'),
+ ),
+ "ViT-SO400M-16-SigLIP2-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-16-SigLIP2-256/'),
+ ),
+ "ViT-SO400M-16-SigLIP2-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-16-SigLIP2-384/'),
+ ),
+ "ViT-SO400M-16-SigLIP2-512": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-SO400M-16-SigLIP2-512/'),
+ ),
+ "ViT-gopt-16-SigLIP2-256": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-gopt-16-SigLIP2-256/'),
+ ),
+ "ViT-gopt-16-SigLIP2-384": dict(
+ webli=_slpcfg(hf_hub='timm/ViT-gopt-16-SigLIP2-384/'),
+ ),
+
+ "ViT-L-14-CLIPA": dict(
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-L-14-CLIPA-datacomp1B/'),
+ ),
+ "ViT-L-14-CLIPA-336": dict(
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-L-14-CLIPA-336-datacomp1B/'),
+ ),
+ "ViT-H-14-CLIPA": dict(
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-H-14-CLIPA-datacomp1B/'),
+ ),
+ "ViT-H-14-CLIPA-336": dict(
+ laion2b=_apcfg(hf_hub='UCSC-VLAA/ViT-H-14-CLIPA-336-laion2B/'),
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-H-14-CLIPA-336-datacomp1B/'),
+ ),
+ "ViT-bigG-14-CLIPA": dict(
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-bigG-14-CLIPA-datacomp1B/'),
+ ),
+ "ViT-bigG-14-CLIPA-336": dict(
+ datacomp1b=_apcfg(hf_hub='UCSC-VLAA/ViT-bigG-14-CLIPA-336-datacomp1B/'),
+ ),
+
+ "nllb-clip-base": dict(
+ v1=_pcfg(hf_hub='visheratin/nllb-clip-base-oc/'),
+ ),
+ "nllb-clip-large": dict(
+ v1=_pcfg(hf_hub='visheratin/nllb-clip-large-oc/'),
+ ),
+
+ "nllb-clip-base-siglip": dict(
+ v1=_slpcfg(hf_hub='visheratin/nllb-clip-base-siglip/'),
+ mrl=_slpcfg(hf_hub='visheratin/nllb-siglip-mrl-base/'),
+ ),
+ "nllb-clip-large-siglip": dict(
+ v1=_slpcfg(hf_hub='visheratin/nllb-clip-large-siglip/'),
+ mrl=_slpcfg(hf_hub='visheratin/nllb-siglip-mrl-large/'),
+ ),
+
+ "MobileCLIP-S1": dict(
+ datacompdr=_mccfg(hf_hub='apple/MobileCLIP-S1-OpenCLIP/')),
+ "MobileCLIP-S2": dict(
+ datacompdr=_mccfg(hf_hub='apple/MobileCLIP-S2-OpenCLIP/')),
+ "MobileCLIP-B": dict(
+ datacompdr=_mccfg(hf_hub='apple/MobileCLIP-B-OpenCLIP/'),
+ datacompdr_lt=_mccfg(hf_hub='apple/MobileCLIP-B-LT-OpenCLIP/'),
+ ),
+
+ "ViTamin-S": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-S/pytorch_model.bin'),
+ ),
+ "ViTamin-S-LTT": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-S-LTT/pytorch_model.bin'),
+ ),
+ "ViTamin-B": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-B/pytorch_model.bin'),
+ ),
+ "ViTamin-B-LTT": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-B-LTT/pytorch_model.bin'),
+ ),
+ "ViTamin-L": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L-224px/pytorch_model.bin'),
+ ),
+ "ViTamin-L-256": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L-256px/pytorch_model.bin'),
+ ),
+ "ViTamin-L-336": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L-336px/pytorch_model.bin'),
+ ),
+ "ViTamin-L-384": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L-384px/pytorch_model.bin'),
+ ),
+ "ViTamin-L2": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L2-224px/pytorch_model.bin'),
+ ),
+ "ViTamin-L2-256": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L2-256px/pytorch_model.bin'),
+ ),
+ "ViTamin-L2-336": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L2-336px/pytorch_model.bin'),
+ ),
+ "ViTamin-L2-384": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-L2-384px/pytorch_model.bin'),
+ ),
+ "ViTamin-XL-256": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-XL-256px/pytorch_model.bin'),
+ ),
+ "ViTamin-XL-336": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-XL-336px/pytorch_model.bin'),
+ ),
+ "ViTamin-XL-384": dict(
+ datacomp1b=_pcfg(hf_hub='jienengchen/ViTamin-XL-384px/pytorch_model.bin'),
+ ),
+}
+
+_PRETRAINED_quickgelu = {}
+for k, v in _PRETRAINED.items():
+ quick_gelu_tags = {}
+ for tk, tv in v.items():
+ if tv.get('quick_gelu', False):
+ quick_gelu_tags[tk] = copy.deepcopy(tv)
+ if quick_gelu_tags:
+ _PRETRAINED_quickgelu[k + '-quickgelu'] = quick_gelu_tags
+_PRETRAINED.update(_PRETRAINED_quickgelu)
+
+def _clean_tag(tag: str):
+ # normalize pretrained tags
+ return tag.lower().replace('-', '_')
+
+
+def list_pretrained(as_str: bool = False):
+ """ returns list of pretrained models
+ Returns a tuple (model_name, pretrain_tag) by default or 'name:tag' if as_str == True
+ """
+ return [':'.join([k, t]) if as_str else (k, t) for k in _PRETRAINED.keys() for t in _PRETRAINED[k].keys()]
+
+
+def list_pretrained_models_by_tag(tag: str):
+ """ return all models having the specified pretrain tag """
+ models = []
+ tag = _clean_tag(tag)
+ for k in _PRETRAINED.keys():
+ if tag in _PRETRAINED[k]:
+ models.append(k)
+ return models
+
+
+def list_pretrained_tags_by_model(model: str):
+ """ return all pretrain tags for the specified model architecture """
+ tags = []
+ if model in _PRETRAINED:
+ tags.extend(_PRETRAINED[model].keys())
+ return tags
+
+
+def is_pretrained_cfg(model: str, tag: str):
+ if model not in _PRETRAINED:
+ return False
+ return _clean_tag(tag) in _PRETRAINED[model]
+
+
+def get_pretrained_cfg(model: str, tag: str):
+ if model not in _PRETRAINED:
+ return {}
+ model_pretrained = _PRETRAINED[model]
+ return model_pretrained.get(_clean_tag(tag), {})
+
+
+def get_pretrained_url(model: str, tag: str):
+ cfg = get_pretrained_cfg(model, _clean_tag(tag))
+ return cfg.get('url', '')
+
+
+def download_pretrained_from_url(
+ url: str,
+ cache_dir: Optional[str] = None,
+):
+ if not cache_dir:
+ cache_dir = os.path.expanduser("~/.cache/clip")
+ os.makedirs(cache_dir, exist_ok=True)
+ filename = os.path.basename(url)
+
+ if 'openaipublic' in url:
+ expected_sha256 = url.split("/")[-2]
+ elif 'mlfoundations' in url:
+ expected_sha256 = os.path.splitext(filename)[0].split("-")[-1]
+ else:
+ expected_sha256 = ''
+
+ download_target = os.path.join(cache_dir, filename)
+
+ if os.path.exists(download_target) and not os.path.isfile(download_target):
+ raise RuntimeError(f"{download_target} exists and is not a regular file")
+
+ if os.path.isfile(download_target):
+ if expected_sha256:
+ if hashlib.sha256(open(download_target, "rb").read()).hexdigest().startswith(expected_sha256):
+ return download_target
+ else:
+ warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
+ else:
+ return download_target
+
+ with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
+ with tqdm(total=int(source.headers.get("Content-Length")), ncols=80, unit='iB', unit_scale=True) as loop:
+ while True:
+ buffer = source.read(8192)
+ if not buffer:
+ break
+
+ output.write(buffer)
+ loop.update(len(buffer))
+
+ if expected_sha256 and not hashlib.sha256(open(download_target, "rb").read()).hexdigest().startswith(expected_sha256):
+ raise RuntimeError(f"Model has been downloaded but the SHA256 checksum does not not match")
+
+ return download_target
+
+
+def has_hf_hub(necessary=False):
+ if not _has_hf_hub and necessary:
+ # if no HF Hub module installed, and it is necessary to continue, raise error
+ raise RuntimeError(
+ 'Hugging Face hub model specified but package not installed. Run `pip install huggingface_hub`.')
+ return _has_hf_hub
+
+
+def _get_safe_alternatives(filename: str) -> Iterable[str]:
+ """Returns potential safetensors alternatives for a given filename.
+
+ Use case:
+ When downloading a model from the Huggingface Hub, we first look if a .safetensors file exists and if yes, we use it.
+ """
+ if filename == HF_WEIGHTS_NAME:
+ yield HF_SAFE_WEIGHTS_NAME
+
+ if filename not in (HF_WEIGHTS_NAME,) and (filename.endswith(".bin") or filename.endswith(".pth")):
+ yield filename[:-4] + ".safetensors"
+
+
+def download_pretrained_from_hf(
+ model_id: str,
+ filename: Optional[str] = None,
+ revision: Optional[str] = None,
+ cache_dir: Optional[str] = None,
+):
+ has_hf_hub(True)
+
+ filename = filename or HF_WEIGHTS_NAME
+
+ # Look for .safetensors alternatives and load from it if it exists
+ if _has_safetensors:
+ for safe_filename in _get_safe_alternatives(filename):
+ try:
+ cached_file = hf_hub_download(
+ repo_id=model_id,
+ filename=safe_filename,
+ revision=revision,
+ cache_dir=cache_dir,
+ )
+ return cached_file
+ except Exception:
+ pass
+
+ try:
+ # Attempt to download the file
+ cached_file = hf_hub_download(
+ repo_id=model_id,
+ filename=filename,
+ revision=revision,
+ cache_dir=cache_dir,
+ )
+ return cached_file # Return the path to the downloaded file if successful
+ except Exception as e:
+ raise FileNotFoundError(f"Failed to download file ({filename}) for {model_id}. Last error: {e}")
+
+
+def download_pretrained(
+ cfg: Dict,
+ prefer_hf_hub: bool = True,
+ cache_dir: Optional[str] = None,
+):
+ target = ''
+ if not cfg:
+ return target
+
+ if 'file' in cfg:
+ return cfg['file']
+
+ has_hub = has_hf_hub()
+ download_url = cfg.get('url', '')
+ download_hf_hub = cfg.get('hf_hub', '')
+ if has_hub and prefer_hf_hub and download_hf_hub:
+ # prefer to use HF hub, remove url info
+ download_url = ''
+
+ if download_url:
+ target = download_pretrained_from_url(download_url, cache_dir=cache_dir)
+ elif download_hf_hub:
+ has_hf_hub(True)
+ # we assume the hf_hub entries in pretrained config combine model_id + filename in
+ # 'org/model_name/filename.pt' form. To specify just the model id w/o filename and
+ # use 'open_clip_pytorch_model.bin' default, there must be a trailing slash 'org/model_name/'.
+ model_id, filename = os.path.split(download_hf_hub)
+ if filename:
+ target = download_pretrained_from_hf(model_id, filename=filename, cache_dir=cache_dir)
+ else:
+ target = download_pretrained_from_hf(model_id, cache_dir=cache_dir)
+
+ return target
diff --git a/src/open_clip/push_to_hf_hub.py b/src/open_clip/push_to_hf_hub.py
new file mode 100644
index 0000000000000000000000000000000000000000..f57244d15b3b1dbf81284454d0bb52ac041add6a
--- /dev/null
+++ b/src/open_clip/push_to_hf_hub.py
@@ -0,0 +1,318 @@
+import argparse
+import json
+from pathlib import Path
+from tempfile import TemporaryDirectory
+from typing import Optional, Tuple, Union
+
+import torch
+
+try:
+ from huggingface_hub import (
+ create_repo,
+ get_hf_file_metadata,
+ hf_hub_download,
+ hf_hub_url,
+ repo_type_and_id_from_hf_id,
+ upload_folder,
+ list_repo_files,
+ )
+ from huggingface_hub.utils import EntryNotFoundError
+ _has_hf_hub = True
+except ImportError:
+ _has_hf_hub = False
+
+try:
+ import safetensors.torch
+ _has_safetensors = True
+except ImportError:
+ _has_safetensors = False
+
+from .constants import HF_WEIGHTS_NAME, HF_SAFE_WEIGHTS_NAME, HF_CONFIG_NAME
+from .factory import create_model_from_pretrained, get_model_config, get_tokenizer
+from .tokenizer import HFTokenizer, SigLipTokenizer
+
+
+def save_config_for_hf(
+ model,
+ config_path: str,
+ model_config: Optional[dict]
+):
+ preprocess_cfg = {
+ 'mean': model.visual.image_mean,
+ 'std': model.visual.image_std,
+ }
+ other_pp = getattr(model.visual, 'preprocess_cfg', {})
+ if 'interpolation' in other_pp:
+ preprocess_cfg['interpolation'] = other_pp['interpolation']
+ if 'resize_mode' in other_pp:
+ preprocess_cfg['resize_mode'] = other_pp['resize_mode']
+ hf_config = {
+ 'model_cfg': model_config,
+ 'preprocess_cfg': preprocess_cfg,
+ }
+
+ with config_path.open('w') as f:
+ json.dump(hf_config, f, indent=2)
+
+
+def save_for_hf(
+ model,
+ tokenizer: HFTokenizer,
+ model_config: dict,
+ save_directory: str,
+ safe_serialization: Union[bool, str] = 'both',
+ skip_weights : bool = False,
+):
+ config_filename = HF_CONFIG_NAME
+
+ save_directory = Path(save_directory)
+ save_directory.mkdir(exist_ok=True, parents=True)
+
+ if not skip_weights:
+ tensors = model.state_dict()
+ if safe_serialization is True or safe_serialization == "both":
+ assert _has_safetensors, "`pip install safetensors` to use .safetensors"
+ safetensors.torch.save_file(tensors, save_directory / HF_SAFE_WEIGHTS_NAME)
+ if safe_serialization is False or safe_serialization == "both":
+ torch.save(tensors, save_directory / HF_WEIGHTS_NAME)
+
+ tokenizer.save_pretrained(save_directory)
+
+ config_path = save_directory / config_filename
+ save_config_for_hf(model, config_path, model_config=model_config)
+
+
+def push_to_hf_hub(
+ model,
+ tokenizer,
+ model_config: Optional[dict],
+ repo_id: str,
+ commit_message: str = 'Add model',
+ token: Optional[str] = None,
+ revision: Optional[str] = None,
+ private: bool = False,
+ create_pr: bool = False,
+ model_card: Optional[dict] = None,
+ safe_serialization: Union[bool, str] = 'both',
+):
+ if not isinstance(tokenizer, (HFTokenizer, SigLipTokenizer)):
+ # FIXME this makes it awkward to push models with new tokenizers, come up with better soln.
+ # default CLIP tokenizers use https://huggingface.co/openai/clip-vit-large-patch14
+ tokenizer = HFTokenizer('openai/clip-vit-large-patch14')
+
+ # Create repo if it doesn't exist yet
+ repo_url = create_repo(repo_id, token=token, private=private, exist_ok=True)
+
+ # Infer complete repo_id from repo_url
+ # Can be different from the input `repo_id` if repo_owner was implicit
+ _, repo_owner, repo_name = repo_type_and_id_from_hf_id(repo_url)
+ repo_id = f"{repo_owner}/{repo_name}"
+
+ # Check if repo already exists and determine what needs updating
+ repo_exists = False
+ repo_files = {}
+ try:
+ repo_files = set(list_repo_files(repo_id))
+ repo_exists = True
+ print('Repo exists', repo_files)
+ except Exception as e:
+ print('Repo does not exist', e)
+
+ try:
+ get_hf_file_metadata(hf_hub_url(repo_id=repo_id, filename="README.md", revision=revision))
+ has_readme = True
+ except EntryNotFoundError:
+ has_readme = False
+
+ # Dump model and push to Hub
+ with TemporaryDirectory() as tmpdir:
+ # Save model weights and config.
+ save_for_hf(
+ model,
+ tokenizer=tokenizer,
+ model_config=model_config,
+ save_directory=tmpdir,
+ safe_serialization=safe_serialization,
+ )
+
+ # Add readme if it does not exist
+ if not has_readme:
+ model_card = model_card or {}
+ model_name = repo_id.split('/')[-1]
+ readme_path = Path(tmpdir) / "README.md"
+ readme_text = generate_readme(model_card, model_name)
+ readme_path.write_text(readme_text)
+
+ # Upload model and return
+ return upload_folder(
+ repo_id=repo_id,
+ folder_path=tmpdir,
+ revision=revision,
+ create_pr=create_pr,
+ commit_message=commit_message,
+ )
+
+
+def push_pretrained_to_hf_hub(
+ model_name,
+ pretrained: str,
+ repo_id: str,
+ precision: str = 'fp32',
+ image_mean: Optional[Tuple[float, ...]] = None,
+ image_std: Optional[Tuple[float, ...]] = None,
+ image_interpolation: Optional[str] = None,
+ image_resize_mode: Optional[str] = None, # only effective for inference
+ commit_message: str = 'Add model',
+ token: Optional[str] = None,
+ revision: Optional[str] = None,
+ private: bool = False,
+ create_pr: bool = False,
+ model_card: Optional[dict] = None,
+ hf_tokenizer_self: bool = False,
+ **kwargs,
+):
+ model, preprocess_eval = create_model_from_pretrained(
+ model_name,
+ pretrained=pretrained,
+ precision=precision,
+ image_mean=image_mean,
+ image_std=image_std,
+ image_interpolation=image_interpolation,
+ image_resize_mode=image_resize_mode,
+ **kwargs,
+ )
+ model_config = get_model_config(model_name)
+ if pretrained == 'openai':
+ model_config['quick_gelu'] = True
+ assert model_config
+
+ tokenizer = get_tokenizer(model_name)
+ if hf_tokenizer_self:
+ # make hf tokenizer config in the uploaded model point to self instead of original location
+ model_config['text_cfg']['hf_tokenizer_name'] = repo_id
+
+ push_to_hf_hub(
+ model=model,
+ tokenizer=tokenizer,
+ model_config=model_config,
+ repo_id=repo_id,
+ commit_message=commit_message,
+ token=token,
+ revision=revision,
+ private=private,
+ create_pr=create_pr,
+ model_card=model_card,
+ safe_serialization='both',
+ )
+
+
+def generate_readme(model_card: dict, model_name: str):
+ tags = model_card.pop('tags', ('clip',))
+ pipeline_tag = model_card.pop('pipeline_tag', 'zero-shot-image-classification')
+ readme_text = "---\n"
+ if tags:
+ readme_text += "tags:\n"
+ for t in tags:
+ readme_text += f"- {t}\n"
+ readme_text += "library_name: open_clip\n"
+ readme_text += f"pipeline_tag: {pipeline_tag}\n"
+ readme_text += f"license: {model_card.get('license', 'mit')}\n"
+ if 'details' in model_card and 'Dataset' in model_card['details']:
+ readme_text += 'datasets:\n'
+ readme_text += f"- {model_card['details']['Dataset'].lower()}\n"
+ readme_text += "---\n"
+ readme_text += f"# Model card for {model_name}\n"
+ if 'description' in model_card:
+ readme_text += f"\n{model_card['description']}\n"
+ if 'details' in model_card:
+ readme_text += f"\n## Model Details\n"
+ for k, v in model_card['details'].items():
+ if isinstance(v, (list, tuple)):
+ readme_text += f"- **{k}:**\n"
+ for vi in v:
+ readme_text += f" - {vi}\n"
+ elif isinstance(v, dict):
+ readme_text += f"- **{k}:**\n"
+ for ki, vi in v.items():
+ readme_text += f" - {ki}: {vi}\n"
+ else:
+ readme_text += f"- **{k}:** {v}\n"
+ if 'usage' in model_card:
+ readme_text += f"\n## Model Usage\n"
+ readme_text += model_card['usage']
+ readme_text += '\n'
+
+ if 'comparison' in model_card:
+ readme_text += f"\n## Model Comparison\n"
+ readme_text += model_card['comparison']
+ readme_text += '\n'
+
+ if 'citation' in model_card:
+ readme_text += f"\n## Citation\n"
+ if not isinstance(model_card['citation'], (list, tuple)):
+ citations = [model_card['citation']]
+ else:
+ citations = model_card['citation']
+ for c in citations:
+ readme_text += f"```bibtex\n{c}\n```\n"
+
+ return readme_text
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="Push to Hugging Face Hub")
+ parser.add_argument(
+ "--model", type=str, help="Name of the model to use.",
+ )
+ parser.add_argument(
+ "--pretrained", type=str,
+ help="Use a pretrained CLIP model weights with the specified tag or file path.",
+ )
+ parser.add_argument(
+ "--repo-id", type=str,
+ help="Destination HF Hub repo-id ie 'organization/model_id'.",
+ )
+ parser.add_argument(
+ "--precision", type=str, default='fp32',
+ )
+ parser.add_argument(
+ '--image-mean', type=float, nargs='+', default=None, metavar='MEAN',
+ help='Override default image mean value of dataset')
+ parser.add_argument(
+ '--image-std', type=float, nargs='+', default=None, metavar='STD',
+ help='Override default image std deviation of of dataset')
+ parser.add_argument(
+ '--image-interpolation',
+ default=None, type=str, choices=['bicubic', 'bilinear', 'random'],
+ help="image resize interpolation"
+ )
+ parser.add_argument(
+ '--image-resize-mode',
+ default=None, type=str, choices=['shortest', 'longest', 'squash'],
+ help="image resize mode during inference"
+ )
+ parser.add_argument(
+ "--hf-tokenizer-self",
+ default=False,
+ action="store_true",
+ help="make hf_tokenizer_name point in uploaded config point to itself"
+ )
+ args = parser.parse_args()
+
+ print(f'Saving model {args.model} with pretrained weights {args.pretrained} to Hugging Face Hub at {args.repo_id}')
+
+ # FIXME add support to pass model_card json / template from file via cmd line
+
+ push_pretrained_to_hf_hub(
+ args.model,
+ args.pretrained,
+ args.repo_id,
+ precision=args.precision,
+ image_mean=args.image_mean, # override image mean/std if trained w/ non defaults
+ image_std=args.image_std,
+ image_interpolation=args.image_interpolation,
+ image_resize_mode=args.image_resize_mode,
+ hf_tokenizer_self=args.hf_tokenizer_self,
+ )
+
+ print(f'{args.model} saved.')
diff --git a/src/open_clip/timm_model.py b/src/open_clip/timm_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9ad57120b6cbc9fe1ec53067aab6bd4b1e26034
--- /dev/null
+++ b/src/open_clip/timm_model.py
@@ -0,0 +1,198 @@
+""" timm model adapter
+
+Wraps timm (https://github.com/rwightman/pytorch-image-models) models for use as a vision tower in CLIP model.
+"""
+import logging
+from collections import OrderedDict
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+try:
+ import timm
+ from timm.layers import RotAttentionPool2d
+ from timm.layers import AttentionPool2d as AbsAttentionPool2d
+ from timm.layers import Mlp, to_2tuple
+except ImportError:
+ timm = None
+
+from .utils import freeze_batch_norm_2d
+
+
+class TimmModel(nn.Module):
+ """ timm model adapter
+ """
+
+ def __init__(
+ self,
+ model_name: str,
+ embed_dim: int,
+ image_size: Union[int, Tuple[int, int]] = 224,
+ pool: str = 'avg',
+ proj: str = 'linear',
+ proj_bias: bool = False,
+ drop: float = 0.,
+ drop_path: Optional[float] = None,
+ patch_drop: Optional[float] = None,
+ pretrained: bool = False,
+ ):
+ super().__init__()
+ if timm is None:
+ raise RuntimeError("Please install the latest timm (`pip install timm`) to use timm based models.")
+ self.image_size = to_2tuple(image_size)
+
+ # setup kwargs that may not be common across all models
+ timm_kwargs = {}
+ if drop_path is not None:
+ timm_kwargs['drop_path_rate'] = drop_path
+ if patch_drop is not None:
+ timm_kwargs['patch_drop_rate'] = patch_drop
+
+ custom_pool = pool in ('abs_attn', 'rot_attn')
+ if proj:
+ assert proj in ("linear", "mlp", "none")
+ extra_proj = proj in ("linear", "mlp")
+ if not extra_proj and not custom_pool:
+ # use network classifier head as projection if no proj specified and no custom pooling used
+ # if projection is explicitly set to "none" will be pass through from network trunk
+ proj_dim = 0 if proj == 'none' else embed_dim
+ self.trunk = timm.create_model(
+ model_name,
+ num_classes=proj_dim,
+ global_pool=pool,
+ pretrained=pretrained,
+ **timm_kwargs,
+ )
+ prev_chs = embed_dim
+ else:
+ self.trunk = timm.create_model(
+ model_name,
+ pretrained=pretrained,
+ **timm_kwargs,
+ )
+ feat_size = self.trunk.default_cfg.get('pool_size', None)
+ feature_ndim = 1 if not feat_size else 2
+ if custom_pool:
+ assert feature_ndim == 2
+ # if attn pooling used, remove both classifier and default pool
+ self.trunk.reset_classifier(0, global_pool='')
+ else:
+ # reset global pool if pool config set, otherwise leave as network default
+ reset_kwargs = dict(global_pool=pool) if pool else {}
+ self.trunk.reset_classifier(0, **reset_kwargs)
+ prev_chs = self.trunk.num_features
+
+ head_layers = OrderedDict()
+
+ # Add custom pooling to head
+ if pool == 'abs_attn':
+ head_layers['pool'] = AbsAttentionPool2d(prev_chs, feat_size=feat_size, out_features=embed_dim)
+ prev_chs = embed_dim
+ elif pool == 'rot_attn':
+ head_layers['pool'] = RotAttentionPool2d(prev_chs, out_features=embed_dim)
+ prev_chs = embed_dim
+
+ # NOTE attention pool ends with a projection layer, so proj should usually be set to '' if such pooling is used
+ if proj == 'linear':
+ head_layers['drop'] = nn.Dropout(drop)
+ head_layers['proj'] = nn.Linear(prev_chs, embed_dim, bias=proj_bias)
+ elif proj == 'mlp':
+ head_layers['mlp'] = Mlp(prev_chs, 2 * embed_dim, embed_dim, drop=(drop, 0), bias=(True, proj_bias))
+
+ self.head = nn.Sequential(head_layers)
+
+ def lock(self, unlocked_groups: int = 0, freeze_bn_stats: bool = False):
+ """ lock modules
+ Args:
+ unlocked_groups (int): leave last n layer groups unlocked (default: 0)
+ """
+ if not unlocked_groups:
+ # lock full model
+ for param in self.trunk.parameters():
+ param.requires_grad = False
+ if freeze_bn_stats:
+ freeze_batch_norm_2d(self.trunk)
+ else:
+ # NOTE: partial freeze requires latest timm (master) branch and is subject to change
+ try:
+ # FIXME import here until API stable and in an official release
+ from timm.models.helpers import group_parameters, group_modules
+ except ImportError:
+ raise RuntimeError(
+ 'Please install latest timm `pip install git+https://github.com/rwightman/pytorch-image-models`')
+ matcher = self.trunk.group_matcher()
+ gparams = group_parameters(self.trunk, matcher)
+ max_layer_id = max(gparams.keys())
+ max_layer_id = max_layer_id - unlocked_groups
+ for group_idx in range(max_layer_id + 1):
+ group = gparams[group_idx]
+ for param in group:
+ self.trunk.get_parameter(param).requires_grad = False
+ if freeze_bn_stats:
+ gmodules = group_modules(self.trunk, matcher, reverse=True)
+ gmodules = {k for k, v in gmodules.items() if v <= max_layer_id}
+ freeze_batch_norm_2d(self.trunk, gmodules)
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable: bool = True):
+ try:
+ self.trunk.set_grad_checkpointing(enable)
+ except Exception as e:
+ logging.warning('grad checkpointing not supported for this timm image tower, continuing without...')
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ output_fmt: str = 'NCHW',
+ output_extra_tokens: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ x: Input image tensor
+ indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize_intermediates: Apply norm layer to all intermediates
+ intermediates_only: Only return intermediate features
+ output_fmt: Shape of intermediate feature outputs
+ output_extra_tokens: Return both prefix and spatial intermediate tokens
+ Returns:
+ """
+ extra_args = {}
+ if output_extra_tokens:
+ extra_args['return_prefix_tokens'] = True
+ trunk_output = self.trunk.forward_intermediates(
+ x,
+ indices=indices,
+ intermediates_only=intermediates_only,
+ norm=normalize_intermediates,
+ stop_early=stop_early,
+ output_fmt=output_fmt,
+ **extra_args,
+ )
+
+ return_dict = {}
+ intermediates = trunk_output if intermediates_only else trunk_output[1]
+ if output_extra_tokens and intermediates and isinstance(intermediates[0], tuple):
+ intermediates_prefix = [xi[1] for xi in intermediates]
+ intermediates = [xi[0] for xi in intermediates]
+ return_dict['image_intermediates_prefix'] = intermediates_prefix
+
+ return_dict['image_intermediates'] = intermediates
+ if intermediates_only:
+ return return_dict
+
+ image_features = self.trunk.forward_head(trunk_output[0]) # run through timm pooling / projection
+ image_features = self.head(image_features) # run through adapter pooling / projection
+ return_dict['image_features'] = image_features
+ return return_dict
+
+ def forward(self, x):
+ x = self.trunk(x)
+ x = self.head(x)
+ return x
diff --git a/src/open_clip/tokenizer.py b/src/open_clip/tokenizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fde57fc08fecf4d9f097c1e2580636fc8b84908d
--- /dev/null
+++ b/src/open_clip/tokenizer.py
@@ -0,0 +1,528 @@
+""" CLIP tokenizer
+
+Copied from https://github.com/openai/CLIP. Originally MIT License, Copyright (c) 2021 OpenAI.
+"""
+import gzip
+import html
+import os
+import random
+import string
+from functools import lru_cache, partial
+from typing import Callable, List, Optional, Union
+import warnings
+
+import ftfy
+import numpy as np
+import regex as re
+import torch
+
+# https://stackoverflow.com/q/62691279
+os.environ["TOKENIZERS_PARALLELISM"] = "false"
+_nltk_init = False
+
+DEFAULT_CONTEXT_LENGTH = 77 # default context length for OpenAI CLIP
+
+
+@lru_cache()
+def default_bpe():
+ return os.path.join(os.path.dirname(os.path.abspath(__file__)), "bpe_simple_vocab_16e6.txt.gz")
+
+
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a significant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8+n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = " ".join(text.split())
+ text = text.strip()
+ return text
+
+
+def _clean_canonicalize(x):
+ # basic, remove whitespace, remove punctuation, lower case
+ return canonicalize_text(basic_clean(x))
+
+
+def _clean_lower(x):
+ # basic, remove whitespace, lower case
+ return whitespace_clean(basic_clean(x)).lower()
+
+
+def _clean_whitespace(x):
+ # basic, remove whitespace
+ return whitespace_clean(basic_clean(x))
+
+
+def get_clean_fn(type: str):
+ if type == 'canonicalize':
+ return _clean_canonicalize
+ elif type == 'lower':
+ return _clean_lower
+ elif type == 'whitespace':
+ return _clean_whitespace
+ else:
+ assert False, f"Invalid clean function ({type})."
+
+
+def canonicalize_text(
+ text,
+ *,
+ keep_punctuation_exact_string=None,
+ trans_punctuation: dict = str.maketrans("", "", string.punctuation),
+):
+ """Returns canonicalized `text` (lowercase and punctuation removed).
+
+ From: https://github.com/google-research/big_vision/blob/53f18caf27a9419231bbf08d3388b07671616d3d/big_vision/evaluators/proj/image_text/prompt_engineering.py#L94
+
+ Args:
+ text: string to be canonicalized.
+ keep_punctuation_exact_string: If provided, then this exact string kept.
+ For example providing '{}' will keep any occurrences of '{}' (but will
+ still remove '{' and '}' that appear separately).
+ """
+ text = text.replace("_", " ")
+ if keep_punctuation_exact_string:
+ text = keep_punctuation_exact_string.join(
+ part.translate(trans_punctuation)
+ for part in text.split(keep_punctuation_exact_string)
+ )
+ else:
+ text = text.translate(trans_punctuation)
+ text = text.lower()
+ text = " ".join(text.split())
+ return text.strip()
+
+
+class SimpleTokenizer(object):
+ def __init__(
+ self,
+ bpe_path: str = default_bpe(),
+ additional_special_tokens: Optional[List[str]] = None,
+ context_length: Optional[int] = DEFAULT_CONTEXT_LENGTH,
+ clean: str = 'lower',
+ reduction_mask: str = ''
+ ):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+ merges = gzip.open(bpe_path).read().decode("utf-8").split('\n')
+ merges = merges[1:49152-256-2+1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v+'' for v in vocab]
+ for merge in merges:
+ vocab.append(''.join(merge))
+ special_tokens = ['', '']
+ if additional_special_tokens:
+ special_tokens += additional_special_tokens
+ vocab.extend(special_tokens)
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {t:t for t in special_tokens}
+ special = "|".join(special_tokens)
+ self.pat = re.compile(
+ special + r"""|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE,
+ )
+ self.vocab_size = len(self.encoder)
+ self.all_special_ids = [self.encoder[t] for t in special_tokens]
+ self.sot_token_id = self.all_special_ids[0]
+ self.eot_token_id = self.all_special_ids[1]
+ self.context_length = context_length
+ self.clean_fn = get_clean_fn(clean)
+ self.reduction_fn = get_reduction_mask_fn(reduction_mask) if reduction_mask else None
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + ( token[-1] + '',)
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token+''
+
+ while True:
+ bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except Exception:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word)-1 and word[i+1] == second:
+ new_word.append(first+second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = ' '.join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = self.clean_fn(text)
+ for token in re.findall(self.pat, text):
+ token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
+ bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = ''.join([self.decoder[token] for token in tokens])
+ text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors="replace").replace('', ' ')
+ return text
+
+ def __call__(self, texts: Union[str, List[str]], context_length: Optional[int] = None) -> torch.LongTensor:
+ """ Returns the tokenized representation of given input string(s)
+
+ Parameters
+ ----------
+ texts : Union[str, List[str]]
+ An input string or a list of input strings to tokenize
+ context_length : int
+ The context length to use; all CLIP models use 77 as the context length
+
+ Returns
+ -------
+ A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length]
+ """
+ if isinstance(texts, str):
+ texts = [texts]
+
+ context_length = context_length or self.context_length
+ assert context_length, 'Please set a valid context length'
+
+ if self.reduction_fn is not None:
+ # use reduction strategy for tokenize if set, otherwise default to truncation below
+ return self.reduction_fn(
+ texts,
+ context_length=context_length,
+ sot_token_id=self.sot_token_id,
+ eot_token_id=self.eot_token_id,
+ encode_fn=self.encode,
+ )
+
+ all_tokens = [[self.sot_token_id] + self.encode(text) + [self.eot_token_id] for text in texts]
+ result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
+
+ for i, tokens in enumerate(all_tokens):
+ if len(tokens) > context_length:
+ tokens = tokens[:context_length] # Truncate
+ tokens[-1] = self.eot_token_id
+ result[i, :len(tokens)] = torch.tensor(tokens)
+
+ return result
+
+
+_tokenizer = SimpleTokenizer()
+
+
+def decode(output_ids: torch.Tensor):
+ output_ids = output_ids.cpu().numpy()
+ return _tokenizer.decode(output_ids)
+
+
+def tokenize(texts: Union[str, List[str]], context_length: int = DEFAULT_CONTEXT_LENGTH) -> torch.LongTensor:
+ return _tokenizer(texts, context_length=context_length)
+
+
+def random_mask_tokenize(
+ texts: Union[str, List[str]],
+ context_length: int,
+ sot_token_id: int,
+ eot_token_id: int,
+ encode_fn: Callable,
+ shuffle: bool = False,
+):
+ all_tokens = [encode_fn(text) for text in texts]
+ result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
+
+ for i, tokens in enumerate(all_tokens):
+ tokens = torch.tensor(tokens)
+ num_tokens = len(tokens)
+ if num_tokens > context_length - 2: # 2 for sot and eot token
+ num_keep = context_length - 2
+ indices = torch.randperm(len(tokens))
+ indices = indices[:num_keep]
+ if not shuffle:
+ indices = indices.msort()
+ tokens = tokens[indices]
+ num_tokens = num_keep
+ result[i, 0] = sot_token_id
+ result[i, 1:num_tokens + 1] = tokens
+ result[i, num_tokens + 1] = eot_token_id
+
+ return result
+
+
+def simple_mask_tokenize(
+ texts: Union[str, List[str]],
+ context_length: int,
+ sot_token_id: int,
+ eot_token_id: int,
+ encode_fn: Callable,
+):
+ all_tokens = [encode_fn(text) for text in texts]
+ result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
+
+ for i, tokens in enumerate(all_tokens):
+ num_tokens = len(tokens)
+ if num_tokens > context_length - 2: # 2 for sot and eot token
+ num_keep = context_length - 2
+ start_index = random.randint(0, num_tokens - num_keep) # high is incl
+ tokens = tokens[start_index: start_index + num_keep]
+ tokens = [sot_token_id] + tokens + [eot_token_id]
+ result[i, :len(tokens)] = torch.tensor(tokens)
+
+ return result
+
+
+def syntax_mask_tokenize(
+ texts: Union[str, List[str]],
+ context_length: int,
+ sot_token_id: int,
+ eot_token_id: int,
+ encode_fn: Callable,
+) -> torch.LongTensor:
+ """ Returns the tokenized representation of given input string(s).
+ Apply syntax masking before tokenize.
+ """
+ import nltk
+ global _nltk_init
+ if not _nltk_init:
+ # run them for the first time
+ nltk.download('punkt')
+ nltk.download('averaged_perceptron_tagger')
+ _nltk_init = True
+
+ def get_order(x):
+ if x.startswith('NN'):
+ return 1
+ elif x.startswith('JJ'):
+ return 2
+ elif x.startswith('VB'):
+ return 3
+ else:
+ return 4
+
+ # syntax masking
+ new_texts = []
+ for text in texts:
+ list_tokens = nltk.tokenize.word_tokenize(text)
+ pos_tags = nltk.pos_tag(list_tokens)
+ # sample the words by get_order method
+ order_list = [get_order(tag) for _, tag in pos_tags]
+ sorted_ids = np.argsort(np.array(order_list))
+ sampled_ids = sorted(sorted_ids[:context_length - 2]) # need 2 slots for sot and eot tokens
+ sampled_tokens = np.take(np.array(list_tokens), sampled_ids, axis=0) # sample the tokens
+
+ new_text = ''
+ for token in sampled_tokens:
+ new_text = new_text + str(token) + ' '
+ new_text = new_text.strip()
+ new_texts.append(new_text)
+ texts = new_texts
+
+ all_tokens = [[sot_token_id] + encode_fn(text) + [eot_token_id] for text in texts]
+ result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
+
+ for i, tokens in enumerate(all_tokens):
+ # still need first truncate because some words produces two tokens
+ if len(tokens) > context_length:
+ tokens = tokens[:context_length] # Truncate
+ tokens[-1] = eot_token_id
+ result[i, :len(tokens)] = torch.tensor(tokens)
+
+ return result
+
+
+def get_reduction_mask_fn(type: str):
+ """ Choose strategy for dropping (masking) tokens to achieve target context length"""
+ assert type in ('simple', 'random', 'shuffle', 'syntax')
+ if type == 'simple':
+ return simple_mask_tokenize # randomly select block [start:end]
+ elif type == 'random':
+ return random_mask_tokenize # randomly drop tokens (keep order)
+ elif type == 'shuffle':
+ return partial(random_mask_tokenize, shuffle=True) # randomly drop tokens (shuffle order)
+ elif type == 'syntax':
+ return syntax_mask_tokenize # randomly drop prioritized by syntax
+
+
+class HFTokenizer:
+ """HuggingFace tokenizer wrapper"""
+
+ def __init__(
+ self,
+ tokenizer_name: str,
+ context_length: Optional[int] = DEFAULT_CONTEXT_LENGTH,
+ clean: str = 'whitespace',
+ strip_sep_token: bool = False,
+ language: Optional[str] = None,
+ cache_dir: Optional[str] = None,
+ **kwargs
+ ):
+ from transformers import AutoTokenizer
+ self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_name, cache_dir=cache_dir, **kwargs)
+ set_lang_fn = getattr(self.tokenizer, 'set_src_lang_special_tokens', None)
+ if callable(set_lang_fn):
+ self.set_lang_fn = set_lang_fn
+ if language is not None:
+ self.set_language(language)
+ self.context_length = context_length
+ self.clean_fn = get_clean_fn(clean)
+ self.strip_sep_token = strip_sep_token
+
+ def save_pretrained(self, dest):
+ self.tokenizer.save_pretrained(dest)
+
+ def __call__(self, texts: Union[str, List[str]], context_length: Optional[int] = None) -> torch.Tensor:
+ # same cleaning as for default tokenizer, except lowercasing
+ # adding lower (for case-sensitive tokenizers) will make it more robust but less sensitive to nuance
+ if isinstance(texts, str):
+ texts = [texts]
+
+ context_length = context_length or self.context_length
+ assert context_length, 'Please set a valid context length in class init or call.'
+
+ texts = [self.clean_fn(text) for text in texts]
+ input_ids = self.tokenizer.batch_encode_plus(
+ texts,
+ return_tensors='pt',
+ max_length=context_length,
+ padding='max_length',
+ truncation=True,
+ ).input_ids
+
+ if self.strip_sep_token:
+ input_ids = torch.where(
+ input_ids == self.tokenizer.sep_token_id,
+ torch.zeros_like(input_ids),
+ input_ids,
+ )
+
+ return input_ids
+
+ def set_language(self, src_lang):
+ if hasattr(self, 'set_lang_fn'):
+ self.set_lang_fn(src_lang)
+ else:
+ warnings.warn('Cannot set language for the tokenizer.')
+
+
+class SigLipTokenizer:
+ """HuggingFace tokenizer wrapper for SigLIP T5 compatible sentencepiece vocabs
+
+ NOTE: this is not needed in normal library use, but is used to import new sentencepiece tokenizers
+ into OpenCLIP. Leaving code here in case future models use new tokenizers.
+ """
+ VOCAB_FILES = {
+ # english, vocab_size=32_000
+ "c4-en": "http://storage.googleapis.com/t5-data/vocabs/cc_en.32000/sentencepiece.model",
+ # used in multilingual models (mT5, PaLI), vocab_size=250_000
+ "mc4": "http://storage.googleapis.com/t5-data/vocabs/mc4.250000.100extra/sentencepiece.model",
+ # used in SigLIP2 models, vocab_size=256000
+ "gemma": "http://storage.googleapis.com/big_vision/gemma_tokenizer.model",
+ }
+
+ def __init__(
+ self,
+ tokenizer_name: str,
+ context_length: Optional[int] = 64,
+ ):
+ if 'gemma' in tokenizer_name:
+ from transformers import GemmaTokenizerFast
+ tokenizer_cls = partial(
+ GemmaTokenizerFast, padding_side='right', add_bos_token=False, add_eos_token=True)
+ else:
+ from transformers import T5TokenizerFast
+ tokenizer_cls = partial(T5TokenizerFast, extra_ids=0)
+
+ if tokenizer_name in self.VOCAB_FILES:
+ # FIXME temporary hack?
+ import tempfile
+ import fsspec
+ vocab_file = self.VOCAB_FILES[tokenizer_name]
+ with tempfile.NamedTemporaryFile('wb') as dst:
+ with fsspec.open(vocab_file, 'rb') as src:
+ dst.write(src.read())
+ self.tokenizer = tokenizer_cls(dst.name, legacy=False)
+ else:
+ self.tokenizer = tokenizer_cls(tokenizer_name, legacy=False)
+
+ self.tokenizer.pad_token_id = 0 if 'gemma' in tokenizer_name else 1
+ self.tokenizer.eos_token_id = 1
+ self.context_length = context_length
+
+ def save_pretrained(self, dest):
+ self.tokenizer.save_pretrained(dest)
+
+ def __call__(self, texts: Union[str, List[str]], context_length: Optional[int] = None) -> torch.Tensor:
+ # same cleaning as for default tokenizer, except lowercasing
+ # adding lower (for case-sensitive tokenizers) will make it more robust but less sensitive to nuance
+ if isinstance(texts, str):
+ texts = [texts]
+
+ context_length = context_length or self.context_length
+ assert context_length, 'Please set a valid context length in class init or call.'
+
+ texts = [canonicalize_text(basic_clean(text)) for text in texts]
+ output = self.tokenizer(
+ texts,
+ return_tensors='pt',
+ max_length=context_length,
+ padding='max_length',
+ truncation=True,
+ )
+ return output.input_ids
diff --git a/src/open_clip/transform.py b/src/open_clip/transform.py
new file mode 100644
index 0000000000000000000000000000000000000000..521a203e3136587f7601325e09c244fc69238cfd
--- /dev/null
+++ b/src/open_clip/transform.py
@@ -0,0 +1,407 @@
+import numbers
+import random
+import warnings
+from dataclasses import dataclass, asdict
+from typing import Any, Dict, List, Optional, Sequence, Tuple, Union
+
+import torch
+import torchvision.transforms.functional as F
+from torchvision.transforms import Normalize, Compose, RandomResizedCrop, InterpolationMode, ToTensor, Resize, \
+ CenterCrop, ColorJitter, Grayscale
+
+from .constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
+from .utils import to_2tuple
+
+
+@dataclass
+class PreprocessCfg:
+ size: Union[int, Tuple[int, int]] = 224
+ mode: str = 'RGB'
+ mean: Tuple[float, ...] = OPENAI_DATASET_MEAN
+ std: Tuple[float, ...] = OPENAI_DATASET_STD
+ interpolation: str = 'bicubic'
+ resize_mode: str = 'shortest'
+ fill_color: int = 0
+
+ def __post_init__(self):
+ assert self.mode in ('RGB',)
+
+ @property
+ def num_channels(self):
+ return 3
+
+ @property
+ def input_size(self):
+ return (self.num_channels,) + to_2tuple(self.size)
+
+_PREPROCESS_KEYS = set(asdict(PreprocessCfg()).keys())
+
+
+def merge_preprocess_dict(
+ base: Union[PreprocessCfg, Dict],
+ overlay: Dict,
+):
+ """ Merge overlay key-value pairs on top of base preprocess cfg or dict.
+ Input dicts are filtered based on PreprocessCfg fields.
+ """
+ if isinstance(base, PreprocessCfg):
+ base_clean = asdict(base)
+ else:
+ base_clean = {k: v for k, v in base.items() if k in _PREPROCESS_KEYS}
+ if overlay:
+ overlay_clean = {k: v for k, v in overlay.items() if k in _PREPROCESS_KEYS and v is not None}
+ base_clean.update(overlay_clean)
+ return base_clean
+
+
+def merge_preprocess_kwargs(base: PreprocessCfg, **kwargs):
+ return merge_preprocess_dict(base, kwargs)
+
+
+@dataclass
+class AugmentationCfg:
+ scale: Tuple[float, float] = (0.9, 1.0)
+ ratio: Optional[Tuple[float, float]] = None
+ color_jitter: Optional[Union[float, Tuple[float, float, float], Tuple[float, float, float, float]]] = None
+ re_prob: Optional[float] = None
+ re_count: Optional[int] = None
+ use_timm: bool = False
+
+ # params for simclr_jitter_gray
+ color_jitter_prob: float = None
+ gray_scale_prob: float = None
+
+
+def _setup_size(size, error_msg):
+ if isinstance(size, numbers.Number):
+ return int(size), int(size)
+
+ if isinstance(size, Sequence) and len(size) == 1:
+ return size[0], size[0]
+
+ if len(size) != 2:
+ raise ValueError(error_msg)
+
+ return size
+
+
+class ResizeKeepRatio:
+ """ Resize and Keep Ratio
+
+ Copy & paste from `timm`
+ """
+
+ def __init__(
+ self,
+ size,
+ longest=0.,
+ interpolation=InterpolationMode.BICUBIC,
+ random_scale_prob=0.,
+ random_scale_range=(0.85, 1.05),
+ random_aspect_prob=0.,
+ random_aspect_range=(0.9, 1.11)
+ ):
+ if isinstance(size, (list, tuple)):
+ self.size = tuple(size)
+ else:
+ self.size = (size, size)
+ self.interpolation = interpolation
+ self.longest = float(longest) # [0, 1] where 0 == shortest edge, 1 == longest
+ self.random_scale_prob = random_scale_prob
+ self.random_scale_range = random_scale_range
+ self.random_aspect_prob = random_aspect_prob
+ self.random_aspect_range = random_aspect_range
+
+ @staticmethod
+ def get_params(
+ img,
+ target_size,
+ longest,
+ random_scale_prob=0.,
+ random_scale_range=(0.85, 1.05),
+ random_aspect_prob=0.,
+ random_aspect_range=(0.9, 1.11)
+ ):
+ """Get parameters
+ """
+ source_size = img.size[::-1] # h, w
+ h, w = source_size
+ target_h, target_w = target_size
+ ratio_h = h / target_h
+ ratio_w = w / target_w
+ ratio = max(ratio_h, ratio_w) * longest + min(ratio_h, ratio_w) * (1. - longest)
+ if random_scale_prob > 0 and random.random() < random_scale_prob:
+ ratio_factor = random.uniform(random_scale_range[0], random_scale_range[1])
+ ratio_factor = (ratio_factor, ratio_factor)
+ else:
+ ratio_factor = (1., 1.)
+ if random_aspect_prob > 0 and random.random() < random_aspect_prob:
+ aspect_factor = random.uniform(random_aspect_range[0], random_aspect_range[1])
+ ratio_factor = (ratio_factor[0] / aspect_factor, ratio_factor[1] * aspect_factor)
+ size = [round(x * f / ratio) for x, f in zip(source_size, ratio_factor)]
+ return size
+
+ def __call__(self, img):
+ """
+ Args:
+ img (PIL Image): Image to be cropped and resized.
+
+ Returns:
+ PIL Image: Resized, padded to at least target size, possibly cropped to exactly target size
+ """
+ size = self.get_params(
+ img, self.size, self.longest,
+ self.random_scale_prob, self.random_scale_range,
+ self.random_aspect_prob, self.random_aspect_range
+ )
+ img = F.resize(img, size, self.interpolation)
+ return img
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '(size={0}'.format(self.size)
+ format_string += f', interpolation={self.interpolation})'
+ format_string += f', longest={self.longest:.3f})'
+ return format_string
+
+
+def center_crop_or_pad(img: torch.Tensor, output_size: List[int], fill=0) -> torch.Tensor:
+ """Center crops and/or pads the given image.
+ If the image is torch Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+ If image size is smaller than output size along any edge, image is padded with 0 and then center cropped.
+
+ Args:
+ img (PIL Image or Tensor): Image to be cropped.
+ output_size (sequence or int): (height, width) of the crop box. If int or sequence with single int,
+ it is used for both directions.
+ fill (int, Tuple[int]): Padding color
+
+ Returns:
+ PIL Image or Tensor: Cropped image.
+ """
+ if isinstance(output_size, numbers.Number):
+ output_size = (int(output_size), int(output_size))
+ elif isinstance(output_size, (tuple, list)) and len(output_size) == 1:
+ output_size = (output_size[0], output_size[0])
+
+ _, image_height, image_width = F.get_dimensions(img)
+ crop_height, crop_width = output_size
+
+ if crop_width > image_width or crop_height > image_height:
+ padding_ltrb = [
+ (crop_width - image_width) // 2 if crop_width > image_width else 0,
+ (crop_height - image_height) // 2 if crop_height > image_height else 0,
+ (crop_width - image_width + 1) // 2 if crop_width > image_width else 0,
+ (crop_height - image_height + 1) // 2 if crop_height > image_height else 0,
+ ]
+ img = F.pad(img, padding_ltrb, fill=fill)
+ _, image_height, image_width = F.get_dimensions(img)
+ if crop_width == image_width and crop_height == image_height:
+ return img
+
+ crop_top = int(round((image_height - crop_height) / 2.0))
+ crop_left = int(round((image_width - crop_width) / 2.0))
+ return F.crop(img, crop_top, crop_left, crop_height, crop_width)
+
+
+class CenterCropOrPad(torch.nn.Module):
+ """Crops the given image at the center.
+ If the image is torch Tensor, it is expected
+ to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions.
+ If image size is smaller than output size along any edge, image is padded with 0 and then center cropped.
+
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
+ """
+
+ def __init__(self, size, fill=0):
+ super().__init__()
+ self.size = _setup_size(size, error_msg="Please provide only two dimensions (h, w) for size.")
+ self.fill = fill
+
+ def forward(self, img):
+ """
+ Args:
+ img (PIL Image or Tensor): Image to be cropped.
+
+ Returns:
+ PIL Image or Tensor: Cropped image.
+ """
+ return center_crop_or_pad(img, self.size, fill=self.fill)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}(size={self.size})"
+
+
+def _convert_to_rgb(image):
+ return image.convert('RGB')
+
+
+class color_jitter(object):
+ """
+ Apply Color Jitter to the PIL image with a specified probability.
+ """
+ def __init__(self, brightness=0., contrast=0., saturation=0., hue=0., p=0.8):
+ assert 0. <= p <= 1.
+ self.p = p
+ self.transf = ColorJitter(brightness=brightness, contrast=contrast, saturation=saturation, hue=hue)
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ return self.transf(img)
+ else:
+ return img
+
+
+class gray_scale(object):
+ """
+ Apply Gray Scale to the PIL image with a specified probability.
+ """
+ def __init__(self, p=0.2):
+ assert 0. <= p <= 1.
+ self.p = p
+ self.transf = Grayscale(num_output_channels=3)
+
+ def __call__(self, img):
+ if random.random() < self.p:
+ return self.transf(img)
+ else:
+ return img
+
+
+def image_transform(
+ image_size: Union[int, Tuple[int, int]],
+ is_train: bool,
+ mean: Optional[Tuple[float, ...]] = None,
+ std: Optional[Tuple[float, ...]] = None,
+ resize_mode: Optional[str] = None,
+ interpolation: Optional[str] = None,
+ fill_color: int = 0,
+ aug_cfg: Optional[Union[Dict[str, Any], AugmentationCfg]] = None,
+):
+ mean = mean or OPENAI_DATASET_MEAN
+ if not isinstance(mean, (list, tuple)):
+ mean = (mean,) * 3
+
+ std = std or OPENAI_DATASET_STD
+ if not isinstance(std, (list, tuple)):
+ std = (std,) * 3
+
+ interpolation = interpolation or 'bicubic'
+ assert interpolation in ['bicubic', 'bilinear', 'random']
+ # NOTE random is ignored for interpolation_mode, so defaults to BICUBIC for inference if set
+ interpolation_mode = InterpolationMode.BILINEAR if interpolation == 'bilinear' else InterpolationMode.BICUBIC
+
+ resize_mode = resize_mode or 'shortest'
+ assert resize_mode in ('shortest', 'longest', 'squash')
+
+ if isinstance(aug_cfg, dict):
+ aug_cfg = AugmentationCfg(**aug_cfg)
+ else:
+ aug_cfg = aug_cfg or AugmentationCfg()
+
+ normalize = Normalize(mean=mean, std=std)
+
+ if is_train:
+ aug_cfg_dict = {k: v for k, v in asdict(aug_cfg).items() if v is not None}
+ use_timm = aug_cfg_dict.pop('use_timm', False)
+ if use_timm:
+ from timm.data import create_transform # timm can still be optional
+ if isinstance(image_size, (tuple, list)):
+ assert len(image_size) >= 2
+ input_size = (3,) + image_size[-2:]
+ else:
+ input_size = (3, image_size, image_size)
+
+ aug_cfg_dict.setdefault('color_jitter', None) # disable by default
+ # drop extra non-timm items
+ aug_cfg_dict.pop('color_jitter_prob', None)
+ aug_cfg_dict.pop('gray_scale_prob', None)
+
+ train_transform = create_transform(
+ input_size=input_size,
+ is_training=True,
+ hflip=0.,
+ mean=mean,
+ std=std,
+ re_mode='pixel',
+ interpolation=interpolation,
+ **aug_cfg_dict,
+ )
+ else:
+ train_transform = [
+ RandomResizedCrop(
+ image_size,
+ scale=aug_cfg_dict.pop('scale'),
+ interpolation=InterpolationMode.BICUBIC,
+ ),
+ _convert_to_rgb,
+ ]
+ if aug_cfg.color_jitter_prob:
+ assert aug_cfg.color_jitter is not None and len(aug_cfg.color_jitter) == 4
+ train_transform.extend([
+ color_jitter(*aug_cfg.color_jitter, p=aug_cfg.color_jitter_prob)
+ ])
+ if aug_cfg.gray_scale_prob:
+ train_transform.extend([
+ gray_scale(aug_cfg.gray_scale_prob)
+ ])
+ train_transform.extend([
+ ToTensor(),
+ normalize,
+ ])
+ train_transform = Compose(train_transform)
+ if aug_cfg_dict:
+ warnings.warn(f'Unused augmentation cfg items, specify `use_timm` to use ({list(aug_cfg_dict.keys())}).')
+ return train_transform
+ else:
+ if resize_mode == 'longest':
+ transforms = [
+ ResizeKeepRatio(image_size, interpolation=interpolation_mode, longest=1),
+ CenterCropOrPad(image_size, fill=fill_color)
+ ]
+ elif resize_mode == 'squash':
+ if isinstance(image_size, int):
+ image_size = (image_size, image_size)
+ transforms = [
+ Resize(image_size, interpolation=interpolation_mode),
+ ]
+ else:
+ assert resize_mode == 'shortest'
+ if not isinstance(image_size, (tuple, list)):
+ image_size = (image_size, image_size)
+ if image_size[0] == image_size[1]:
+ # simple case, use torchvision built-in Resize w/ shortest edge mode (scalar size arg)
+ transforms = [
+ Resize(image_size[0], interpolation=interpolation_mode)
+ ]
+ else:
+ # resize shortest edge to matching target dim for non-square target
+ transforms = [ResizeKeepRatio(image_size)]
+ transforms += [CenterCrop(image_size)]
+
+ transforms.extend([
+ _convert_to_rgb,
+ ToTensor(),
+ normalize,
+ ])
+ return Compose(transforms)
+
+
+def image_transform_v2(
+ cfg: PreprocessCfg,
+ is_train: bool,
+ aug_cfg: Optional[Union[Dict[str, Any], AugmentationCfg]] = None,
+):
+ return image_transform(
+ image_size=cfg.size,
+ is_train=is_train,
+ mean=cfg.mean,
+ std=cfg.std,
+ interpolation=cfg.interpolation,
+ resize_mode=cfg.resize_mode,
+ fill_color=cfg.fill_color,
+ aug_cfg=aug_cfg,
+ )
diff --git a/src/open_clip/transformer.py b/src/open_clip/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..37006b08290962ae3df982ec38c661b7b56a3b0a
--- /dev/null
+++ b/src/open_clip/transformer.py
@@ -0,0 +1,1212 @@
+from collections import OrderedDict
+import math
+from typing import Callable, Dict, List, Optional, Sequence, Tuple, Union
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+from torch.utils.checkpoint import checkpoint
+
+from .utils import to_2tuple, feature_take_indices
+from .pos_embed import get_2d_sincos_pos_embed
+
+
+class LayerNormFp32(nn.LayerNorm):
+ """Subclass torch's LayerNorm to handle fp16 (by casting to float32 and back)."""
+
+ def forward(self, x: torch.Tensor):
+ orig_type = x.dtype
+ x = F.layer_norm(x.to(torch.float32), self.normalized_shape, self.weight, self.bias, self.eps)
+ return x.to(orig_type)
+
+
+class LayerNorm(nn.LayerNorm):
+ """Subclass torch's LayerNorm (with cast back to input dtype)."""
+
+ def forward(self, x: torch.Tensor):
+ orig_type = x.dtype
+ x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
+ return x.to(orig_type)
+
+
+class QuickGELU(nn.Module):
+ # NOTE This is slower than nn.GELU or nn.SiLU and uses more GPU memory
+ def forward(self, x: torch.Tensor):
+ return x * torch.sigmoid(1.702 * x)
+
+
+class LayerScale(nn.Module):
+ def __init__(self, dim, init_values=1e-5, inplace=False):
+ super().__init__()
+ self.inplace = inplace
+ self.gamma = nn.Parameter(init_values * torch.ones(dim))
+
+ def forward(self, x):
+ return x.mul_(self.gamma) if self.inplace else x * self.gamma
+
+
+class PatchDropout(nn.Module):
+ """
+ https://arxiv.org/abs/2212.00794
+ """
+
+ def __init__(
+ self,
+ prob: float = 0.5,
+ exclude_first_token: bool = True
+ ):
+ super().__init__()
+ assert 0 <= prob < 1.
+ self.prob = prob
+ self.exclude_first_token = exclude_first_token # exclude CLS token
+
+ def forward(self, x):
+ if not self.training or self.prob == 0.:
+ return x
+
+ if self.exclude_first_token:
+ cls_tokens, x = x[:, :1], x[:, 1:]
+ else:
+ cls_tokens = torch.jit.annotate(torch.Tensor, x[:, :1])
+
+ batch = x.size()[0]
+ num_tokens = x.size()[1]
+
+ batch_indices = torch.arange(batch)
+ batch_indices = batch_indices[..., None]
+
+ keep_prob = 1 - self.prob
+ num_patches_keep = max(1, int(num_tokens * keep_prob))
+
+ rand = torch.randn(batch, num_tokens)
+ patch_indices_keep = rand.topk(num_patches_keep, dim=-1).indices
+
+ x = x[batch_indices, patch_indices_keep]
+
+ if self.exclude_first_token:
+ x = torch.cat((cls_tokens, x), dim=1)
+
+ return x
+
+
+class Attention(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ num_heads: int = 8,
+ qkv_bias: bool = True,
+ scaled_cosine: bool = False,
+ scale_heads: bool = False,
+ logit_scale_max: float = math.log(1. / 0.01),
+ batch_first: bool = True,
+ attn_drop: float = 0.,
+ proj_drop: float = 0.
+ ):
+ super().__init__()
+ self.scaled_cosine = scaled_cosine
+ self.scale_heads = scale_heads
+ assert dim % num_heads == 0, 'dim should be divisible by num_heads'
+ self.num_heads = num_heads
+ self.head_dim = dim // num_heads
+ self.scale = self.head_dim ** -0.5
+ self.logit_scale_max = logit_scale_max
+ self.batch_first = batch_first
+ self.use_fsdpa = hasattr(nn.functional, 'scaled_dot_product_attention')
+
+ # keeping in_proj in this form (instead of nn.Linear) to match weight scheme of original
+ self.in_proj_weight = nn.Parameter(torch.randn((dim * 3, dim)) * self.scale)
+ if qkv_bias:
+ self.in_proj_bias = nn.Parameter(torch.zeros(dim * 3))
+ else:
+ self.in_proj_bias = None
+
+ if self.scaled_cosine:
+ self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
+ else:
+ self.logit_scale = None
+ self.attn_drop = nn.Dropout(attn_drop)
+ if self.scale_heads:
+ self.head_scale = nn.Parameter(torch.ones((num_heads, 1, 1)))
+ else:
+ self.head_scale = None
+ self.out_proj = nn.Linear(dim, dim)
+ self.out_drop = nn.Dropout(proj_drop)
+
+ def forward(self, x, attn_mask: Optional[torch.Tensor] = None):
+ if self.batch_first:
+ x = x.transpose(0, 1)
+
+ L, N, C = x.shape
+ q, k, v = F.linear(x, self.in_proj_weight, self.in_proj_bias).chunk(3, dim=-1)
+ q = q.reshape(L, N * self.num_heads, -1).transpose(0, 1)
+ k = k.reshape(L, N * self.num_heads, -1).transpose(0, 1)
+ v = v.reshape(L, N * self.num_heads, -1).transpose(0, 1)
+
+ if attn_mask is not None and attn_mask.dtype == torch.bool:
+ new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)
+ new_attn_mask.masked_fill_(attn_mask, float("-inf"))
+ attn_mask = new_attn_mask
+
+ if self.logit_scale is not None:
+ attn = torch.bmm(F.normalize(q, dim=-1), F.normalize(k, dim=-1).transpose(-1, -2))
+ logit_scale = torch.clamp(self.logit_scale, max=self.logit_scale_max).exp()
+ attn = attn.view(N, self.num_heads, L, L) * logit_scale
+ attn = attn.view(-1, L, L)
+ if attn_mask is not None:
+ attn = attn + attn_mask
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ x = torch.bmm(attn, v)
+ else:
+ if self.use_fsdpa:
+ x = F.scaled_dot_product_attention(
+ q, k, v,
+ attn_mask=attn_mask,
+ dropout_p=self.attn_drop.p if self.training else 0.,
+ )
+ else:
+ q = q * self.scale
+ attn = torch.bmm(q, k.transpose(-1, -2))
+ if attn_mask is not None:
+ attn += attn_mask
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ x = torch.bmm(attn, v)
+
+ if self.head_scale is not None:
+ x = x.view(N, self.num_heads, L, C) * self.head_scale
+ x = x.view(-1, L, C)
+
+ x = x.transpose(0, 1).reshape(L, N, C)
+
+ if self.batch_first:
+ x = x.transpose(0, 1)
+
+ x = self.out_proj(x)
+ x = self.out_drop(x)
+ return x
+
+
+class AttentionalPooler(nn.Module):
+ def __init__(
+ self,
+ d_model: int,
+ context_dim: int,
+ n_head: int = 8,
+ n_queries: int = 256,
+ norm_layer: Callable = LayerNorm,
+ ):
+ super().__init__()
+ self.query = nn.Parameter(torch.randn(n_queries, d_model))
+ self.attn = nn.MultiheadAttention(d_model, n_head, kdim=context_dim, vdim=context_dim, batch_first=True)
+ self.ln_q = norm_layer(d_model)
+ self.ln_k = norm_layer(context_dim)
+
+ def forward(self, x: torch.Tensor):
+ N = x.shape[0]
+ x = self.ln_k(x)
+ q = self.ln_q(self.query)
+ out = self.attn(q.unsqueeze(0).expand(N, -1, -1), x, x, need_weights=False)[0]
+ return out
+
+
+class ResidualAttentionBlock(nn.Module):
+ def __init__(
+ self,
+ d_model: int,
+ n_head: int,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ is_cross_attention: bool = False,
+ batch_first: bool = True,
+ ):
+ super().__init__()
+
+ self.ln_1 = norm_layer(d_model)
+ self.attn = nn.MultiheadAttention(d_model, n_head, batch_first=batch_first)
+ self.ls_1 = LayerScale(d_model, ls_init_value) if ls_init_value is not None else nn.Identity()
+ if is_cross_attention:
+ self.ln_1_kv = norm_layer(d_model)
+
+ self.ln_2 = norm_layer(d_model)
+ mlp_width = int(d_model * mlp_ratio)
+ self.mlp = nn.Sequential(OrderedDict([
+ ("c_fc", nn.Linear(d_model, mlp_width)),
+ ("gelu", act_layer()),
+ ("c_proj", nn.Linear(mlp_width, d_model))
+ ]))
+ self.ls_2 = LayerScale(d_model, ls_init_value) if ls_init_value is not None else nn.Identity()
+
+ def attention(
+ self,
+ q_x: torch.Tensor,
+ k_x: Optional[torch.Tensor] = None,
+ v_x: Optional[torch.Tensor] = None,
+ attn_mask: Optional[torch.Tensor] = None,
+ ):
+ k_x = k_x if k_x is not None else q_x
+ v_x = v_x if v_x is not None else q_x
+
+ attn_mask = attn_mask.to(q_x.dtype) if attn_mask is not None else None
+ return self.attn(
+ q_x, k_x, v_x, need_weights=False, attn_mask=attn_mask
+ )[0]
+
+ def forward(
+ self,
+ q_x: torch.Tensor,
+ k_x: Optional[torch.Tensor] = None,
+ v_x: Optional[torch.Tensor] = None,
+ attn_mask: Optional[torch.Tensor] = None,
+ ):
+ k_x = self.ln_1_kv(k_x) if hasattr(self, "ln_1_kv") and k_x is not None else None
+ v_x = self.ln_1_kv(v_x) if hasattr(self, "ln_1_kv") and v_x is not None else None
+ x = q_x + self.ls_1(self.attention(q_x=self.ln_1(q_x), k_x=k_x, v_x=v_x, attn_mask=attn_mask))
+ x = x + self.ls_2(self.mlp(self.ln_2(x)))
+ return x
+
+
+class CustomResidualAttentionBlock(nn.Module):
+ def __init__(
+ self,
+ d_model: int,
+ n_head: int,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ scale_cosine_attn: bool = False,
+ scale_heads: bool = False,
+ scale_attn: bool = False,
+ scale_fc: bool = False,
+ batch_first: bool = True,
+ ):
+ super().__init__()
+
+ self.ln_1 = norm_layer(d_model)
+ self.attn = Attention(
+ d_model,
+ n_head,
+ scaled_cosine=scale_cosine_attn,
+ scale_heads=scale_heads,
+ batch_first=batch_first,
+ )
+ self.ln_attn = norm_layer(d_model) if scale_attn else nn.Identity()
+ self.ls_1 = LayerScale(d_model, ls_init_value) if ls_init_value is not None else nn.Identity()
+
+ self.ln_2 = norm_layer(d_model)
+ mlp_width = int(d_model * mlp_ratio)
+ self.mlp = nn.Sequential(OrderedDict([
+ ("c_fc", nn.Linear(d_model, mlp_width)),
+ ("gelu", act_layer()),
+ ('ln', norm_layer(mlp_width) if scale_fc else nn.Identity()),
+ ("c_proj", nn.Linear(mlp_width, d_model))
+ ]))
+ self.ls_2 = LayerScale(d_model, ls_init_value) if ls_init_value is not None else nn.Identity()
+
+ def get_reference_weight(self):
+ return self.mlp.c_fc.weight
+
+ def forward(self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] = None):
+ x = x + self.ls_1(self.ln_attn(self.attn(self.ln_1(x), attn_mask=attn_mask)))
+ x = x + self.ls_2(self.mlp(self.ln_2(x)))
+ return x
+
+
+class CustomTransformer(nn.Module):
+ """ A custom transformer that can use different block types. """
+ def __init__(
+ self,
+ width: int,
+ layers: int,
+ heads: int,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ batch_first: bool = True,
+ block_types: Union[str, List[str]] = 'CustomResidualAttentionBlock',
+ ):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.batch_first = batch_first # run transformer stack in batch first (N, L, D)
+ self.grad_checkpointing = False
+
+ if isinstance(block_types, str):
+ block_types = [block_types] * layers
+ assert len(block_types) == layers
+
+ def _create_block(bt: str):
+ if bt == 'CustomResidualAttentionBlock':
+ return CustomResidualAttentionBlock(
+ width,
+ heads,
+ mlp_ratio=mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ batch_first=batch_first,
+ )
+ else:
+ assert False
+
+ self.resblocks = nn.ModuleList([
+ _create_block(bt)
+ for bt in block_types
+ ])
+
+ def get_cast_dtype(self) -> torch.dtype:
+ weight = self.resblocks[0].get_reference_weight()
+ if hasattr(weight, 'int8_original_dtype'):
+ return weight.int8_original_dtype
+ return weight.dtype
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ attn_mask: Optional[torch.Tensor] = None,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ ):
+ take_indices, max_index = feature_take_indices(len(self.resblocks), indices)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1).contiguous() # NLD -> LND
+
+ intermediates = []
+ if torch.jit.is_scripting() or not stop_early: # can't slice blocks in torchscript
+ blocks = self.resblocks
+ else:
+ blocks = self.resblocks[:max_index + 1]
+ for i, blk in enumerate(blocks):
+ if self.grad_checkpointing and not torch.jit.is_scripting():
+ x = checkpoint(blk, x, None, None, attn_mask, use_reentrant=False)
+ else:
+ x = blk(x, attn_mask=attn_mask)
+
+ if i in take_indices:
+ intermediates.append(x.transpose(0, 1) if not self.batch_first else x)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1) # LND -> NLD
+
+ return x, intermediates
+
+ def prune_intermediate_layers(self, indices: Union[int, List[int]] = 1):
+ """ Prune layers not required for specified intermediates.
+ """
+ take_indices, max_index = feature_take_indices(len(self.resblocks), indices)
+ self.resblocks = self.resblocks[:max_index + 1] # truncate blocks
+ return take_indices
+
+ def forward(self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] = None):
+ if not self.batch_first:
+ x = x.transpose(0, 1) # NLD -> LND
+
+ for r in self.resblocks:
+ if self.grad_checkpointing and not torch.jit.is_scripting():
+ # TODO: handle kwargs https://github.com/pytorch/pytorch/issues/79887#issuecomment-1161758372
+ x = checkpoint(r, x, None, None, attn_mask, use_reentrant=False)
+ else:
+ x = r(x, attn_mask=attn_mask)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1) # NLD -> LND
+ return x
+
+
+class Transformer(nn.Module):
+ def __init__(
+ self,
+ width: int,
+ layers: int,
+ heads: int,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ batch_first: bool = True,
+ ):
+ super().__init__()
+ self.width = width
+ self.layers = layers
+ self.batch_first = batch_first
+ self.grad_checkpointing = False
+
+ self.resblocks = nn.ModuleList([
+ ResidualAttentionBlock(
+ width,
+ heads,
+ mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ batch_first=batch_first,
+ )
+ for _ in range(layers)
+ ])
+
+ def get_cast_dtype(self) -> torch.dtype:
+ if hasattr(self.resblocks[0].mlp.c_fc, 'int8_original_dtype'):
+ return self.resblocks[0].mlp.c_fc.int8_original_dtype
+ return self.resblocks[0].mlp.c_fc.weight.dtype
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ attn_mask: Optional[torch.Tensor] = None,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ ):
+ take_indices, max_index = feature_take_indices(len(self.resblocks), indices)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1).contiguous() # NLD -> LND
+
+ intermediates = []
+ if torch.jit.is_scripting() or not stop_early: # can't slice blocks in torchscript
+ blocks = self.resblocks
+ else:
+ blocks = self.resblocks[:max_index + 1]
+ for i, blk in enumerate(blocks):
+ if self.grad_checkpointing and not torch.jit.is_scripting():
+ x = checkpoint(blk, x, None, None, attn_mask, use_reentrant=False)
+ else:
+ x = blk(x, attn_mask=attn_mask)
+
+ if i in take_indices:
+ intermediates.append(x.transpose(0, 1) if not self.batch_first else x)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1) # LND -> NLD
+
+ return x, intermediates
+
+ def prune_intermediate_layers(self, indices: Union[int, List[int]] = 1):
+ """ Prune layers not required for specified intermediates.
+ """
+ take_indices, max_index = feature_take_indices(len(self.resblocks), indices)
+ self.resblocks = self.resblocks[:max_index + 1] # truncate blocks
+ return take_indices
+
+ def forward(self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] = None):
+ if not self.batch_first:
+ x = x.transpose(0, 1).contiguous() # NLD -> LND
+
+ for r in self.resblocks:
+ if self.grad_checkpointing and not torch.jit.is_scripting():
+ # TODO: handle kwargs https://github.com/pytorch/pytorch/issues/79887#issuecomment-1161758372
+ x = checkpoint(r, x, None, None, attn_mask, use_reentrant=False)
+ else:
+ x = r(x, attn_mask=attn_mask)
+
+ if not self.batch_first:
+ x = x.transpose(0, 1) # LND -> NLD
+ return x
+
+
+def _expand_token(token, batch_size: int):
+ return token.view(1, 1, -1).expand(batch_size, -1, -1)
+
+
+class VisionTransformer(nn.Module):
+ output_tokens: torch.jit.Final[bool]
+
+ def __init__(
+ self,
+ image_size: int,
+ patch_size: int,
+ width: int,
+ layers: int,
+ heads: int,
+ mlp_ratio: float,
+ ls_init_value: float = None,
+ attentional_pool: bool = False,
+ attn_pooler_queries: int = 256,
+ attn_pooler_heads: int = 8,
+ output_dim: int = 512,
+ patch_dropout: float = 0.,
+ no_ln_pre: bool = False,
+ pos_embed_type: str = 'learnable',
+ pool_type: str = 'tok',
+ final_ln_after_pool: bool = False,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ output_tokens: bool = False,
+ in_chans: int = 3,
+ ):
+ super().__init__()
+ assert pool_type in ('tok', 'avg', 'none')
+ self.output_tokens = output_tokens
+ image_height, image_width = self.image_size = to_2tuple(image_size)
+ patch_height, patch_width = self.patch_size = to_2tuple(patch_size)
+ self.grid_size = (image_height // patch_height, image_width // patch_width)
+ self.final_ln_after_pool = final_ln_after_pool # currently ignored w/ attn pool enabled
+ self.output_dim = output_dim
+
+ self.conv1 = nn.Conv2d(
+ in_channels=in_chans,
+ out_channels=width,
+ kernel_size=patch_size,
+ stride=patch_size,
+ bias=False,
+ )
+
+ # class embeddings and positional embeddings
+ scale = width ** -0.5
+ self.class_embedding = nn.Parameter(scale * torch.randn(width))
+ if pos_embed_type == 'learnable':
+ self.positional_embedding = nn.Parameter(
+ scale * torch.randn(self.grid_size[0] * self.grid_size[1] + 1, width))
+ elif pos_embed_type == 'sin_cos_2d':
+ # fixed sin-cos embedding
+ assert self.grid_size[0] == self.grid_size[1],\
+ 'currently sin cos 2d pos embedding only supports square input'
+ self.positional_embedding = nn.Parameter(
+ torch.zeros(self.grid_size[0] * self.grid_size[1] + 1, width), requires_grad=False)
+ pos_embed_type = get_2d_sincos_pos_embed(width, self.grid_size[0], cls_token=True)
+ self.positional_embedding.data.copy_(torch.from_numpy(pos_embed_type).float())
+ else:
+ raise ValueError
+
+ # setting a patch_dropout of 0. would mean it is disabled and this function would be the identity fn
+ self.patch_dropout = PatchDropout(patch_dropout) if patch_dropout > 0. else nn.Identity()
+
+ self.ln_pre = nn.Identity() if no_ln_pre else norm_layer(width)
+ self.transformer = Transformer(
+ width,
+ layers,
+ heads,
+ mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ )
+
+ if attentional_pool:
+ if isinstance(attentional_pool, str):
+ self.attn_pool_type = attentional_pool
+ self.pool_type = 'none'
+ if attentional_pool in ('parallel', 'cascade'):
+ self.attn_pool = AttentionalPooler(
+ output_dim,
+ width,
+ n_head=attn_pooler_heads,
+ n_queries=attn_pooler_queries,
+ )
+ self.attn_pool_contrastive = AttentionalPooler(
+ output_dim,
+ width,
+ n_head=attn_pooler_heads,
+ n_queries=1,
+ )
+ else:
+ assert False
+ else:
+ self.attn_pool_type = ''
+ self.pool_type = pool_type
+ self.attn_pool = AttentionalPooler(
+ output_dim,
+ width,
+ n_head=attn_pooler_heads,
+ n_queries=attn_pooler_queries,
+ )
+ self.attn_pool_contrastive = None
+ pool_dim = output_dim
+ else:
+ self.attn_pool = None
+ pool_dim = width
+ self.pool_type = pool_type
+
+ self.ln_post = norm_layer(pool_dim)
+ self.proj = nn.Parameter(scale * torch.randn(pool_dim, output_dim))
+
+ self.init_parameters()
+
+ def lock(self, unlocked_groups: int = 0, freeze_bn_stats: bool = False):
+ for param in self.parameters():
+ param.requires_grad = False
+
+ if unlocked_groups != 0:
+ groups = [
+ [
+ self.conv1,
+ self.class_embedding,
+ self.positional_embedding,
+ self.ln_pre,
+ ],
+ *self.transformer.resblocks[:-1],
+ [
+ self.transformer.resblocks[-1],
+ self.ln_post,
+ ],
+ self.proj,
+ ]
+
+ def _unlock(x):
+ if isinstance(x, Sequence):
+ for g in x:
+ _unlock(g)
+ else:
+ if isinstance(x, torch.nn.Parameter):
+ x.requires_grad = True
+ else:
+ for p in x.parameters():
+ p.requires_grad = True
+
+ _unlock(groups[-unlocked_groups:])
+
+ def init_parameters(self):
+ # FIXME OpenAI CLIP did not define an init for the VisualTransformer
+ # TODO experiment if default PyTorch init, below, or alternate init is best.
+
+ # nn.init.normal_(self.class_embedding, std=self.scale)
+ # nn.init.normal_(self.positional_embedding, std=self.scale)
+ #
+ # proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
+ # attn_std = self.transformer.width ** -0.5
+ # fc_std = (2 * self.transformer.width) ** -0.5
+ # for block in self.transformer.resblocks:
+ # nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
+ # nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
+ # nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
+ # nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
+ #
+ # if self.text_projection is not None:
+ # nn.init.normal_(self.text_projection, std=self.scale)
+ pass
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable: bool = True):
+ self.transformer.grad_checkpointing = enable
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ # for timm optimizers, 1d params like logit_scale, logit_bias, ln/bn scale, biases are excluded by default
+ no_wd = {'positional_embedding', 'class_embedding'}
+ return no_wd
+
+ def _global_pool(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ if self.pool_type == 'avg':
+ pooled, tokens = x[:, 1:].mean(dim=1), x[:, 1:]
+ elif self.pool_type == 'tok':
+ pooled, tokens = x[:, 0], x[:, 1:]
+ else:
+ pooled = tokens = x
+
+ return pooled, tokens
+
+ def _embeds(self, x:torch.Tensor) -> torch.Tensor:
+ x = self.conv1(x) # shape = [*, dim, grid, grid]
+ x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
+ x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
+
+ # class embeddings and positional embeddings
+ x = torch.cat([_expand_token(self.class_embedding, x.shape[0]).to(x.dtype), x], dim=1)
+ # shape = [*, grid ** 2 + 1, width]
+ x = x + self.positional_embedding.to(x.dtype)
+
+ # patch dropout (if active)
+ x = self.patch_dropout(x)
+
+ # apply norm before transformer
+ x = self.ln_pre(x)
+ return x
+
+ def _pool(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ if self.attn_pool is not None:
+ if self.attn_pool_contrastive is not None:
+ # This is untested, WIP pooling that should match paper
+ x = self.ln_post(x) # TBD LN first or separate one after each pool?
+ tokens = self.attn_pool(x)
+ if self.attn_pool_type == 'parallel':
+ pooled = self.attn_pool_contrastive(x)
+ else:
+ assert self.attn_pool_type == 'cascade'
+ pooled = self.attn_pool_contrastive(tokens)
+ else:
+ # this is the original OpenCLIP CoCa setup, does not match paper
+ x = self.attn_pool(x)
+ x = self.ln_post(x)
+ pooled, tokens = self._global_pool(x)
+ elif self.final_ln_after_pool:
+ pooled, tokens = self._global_pool(x)
+ pooled = self.ln_post(pooled)
+ else:
+ x = self.ln_post(x)
+ pooled, tokens = self._global_pool(x)
+
+ return pooled, tokens
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ output_fmt: str = 'NCHW',
+ output_extra_tokens: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ x: Input image tensor
+ indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ intermediates_only: Only return intermediate features
+ normalize_intermediates: Apply final norm layer to all intermediates
+ output_fmt: Shape of intermediate feature outputs
+ output_extra_tokens: Return both extra prefix class tokens
+ Returns:
+
+ """
+ assert output_fmt in ('NCHW', 'NLC'), 'Output format must be one of NCHW or NLC.'
+ reshape = output_fmt == 'NCHW'
+
+ # forward pass
+ B, _, height, width = x.shape
+ x = self._embeds(x)
+ x, intermediates = self.transformer.forward_intermediates(
+ x,
+ indices=indices,
+ stop_early=stop_early,
+ )
+
+ # process intermediates
+ if normalize_intermediates:
+ # apply final norm to all intermediates
+ intermediates = [self.ln_post(xi) for xi in intermediates]
+ num_prefix_tokens = 1 # one class token that's always there (as of now)
+ if num_prefix_tokens:
+ # split prefix (e.g. class, distill) and spatial feature tokens
+ prefix_tokens = [y[:, 0:num_prefix_tokens] for y in intermediates]
+ intermediates = [y[:, num_prefix_tokens:] for y in intermediates]
+ else:
+ prefix_tokens = None
+ if reshape:
+ # reshape to BCHW output format
+ H, W = height // self.patch_size[0], width // self.patch_size[1]
+ intermediates = [y.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() for y in intermediates]
+
+ output = {'image_intermediates': intermediates}
+ if prefix_tokens is not None and output_extra_tokens:
+ output['image_intermediates_prefix'] = prefix_tokens
+
+ if intermediates_only:
+ return output
+
+ pooled, _ = self._pool(x)
+
+ if self.proj is not None:
+ pooled = pooled @ self.proj
+
+ output['image_features'] = pooled
+
+ return output
+
+ def prune_intermediate_layers(
+ self,
+ indices: Union[int, List[int]] = 1,
+ prune_norm: bool = False,
+ prune_head: bool = True,
+ ):
+ """ Prune layers not required for specified intermediates.
+ """
+ take_indices = self.transformer.prune_intermediate_layers(indices)
+ if prune_norm:
+ self.ln_post = nn.Identity()
+ if prune_head:
+ self.proj = None
+ return take_indices
+
+ def forward(self, x: torch.Tensor):
+ x = self._embeds(x)
+ x = self.transformer(x)
+ pooled, tokens = self._pool(x)
+
+ if self.proj is not None:
+ pooled = pooled @ self.proj
+
+ if self.output_tokens:
+ return pooled, tokens
+
+ return pooled
+
+
+def text_global_pool(
+ x: torch.Tensor,
+ text: Optional[torch.Tensor] = None,
+ pool_type: str = 'argmax',
+) -> torch.Tensor:
+ if pool_type == 'first':
+ pooled = x[:, 0]
+ elif pool_type == 'last':
+ pooled = x[:, -1]
+ elif pool_type == 'argmax':
+ # take features from the eot embedding (eot_token is the highest number in each sequence)
+ assert text is not None
+ pooled = x[torch.arange(x.shape[0]), text.argmax(dim=-1)]
+ else:
+ pooled = x
+
+ return pooled
+
+
+class TextTransformer(nn.Module):
+ output_tokens: torch.jit.Final[bool]
+
+ def __init__(
+ self,
+ context_length: int = 77,
+ vocab_size: int = 49408,
+ width: int = 512,
+ heads: int = 8,
+ layers: int = 12,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ output_dim: Optional[int] = 512,
+ embed_cls: bool = False,
+ no_causal_mask: bool = False,
+ pad_id: int = 0,
+ pool_type: str = 'argmax',
+ proj_type: str = 'linear',
+ proj_bias: bool = False,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ output_tokens: bool = False,
+ ):
+ super().__init__()
+ assert pool_type in ('first', 'last', 'argmax', 'none')
+ self.output_tokens = output_tokens
+ self.num_pos = self.context_length = context_length
+ self.vocab_size = vocab_size
+ self.width = width
+ self.output_dim = output_dim
+ self.heads = heads
+ self.pad_id = pad_id
+ self.pool_type = pool_type
+
+ self.token_embedding = nn.Embedding(vocab_size, width)
+ if embed_cls:
+ self.cls_emb = nn.Parameter(torch.empty(width))
+ self.num_pos += 1
+ else:
+ self.cls_emb = None
+ self.positional_embedding = nn.Parameter(torch.empty(self.num_pos, width))
+ self.transformer = Transformer(
+ width=width,
+ layers=layers,
+ heads=heads,
+ mlp_ratio=mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ )
+ self.ln_final = norm_layer(width)
+
+ if no_causal_mask:
+ self.attn_mask = None
+ else:
+ self.register_buffer('attn_mask', self.build_causal_mask(), persistent=False)
+
+ if proj_type == 'none' or not output_dim:
+ self.text_projection = None
+ else:
+ if proj_bias:
+ self.text_projection = nn.Linear(width, output_dim)
+ else:
+ self.text_projection = nn.Parameter(torch.empty(width, output_dim))
+
+ self.init_parameters()
+
+ def init_parameters(self):
+ nn.init.normal_(self.token_embedding.weight, std=0.02)
+ nn.init.normal_(self.positional_embedding, std=0.01)
+ if self.cls_emb is not None:
+ nn.init.normal_(self.cls_emb, std=0.01)
+
+ proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
+ attn_std = self.transformer.width ** -0.5
+ fc_std = (2 * self.transformer.width) ** -0.5
+ for block in self.transformer.resblocks:
+ nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
+ nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
+ nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
+ nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
+
+ if self.text_projection is not None:
+ if isinstance(self.text_projection, nn.Linear):
+ nn.init.normal_(self.text_projection.weight, std=self.transformer.width ** -0.5)
+ if self.text_projection.bias is not None:
+ nn.init.zeros_(self.text_projection.bias)
+ else:
+ nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable=True):
+ self.transformer.grad_checkpointing = enable
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ # for timm optimizers, 1d params like logit_scale, logit_bias, ln/bn scale, biases are excluded by default
+ no_wd = {'positional_embedding'}
+ if self.cls_emb is not None:
+ no_wd.add('cls_emb')
+ return no_wd
+
+ def build_causal_mask(self):
+ # lazily create causal attention mask, with full attention between the tokens
+ # pytorch uses additive attention mask; fill with -inf
+ mask = torch.empty(self.num_pos, self.num_pos)
+ mask.fill_(float("-inf"))
+ mask.triu_(1) # zero out the lower diagonal
+ return mask
+
+ def build_cls_mask(self, text, cast_dtype: torch.dtype):
+ cls_mask = (text != self.pad_id).unsqueeze(1)
+ cls_mask = F.pad(cls_mask, (1, 0, cls_mask.shape[2], 0), value=True)
+ additive_mask = torch.empty(cls_mask.shape, dtype=cast_dtype, device=cls_mask.device)
+ additive_mask.fill_(0)
+ additive_mask.masked_fill_(~cls_mask, float("-inf"))
+ additive_mask = torch.repeat_interleave(additive_mask, self.heads, 0)
+ return additive_mask
+
+ def _embeds(self, text) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
+ cast_dtype = self.transformer.get_cast_dtype()
+ seq_len = text.shape[1]
+ x = self.token_embedding(text).to(cast_dtype) # [batch_size, n_ctx, d_model]
+ attn_mask = self.attn_mask
+ if self.cls_emb is not None:
+ seq_len += 1
+ x = torch.cat([x, _expand_token(self.cls_emb, x.shape[0])], dim=1)
+ cls_mask = self.build_cls_mask(text, cast_dtype)
+ if attn_mask is not None:
+ attn_mask = attn_mask[None, :seq_len, :seq_len] + cls_mask[:, :seq_len, :seq_len]
+ x = x + self.positional_embedding[:seq_len].to(cast_dtype)
+ return x, attn_mask
+
+ def forward_intermediates(
+ self,
+ text: torch.Tensor,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ normalize_intermediates: bool = False,
+ intermediates_only: bool = False,
+ output_fmt: str = 'NCHW',
+ output_extra_tokens: bool = False,
+ ) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
+ """ Forward features that returns intermediates.
+
+ Args:
+ text: Input text ids
+ indices: Take last n blocks if int, all if None, select matching indices if sequence
+ stop_early: Stop iterating over blocks when last desired intermediate hit
+ normalize_intermediates: Apply norm layer to all intermediates
+ intermediates_only: Only return intermediate features
+ output_fmt: Shape of intermediate feature outputs
+ output_extra_tokens: Return both prefix and intermediate tokens
+ Returns:
+
+ """
+ assert output_fmt in ('NLC',), 'Output format must be NLC.'
+ # forward pass
+ x, attn_mask = self._embeds(text)
+ x, intermediates = self.transformer.forward_intermediates(
+ x,
+ attn_mask=attn_mask,
+ indices=indices,
+ stop_early=stop_early,
+ )
+
+ # process intermediates
+ if normalize_intermediates:
+ # apply final norm to all intermediates
+ intermediates = [self.ln_final(xi) for xi in intermediates]
+
+ output = {}
+
+ if self.cls_emb is not None:
+ seq_intermediates = [xi[:, :-1] for xi in intermediates] # separate concat'd class token from sequence
+ if output_extra_tokens:
+ # return suffix class tokens separately
+ cls_intermediates = [xi[:, -1:] for xi in intermediates]
+ output['text_intermediates_suffix'] = cls_intermediates
+ intermediates = seq_intermediates
+ output['text_intermediates'] = intermediates
+
+ if intermediates_only:
+ return output
+
+ if self.cls_emb is not None:
+ # presence of appended cls embed (CoCa) overrides pool_type, always take last token
+ pooled = text_global_pool(x, pool_type='last')
+ pooled = self.ln_final(pooled) # final LN applied after pooling in this case
+ else:
+ x = self.ln_final(x)
+ pooled = text_global_pool(x, text, pool_type=self.pool_type)
+
+ if self.text_projection is not None:
+ if isinstance(self.text_projection, nn.Linear):
+ pooled = self.text_projection(pooled)
+ else:
+ pooled = pooled @ self.text_projection
+
+ output['text_features'] = pooled
+
+ return output
+
+ def prune_intermediate_layers(
+ self,
+ indices: Union[int, List[int]] = 1,
+ prune_norm: bool = False,
+ prune_head: bool = True,
+ ):
+ """ Prune layers not required for specified intermediates.
+ """
+ take_indices = self.transformer.prune_intermediate_layers(indices)
+ if prune_norm:
+ self.ln_final = nn.Identity()
+ if prune_head:
+ self.text_projection = None
+ return take_indices
+
+ def forward(self, text):
+ x, attn_mask = self._embeds(text)
+
+ x = self.transformer(x, attn_mask=attn_mask)
+
+ # x.shape = [batch_size, n_ctx, transformer.width]
+ if self.cls_emb is not None:
+ # presence of appended cls embed (CoCa) overrides pool_type, always take last token
+ pooled = text_global_pool(x, pool_type='last')
+ pooled = self.ln_final(pooled) # final LN applied after pooling in this case
+ tokens = x[:, :-1]
+ else:
+ x = self.ln_final(x)
+ pooled = text_global_pool(x, text, pool_type=self.pool_type)
+ tokens = x
+
+ if self.text_projection is not None:
+ if isinstance(self.text_projection, nn.Linear):
+ pooled = self.text_projection(pooled)
+ else:
+ pooled = pooled @ self.text_projection
+
+ if self.output_tokens:
+ return pooled, tokens
+
+ return pooled
+
+
+class MultimodalTransformer(Transformer):
+ def __init__(
+ self,
+ width: int,
+ layers: int,
+ heads: int,
+ context_length: int = 77,
+ mlp_ratio: float = 4.0,
+ ls_init_value: float = None,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = LayerNorm,
+ output_dim: int = 512,
+ batch_first: bool = True,
+ ):
+ super().__init__(
+ width=width,
+ layers=layers,
+ heads=heads,
+ mlp_ratio=mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ batch_first=batch_first,
+ )
+ self.context_length = context_length
+ self.cross_attn = nn.ModuleList([
+ ResidualAttentionBlock(
+ width,
+ heads,
+ mlp_ratio,
+ ls_init_value=ls_init_value,
+ act_layer=act_layer,
+ norm_layer=norm_layer,
+ is_cross_attention=True,
+ batch_first=batch_first,
+ )
+ for _ in range(layers)
+ ])
+
+ self.register_buffer('attn_mask', self.build_attention_mask(), persistent=False)
+
+ self.ln_final = norm_layer(width)
+ self.text_projection = nn.Parameter(torch.empty(width, output_dim))
+
+ def init_parameters(self):
+ proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
+ attn_std = self.transformer.width ** -0.5
+ fc_std = (2 * self.transformer.width) ** -0.5
+ for block in self.transformer.resblocks:
+ nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
+ nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
+ nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
+ nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
+ for block in self.transformer.cross_attn:
+ nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
+ nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
+ nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
+ nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
+
+ if self.text_projection is not None:
+ nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
+
+ def build_attention_mask(self):
+ # lazily create causal attention mask, with full attention between the tokens
+ # pytorch uses additive attention mask; fill with -inf
+ mask = torch.empty(self.context_length, self.context_length)
+ mask.fill_(float("-inf"))
+ mask.triu_(1) # zero out the lower diagonal
+ return mask
+
+ def forward_intermediates(
+ self,
+ x: torch.Tensor,
+ attn_mask: Optional[torch.Tensor] = None,
+ indices: Optional[Union[int, List[int]]] = None,
+ stop_early: bool = False,
+ ):
+ assert False, "Not currently implemented for MultimodalTransformer w/ xattn"
+
+ def forward(self, image_embs, text_embs):
+ seq_len = text_embs.shape[1]
+ if not self.batch_first:
+ image_embs = image_embs.permute(1, 0, 2) # NLD -> LND
+ text_embs = text_embs.permute(1, 0, 2) # NLD -> LND
+
+ for resblock, cross_attn in zip(self.resblocks, self.cross_attn):
+ if self.grad_checkpointing and not torch.jit.is_scripting():
+ # TODO: handle kwargs https://github.com/pytorch/pytorch/issues/79887#issuecomment-1161758372
+ text_embs = checkpoint(
+ resblock, text_embs, None, None, self.attn_mask[:seq_len, :seq_len], use_reentrant=False)
+ text_embs = checkpoint(
+ cross_attn, text_embs, image_embs, image_embs, None, use_reentrant=False)
+ else:
+ text_embs = resblock(text_embs, attn_mask=self.attn_mask[:seq_len, :seq_len])
+ text_embs = cross_attn(text_embs, k_x=image_embs, v_x=image_embs)
+
+ if not self.batch_first:
+ text_embs = text_embs.permute(1, 0, 2) # LND -> NLD
+
+ out = self.ln_final(text_embs)
+ if self.text_projection is not None:
+ out = out @ self.text_projection
+
+ return out
+
+ @torch.jit.ignore
+ def set_grad_checkpointing(self, enable=True):
+ self.grad_checkpointing = enable
diff --git a/src/open_clip/utils.py b/src/open_clip/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..dea3baca1cedb3c73b4af5aff058e2153ff34176
--- /dev/null
+++ b/src/open_clip/utils.py
@@ -0,0 +1,139 @@
+import collections.abc
+from itertools import repeat
+from typing import List, Optional, Tuple, Union
+
+import torch
+from torch import nn as nn
+from torch import _assert
+from torchvision.ops.misc import FrozenBatchNorm2d
+
+
+def freeze_batch_norm_2d(module, module_match={}, name=''):
+ """
+ Converts all `BatchNorm2d` and `SyncBatchNorm` layers of provided module into `FrozenBatchNorm2d`. If `module` is
+ itself an instance of either `BatchNorm2d` or `SyncBatchNorm`, it is converted into `FrozenBatchNorm2d` and
+ returned. Otherwise, the module is walked recursively and submodules are converted in place.
+
+ Args:
+ module (torch.nn.Module): Any PyTorch module.
+ module_match (dict): Dictionary of full module names to freeze (all if empty)
+ name (str): Full module name (prefix)
+
+ Returns:
+ torch.nn.Module: Resulting module
+
+ Inspired by https://github.com/pytorch/pytorch/blob/a5895f85be0f10212791145bfedc0261d364f103/torch/nn/modules/batchnorm.py#L762
+ """
+ res = module
+ is_match = True
+ if module_match:
+ is_match = name in module_match
+ if is_match and isinstance(module, (nn.modules.batchnorm.BatchNorm2d, nn.modules.batchnorm.SyncBatchNorm)):
+ res = FrozenBatchNorm2d(module.num_features)
+ res.num_features = module.num_features
+ res.affine = module.affine
+ if module.affine:
+ res.weight.data = module.weight.data.clone().detach()
+ res.bias.data = module.bias.data.clone().detach()
+ res.running_mean.data = module.running_mean.data
+ res.running_var.data = module.running_var.data
+ res.eps = module.eps
+ else:
+ for child_name, child in module.named_children():
+ full_child_name = '.'.join([name, child_name]) if name else child_name
+ new_child = freeze_batch_norm_2d(child, module_match, full_child_name)
+ if new_child is not child:
+ res.add_module(child_name, new_child)
+ return res
+
+
+# From PyTorch internals
+def _ntuple(n):
+ def parse(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return tuple(repeat(x, n))
+ return parse
+
+
+to_1tuple = _ntuple(1)
+to_2tuple = _ntuple(2)
+to_3tuple = _ntuple(3)
+to_4tuple = _ntuple(4)
+to_ntuple = lambda n, x: _ntuple(n)(x)
+
+# Replaces all linear layers with linear_replacement
+# TODO: add int8 support for other linear layers including attn and convnets
+def replace_linear(model, linear_replacement, include_modules=['c_fc', 'c_proj'], copy_weights=True):
+ for name, module in model.named_children():
+ if len(list(module.children())) > 0:
+ replace_linear(module, linear_replacement, include_modules, copy_weights)
+
+ if isinstance(module, torch.nn.Linear) and name in include_modules:
+ old_module = model._modules[name]
+ model._modules[name] = linear_replacement(
+ module.in_features,
+ module.out_features,
+ module.bias is not None,
+ )
+ if copy_weights:
+ model._modules[name].weight.data.copy_(old_module.weight.data)
+ if model._modules[name].bias is not None:
+ model._modules[name].bias.data.copy_(old_module.bias)
+
+ return model
+
+def convert_int8_model_to_inference_mode(model):
+ for m in model.modules():
+ if hasattr(m, 'prepare_for_eval'):
+ int8_original_dtype = m.weight.dtype
+ m.prepare_for_eval()
+ m.int8_original_dtype = int8_original_dtype
+
+
+def feature_take_indices(
+ num_features: int,
+ indices: Optional[Union[int, List[int]]] = None,
+ as_set: bool = False,
+) -> Tuple[List[int], int]:
+ """ Determine the absolute feature indices to 'take' from.
+
+ Note: This function can be called in forward() so must be torchscript compatible,
+ which requires some incomplete typing and workaround hacks.
+
+ Args:
+ num_features: total number of features to select from
+ indices: indices to select,
+ None -> select all
+ int -> select last n
+ list/tuple of int -> return specified (-ve indices specify from end)
+ as_set: return as a set
+
+ Returns:
+ List (or set) of absolute (from beginning) indices, Maximum index
+ """
+ if indices is None:
+ indices = num_features # all features if None
+
+ if isinstance(indices, int):
+ # convert int -> last n indices
+ _assert(0 < indices <= num_features, f'last-n ({indices}) is out of range (1 to {num_features})')
+ take_indices = [num_features - indices + i for i in range(indices)]
+ else:
+ take_indices: List[int] = []
+ for i in indices:
+ idx = num_features + i if i < 0 else i
+ _assert(0 <= idx < num_features, f'feature index {idx} is out of range (0 to {num_features - 1})')
+ take_indices.append(idx)
+
+ if not torch.jit.is_scripting() and as_set:
+ return set(take_indices), max(take_indices)
+
+ return take_indices, max(take_indices)
+
+
+def _out_indices_as_tuple(x: Union[int, Tuple[int, ...]]) -> Tuple[int, ...]:
+ if isinstance(x, int):
+ # if indices is an int, take last N features
+ return tuple(range(-x, 0))
+ return tuple(x)
diff --git a/src/open_clip/version.py b/src/open_clip/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c4735aefe043ba4f36ae7d8c76596fdbd5e7c6c
--- /dev/null
+++ b/src/open_clip/version.py
@@ -0,0 +1 @@
+__version__ = '2.32.0'
diff --git a/src/open_clip/zero_shot_classifier.py b/src/open_clip/zero_shot_classifier.py
new file mode 100644
index 0000000000000000000000000000000000000000..535ec9696d27a1dcbe2c43da18f5fd20b599cb9b
--- /dev/null
+++ b/src/open_clip/zero_shot_classifier.py
@@ -0,0 +1,110 @@
+from functools import partial
+from itertools import islice
+from typing import Callable, List, Optional, Sequence, Union
+
+import torch
+import torch.nn.functional as F
+
+
+def batched(iterable, n):
+ """Batch data into lists of length *n*. The last batch may be shorter.
+ NOTE based on more-itertools impl, to be replaced by python 3.12 itertools.batched impl
+ """
+ it = iter(iterable)
+ while True:
+ batch = list(islice(it, n))
+ if not batch:
+ break
+ yield batch
+
+
+def build_zero_shot_classifier(
+ model,
+ tokenizer,
+ classnames: Sequence[str],
+ templates: Sequence[Union[Callable, str]],
+ num_classes_per_batch: Optional[int] = 10,
+ device: Union[str, torch.device] = 'cpu',
+ use_tqdm: bool = False,
+):
+ """ Build zero-shot classifier weights by iterating over class names in batches
+ Args:
+ model: CLIP model instance
+ tokenizer: CLIP tokenizer instance
+ classnames: A sequence of class (label) names
+ templates: A sequence of callables or format() friendly strings to produce templates per class name
+ num_classes_per_batch: The number of classes to batch together in each forward, all if None
+ device: Device to use.
+ use_tqdm: Enable TQDM progress bar.
+ """
+ assert isinstance(templates, Sequence) and len(templates) > 0
+ assert isinstance(classnames, Sequence) and len(classnames) > 0
+ use_format = isinstance(templates[0], str)
+ num_templates = len(templates)
+ num_classes = len(classnames)
+ if use_tqdm:
+ import tqdm
+ num_iter = 1 if num_classes_per_batch is None else ((num_classes - 1) // num_classes_per_batch + 1)
+ iter_wrap = partial(tqdm.tqdm, total=num_iter, unit_scale=num_classes_per_batch)
+ else:
+ iter_wrap = iter
+
+ def _process_batch(batch_classnames):
+ num_batch_classes = len(batch_classnames)
+ texts = [template.format(c) if use_format else template(c) for c in batch_classnames for template in templates]
+ texts = tokenizer(texts).to(device)
+ class_embeddings = model.encode_text(texts, normalize=True)
+ class_embeddings = class_embeddings.reshape(num_batch_classes, num_templates, -1).mean(dim=1)
+ class_embeddings = class_embeddings / class_embeddings.norm(dim=1, keepdim=True)
+ class_embeddings = class_embeddings.T
+ return class_embeddings
+
+ with torch.no_grad():
+ if num_classes_per_batch:
+ batched_embeds = [_process_batch(batch) for batch in iter_wrap(batched(classnames, num_classes_per_batch))]
+ zeroshot_weights = torch.cat(batched_embeds, dim=1)
+ else:
+ zeroshot_weights = _process_batch(classnames)
+ return zeroshot_weights
+
+
+def build_zero_shot_classifier_legacy(
+ model,
+ tokenizer,
+ classnames: Sequence[str],
+ templates: Sequence[Union[Callable, str]],
+ device: Union[str, torch.device] = 'cpu',
+ use_tqdm: bool = False,
+):
+ """ Build zero-shot classifier weights by iterating over class names 1 by 1
+ Args:
+ model: CLIP model instance
+ tokenizer: CLIP tokenizer instance
+ classnames: A sequence of class (label) names
+ templates: A sequence of callables or format() friendly strings to produce templates per class name
+ device: Device to use.
+ use_tqdm: Enable TQDM progress bar.
+ """
+ assert isinstance(templates, Sequence) and len(templates) > 0
+ assert isinstance(classnames, Sequence) and len(classnames) > 0
+ if use_tqdm:
+ import tqdm
+ iter_wrap = tqdm.tqdm
+ else:
+ iter_wrap = iter
+
+ use_format = isinstance(templates[0], str)
+
+ with torch.no_grad():
+ zeroshot_weights = []
+ for classname in iter_wrap(classnames):
+ texts = [template.format(classname) if use_format else template(classname) for template in templates]
+ texts = tokenizer(texts).to(device) # tokenize
+ class_embeddings = model.encode_text(texts)
+ class_embedding = F.normalize(class_embeddings, dim=-1).mean(dim=0)
+ class_embedding /= class_embedding.norm()
+ zeroshot_weights.append(class_embedding)
+ zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(device)
+
+ return zeroshot_weights
+
diff --git a/src/open_clip/zero_shot_metadata.py b/src/open_clip/zero_shot_metadata.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccb452bbb6e27b71cff1dd27e2bb263259b9363f
--- /dev/null
+++ b/src/open_clip/zero_shot_metadata.py
@@ -0,0 +1,266 @@
+
+OPENAI_IMAGENET_TEMPLATES = (
+ lambda c: f'a bad photo of a {c}.',
+ lambda c: f'a photo of many {c}.',
+ lambda c: f'a sculpture of a {c}.',
+ lambda c: f'a photo of the hard to see {c}.',
+ lambda c: f'a low resolution photo of the {c}.',
+ lambda c: f'a rendering of a {c}.',
+ lambda c: f'graffiti of a {c}.',
+ lambda c: f'a bad photo of the {c}.',
+ lambda c: f'a cropped photo of the {c}.',
+ lambda c: f'a tattoo of a {c}.',
+ lambda c: f'the embroidered {c}.',
+ lambda c: f'a photo of a hard to see {c}.',
+ lambda c: f'a bright photo of a {c}.',
+ lambda c: f'a photo of a clean {c}.',
+ lambda c: f'a photo of a dirty {c}.',
+ lambda c: f'a dark photo of the {c}.',
+ lambda c: f'a drawing of a {c}.',
+ lambda c: f'a photo of my {c}.',
+ lambda c: f'the plastic {c}.',
+ lambda c: f'a photo of the cool {c}.',
+ lambda c: f'a close-up photo of a {c}.',
+ lambda c: f'a black and white photo of the {c}.',
+ lambda c: f'a painting of the {c}.',
+ lambda c: f'a painting of a {c}.',
+ lambda c: f'a pixelated photo of the {c}.',
+ lambda c: f'a sculpture of the {c}.',
+ lambda c: f'a bright photo of the {c}.',
+ lambda c: f'a cropped photo of a {c}.',
+ lambda c: f'a plastic {c}.',
+ lambda c: f'a photo of the dirty {c}.',
+ lambda c: f'a jpeg corrupted photo of a {c}.',
+ lambda c: f'a blurry photo of the {c}.',
+ lambda c: f'a photo of the {c}.',
+ lambda c: f'a good photo of the {c}.',
+ lambda c: f'a rendering of the {c}.',
+ lambda c: f'a {c} in a video game.',
+ lambda c: f'a photo of one {c}.',
+ lambda c: f'a doodle of a {c}.',
+ lambda c: f'a close-up photo of the {c}.',
+ lambda c: f'a photo of a {c}.',
+ lambda c: f'the origami {c}.',
+ lambda c: f'the {c} in a video game.',
+ lambda c: f'a sketch of a {c}.',
+ lambda c: f'a doodle of the {c}.',
+ lambda c: f'a origami {c}.',
+ lambda c: f'a low resolution photo of a {c}.',
+ lambda c: f'the toy {c}.',
+ lambda c: f'a rendition of the {c}.',
+ lambda c: f'a photo of the clean {c}.',
+ lambda c: f'a photo of a large {c}.',
+ lambda c: f'a rendition of a {c}.',
+ lambda c: f'a photo of a nice {c}.',
+ lambda c: f'a photo of a weird {c}.',
+ lambda c: f'a blurry photo of a {c}.',
+ lambda c: f'a cartoon {c}.',
+ lambda c: f'art of a {c}.',
+ lambda c: f'a sketch of the {c}.',
+ lambda c: f'a embroidered {c}.',
+ lambda c: f'a pixelated photo of a {c}.',
+ lambda c: f'itap of the {c}.',
+ lambda c: f'a jpeg corrupted photo of the {c}.',
+ lambda c: f'a good photo of a {c}.',
+ lambda c: f'a plushie {c}.',
+ lambda c: f'a photo of the nice {c}.',
+ lambda c: f'a photo of the small {c}.',
+ lambda c: f'a photo of the weird {c}.',
+ lambda c: f'the cartoon {c}.',
+ lambda c: f'art of the {c}.',
+ lambda c: f'a drawing of the {c}.',
+ lambda c: f'a photo of the large {c}.',
+ lambda c: f'a black and white photo of a {c}.',
+ lambda c: f'the plushie {c}.',
+ lambda c: f'a dark photo of a {c}.',
+ lambda c: f'itap of a {c}.',
+ lambda c: f'graffiti of the {c}.',
+ lambda c: f'a toy {c}.',
+ lambda c: f'itap of my {c}.',
+ lambda c: f'a photo of a cool {c}.',
+ lambda c: f'a photo of a small {c}.',
+ lambda c: f'a tattoo of the {c}.',
+)
+
+
+# a much smaller subset of above prompts
+# from https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
+SIMPLE_IMAGENET_TEMPLATES = (
+ lambda c: f'itap of a {c}.',
+ lambda c: f'a bad photo of the {c}.',
+ lambda c: f'a origami {c}.',
+ lambda c: f'a photo of the large {c}.',
+ lambda c: f'a {c} in a video game.',
+ lambda c: f'art of the {c}.',
+ lambda c: f'a photo of the small {c}.',
+)
+
+
+IMAGENET_CLASSNAMES = (
+ "tench", "goldfish", "great white shark", "tiger shark", "hammerhead shark", "electric ray",
+ "stingray", "rooster", "hen", "ostrich", "brambling", "goldfinch", "house finch", "junco",
+ "indigo bunting", "American robin", "bulbul", "jay", "magpie", "chickadee", "American dipper",
+ "kite (bird of prey)", "bald eagle", "vulture", "great grey owl", "fire salamander",
+ "smooth newt", "newt", "spotted salamander", "axolotl", "American bullfrog", "tree frog",
+ "tailed frog", "loggerhead sea turtle", "leatherback sea turtle", "mud turtle", "terrapin",
+ "box turtle", "banded gecko", "green iguana", "Carolina anole",
+ "desert grassland whiptail lizard", "agama", "frilled-necked lizard", "alligator lizard",
+ "Gila monster", "European green lizard", "chameleon", "Komodo dragon", "Nile crocodile",
+ "American alligator", "triceratops", "worm snake", "ring-necked snake",
+ "eastern hog-nosed snake", "smooth green snake", "kingsnake", "garter snake", "water snake",
+ "vine snake", "night snake", "boa constrictor", "African rock python", "Indian cobra",
+ "green mamba", "sea snake", "Saharan horned viper", "eastern diamondback rattlesnake",
+ "sidewinder rattlesnake", "trilobite", "harvestman", "scorpion", "yellow garden spider",
+ "barn spider", "European garden spider", "southern black widow", "tarantula", "wolf spider",
+ "tick", "centipede", "black grouse", "ptarmigan", "ruffed grouse", "prairie grouse", "peafowl",
+ "quail", "partridge", "african grey parrot", "macaw", "sulphur-crested cockatoo", "lorikeet",
+ "coucal", "bee eater", "hornbill", "hummingbird", "jacamar", "toucan", "duck",
+ "red-breasted merganser", "goose", "black swan", "tusker", "echidna", "platypus", "wallaby",
+ "koala", "wombat", "jellyfish", "sea anemone", "brain coral", "flatworm", "nematode", "conch",
+ "snail", "slug", "sea slug", "chiton", "chambered nautilus", "Dungeness crab", "rock crab",
+ "fiddler crab", "red king crab", "American lobster", "spiny lobster", "crayfish", "hermit crab",
+ "isopod", "white stork", "black stork", "spoonbill", "flamingo", "little blue heron",
+ "great egret", "bittern bird", "crane bird", "limpkin", "common gallinule", "American coot",
+ "bustard", "ruddy turnstone", "dunlin", "common redshank", "dowitcher", "oystercatcher",
+ "pelican", "king penguin", "albatross", "grey whale", "killer whale", "dugong", "sea lion",
+ "Chihuahua", "Japanese Chin", "Maltese", "Pekingese", "Shih Tzu", "King Charles Spaniel",
+ "Papillon", "toy terrier", "Rhodesian Ridgeback", "Afghan Hound", "Basset Hound", "Beagle",
+ "Bloodhound", "Bluetick Coonhound", "Black and Tan Coonhound", "Treeing Walker Coonhound",
+ "English foxhound", "Redbone Coonhound", "borzoi", "Irish Wolfhound", "Italian Greyhound",
+ "Whippet", "Ibizan Hound", "Norwegian Elkhound", "Otterhound", "Saluki", "Scottish Deerhound",
+ "Weimaraner", "Staffordshire Bull Terrier", "American Staffordshire Terrier",
+ "Bedlington Terrier", "Border Terrier", "Kerry Blue Terrier", "Irish Terrier",
+ "Norfolk Terrier", "Norwich Terrier", "Yorkshire Terrier", "Wire Fox Terrier",
+ "Lakeland Terrier", "Sealyham Terrier", "Airedale Terrier", "Cairn Terrier",
+ "Australian Terrier", "Dandie Dinmont Terrier", "Boston Terrier", "Miniature Schnauzer",
+ "Giant Schnauzer", "Standard Schnauzer", "Scottish Terrier", "Tibetan Terrier",
+ "Australian Silky Terrier", "Soft-coated Wheaten Terrier", "West Highland White Terrier",
+ "Lhasa Apso", "Flat-Coated Retriever", "Curly-coated Retriever", "Golden Retriever",
+ "Labrador Retriever", "Chesapeake Bay Retriever", "German Shorthaired Pointer", "Vizsla",
+ "English Setter", "Irish Setter", "Gordon Setter", "Brittany dog", "Clumber Spaniel",
+ "English Springer Spaniel", "Welsh Springer Spaniel", "Cocker Spaniel", "Sussex Spaniel",
+ "Irish Water Spaniel", "Kuvasz", "Schipperke", "Groenendael dog", "Malinois", "Briard",
+ "Australian Kelpie", "Komondor", "Old English Sheepdog", "Shetland Sheepdog", "collie",
+ "Border Collie", "Bouvier des Flandres dog", "Rottweiler", "German Shepherd Dog", "Dobermann",
+ "Miniature Pinscher", "Greater Swiss Mountain Dog", "Bernese Mountain Dog",
+ "Appenzeller Sennenhund", "Entlebucher Sennenhund", "Boxer", "Bullmastiff", "Tibetan Mastiff",
+ "French Bulldog", "Great Dane", "St. Bernard", "husky", "Alaskan Malamute", "Siberian Husky",
+ "Dalmatian", "Affenpinscher", "Basenji", "pug", "Leonberger", "Newfoundland dog",
+ "Great Pyrenees dog", "Samoyed", "Pomeranian", "Chow Chow", "Keeshond", "brussels griffon",
+ "Pembroke Welsh Corgi", "Cardigan Welsh Corgi", "Toy Poodle", "Miniature Poodle",
+ "Standard Poodle", "Mexican hairless dog (xoloitzcuintli)", "grey wolf", "Alaskan tundra wolf",
+ "red wolf or maned wolf", "coyote", "dingo", "dhole", "African wild dog", "hyena", "red fox",
+ "kit fox", "Arctic fox", "grey fox", "tabby cat", "tiger cat", "Persian cat", "Siamese cat",
+ "Egyptian Mau", "cougar", "lynx", "leopard", "snow leopard", "jaguar", "lion", "tiger",
+ "cheetah", "brown bear", "American black bear", "polar bear", "sloth bear", "mongoose",
+ "meerkat", "tiger beetle", "ladybug", "ground beetle", "longhorn beetle", "leaf beetle",
+ "dung beetle", "rhinoceros beetle", "weevil", "fly", "bee", "ant", "grasshopper",
+ "cricket insect", "stick insect", "cockroach", "praying mantis", "cicada", "leafhopper",
+ "lacewing", "dragonfly", "damselfly", "red admiral butterfly", "ringlet butterfly",
+ "monarch butterfly", "small white butterfly", "sulphur butterfly", "gossamer-winged butterfly",
+ "starfish", "sea urchin", "sea cucumber", "cottontail rabbit", "hare", "Angora rabbit",
+ "hamster", "porcupine", "fox squirrel", "marmot", "beaver", "guinea pig", "common sorrel horse",
+ "zebra", "pig", "wild boar", "warthog", "hippopotamus", "ox", "water buffalo", "bison",
+ "ram (adult male sheep)", "bighorn sheep", "Alpine ibex", "hartebeest", "impala (antelope)",
+ "gazelle", "arabian camel", "llama", "weasel", "mink", "European polecat",
+ "black-footed ferret", "otter", "skunk", "badger", "armadillo", "three-toed sloth", "orangutan",
+ "gorilla", "chimpanzee", "gibbon", "siamang", "guenon", "patas monkey", "baboon", "macaque",
+ "langur", "black-and-white colobus", "proboscis monkey", "marmoset", "white-headed capuchin",
+ "howler monkey", "titi monkey", "Geoffroy's spider monkey", "common squirrel monkey",
+ "ring-tailed lemur", "indri", "Asian elephant", "African bush elephant", "red panda",
+ "giant panda", "snoek fish", "eel", "silver salmon", "rock beauty fish", "clownfish",
+ "sturgeon", "gar fish", "lionfish", "pufferfish", "abacus", "abaya", "academic gown",
+ "accordion", "acoustic guitar", "aircraft carrier", "airliner", "airship", "altar", "ambulance",
+ "amphibious vehicle", "analog clock", "apiary", "apron", "trash can", "assault rifle",
+ "backpack", "bakery", "balance beam", "balloon", "ballpoint pen", "Band-Aid", "banjo",
+ "baluster / handrail", "barbell", "barber chair", "barbershop", "barn", "barometer", "barrel",
+ "wheelbarrow", "baseball", "basketball", "bassinet", "bassoon", "swimming cap", "bath towel",
+ "bathtub", "station wagon", "lighthouse", "beaker", "military hat (bearskin or shako)",
+ "beer bottle", "beer glass", "bell tower", "baby bib", "tandem bicycle", "bikini",
+ "ring binder", "binoculars", "birdhouse", "boathouse", "bobsleigh", "bolo tie", "poke bonnet",
+ "bookcase", "bookstore", "bottle cap", "hunting bow", "bow tie", "brass memorial plaque", "bra",
+ "breakwater", "breastplate", "broom", "bucket", "buckle", "bulletproof vest",
+ "high-speed train", "butcher shop", "taxicab", "cauldron", "candle", "cannon", "canoe",
+ "can opener", "cardigan", "car mirror", "carousel", "tool kit", "cardboard box / carton",
+ "car wheel", "automated teller machine", "cassette", "cassette player", "castle", "catamaran",
+ "CD player", "cello", "mobile phone", "chain", "chain-link fence", "chain mail", "chainsaw",
+ "storage chest", "chiffonier", "bell or wind chime", "china cabinet", "Christmas stocking",
+ "church", "movie theater", "cleaver", "cliff dwelling", "cloak", "clogs", "cocktail shaker",
+ "coffee mug", "coffeemaker", "spiral or coil", "combination lock", "computer keyboard",
+ "candy store", "container ship", "convertible", "corkscrew", "cornet", "cowboy boot",
+ "cowboy hat", "cradle", "construction crane", "crash helmet", "crate", "infant bed",
+ "Crock Pot", "croquet ball", "crutch", "cuirass", "dam", "desk", "desktop computer",
+ "rotary dial telephone", "diaper", "digital clock", "digital watch", "dining table",
+ "dishcloth", "dishwasher", "disc brake", "dock", "dog sled", "dome", "doormat", "drilling rig",
+ "drum", "drumstick", "dumbbell", "Dutch oven", "electric fan", "electric guitar",
+ "electric locomotive", "entertainment center", "envelope", "espresso machine", "face powder",
+ "feather boa", "filing cabinet", "fireboat", "fire truck", "fire screen", "flagpole", "flute",
+ "folding chair", "football helmet", "forklift", "fountain", "fountain pen", "four-poster bed",
+ "freight car", "French horn", "frying pan", "fur coat", "garbage truck",
+ "gas mask or respirator", "gas pump", "goblet", "go-kart", "golf ball", "golf cart", "gondola",
+ "gong", "gown", "grand piano", "greenhouse", "radiator grille", "grocery store", "guillotine",
+ "hair clip", "hair spray", "half-track", "hammer", "hamper", "hair dryer", "hand-held computer",
+ "handkerchief", "hard disk drive", "harmonica", "harp", "combine harvester", "hatchet",
+ "holster", "home theater", "honeycomb", "hook", "hoop skirt", "gymnastic horizontal bar",
+ "horse-drawn vehicle", "hourglass", "iPod", "clothes iron", "carved pumpkin", "jeans", "jeep",
+ "T-shirt", "jigsaw puzzle", "rickshaw", "joystick", "kimono", "knee pad", "knot", "lab coat",
+ "ladle", "lampshade", "laptop computer", "lawn mower", "lens cap", "letter opener", "library",
+ "lifeboat", "lighter", "limousine", "ocean liner", "lipstick", "slip-on shoe", "lotion",
+ "music speaker", "loupe magnifying glass", "sawmill", "magnetic compass", "messenger bag",
+ "mailbox", "tights", "one-piece bathing suit", "manhole cover", "maraca", "marimba", "mask",
+ "matchstick", "maypole", "maze", "measuring cup", "medicine cabinet", "megalith", "microphone",
+ "microwave oven", "military uniform", "milk can", "minibus", "miniskirt", "minivan", "missile",
+ "mitten", "mixing bowl", "mobile home", "ford model t", "modem", "monastery", "monitor",
+ "moped", "mortar and pestle", "graduation cap", "mosque", "mosquito net", "vespa",
+ "mountain bike", "tent", "computer mouse", "mousetrap", "moving van", "muzzle", "metal nail",
+ "neck brace", "necklace", "baby pacifier", "notebook computer", "obelisk", "oboe", "ocarina",
+ "odometer", "oil filter", "pipe organ", "oscilloscope", "overskirt", "bullock cart",
+ "oxygen mask", "product packet / packaging", "paddle", "paddle wheel", "padlock", "paintbrush",
+ "pajamas", "palace", "pan flute", "paper towel", "parachute", "parallel bars", "park bench",
+ "parking meter", "railroad car", "patio", "payphone", "pedestal", "pencil case",
+ "pencil sharpener", "perfume", "Petri dish", "photocopier", "plectrum", "Pickelhaube",
+ "picket fence", "pickup truck", "pier", "piggy bank", "pill bottle", "pillow", "ping-pong ball",
+ "pinwheel", "pirate ship", "drink pitcher", "block plane", "planetarium", "plastic bag",
+ "plate rack", "farm plow", "plunger", "Polaroid camera", "pole", "police van", "poncho",
+ "pool table", "soda bottle", "plant pot", "potter's wheel", "power drill", "prayer rug",
+ "printer", "prison", "missile", "projector", "hockey puck", "punching bag", "purse", "quill",
+ "quilt", "race car", "racket", "radiator", "radio", "radio telescope", "rain barrel",
+ "recreational vehicle", "fishing casting reel", "reflex camera", "refrigerator",
+ "remote control", "restaurant", "revolver", "rifle", "rocking chair", "rotisserie", "eraser",
+ "rugby ball", "ruler measuring stick", "sneaker", "safe", "safety pin", "salt shaker", "sandal",
+ "sarong", "saxophone", "scabbard", "weighing scale", "school bus", "schooner", "scoreboard",
+ "CRT monitor", "screw", "screwdriver", "seat belt", "sewing machine", "shield", "shoe store",
+ "shoji screen / room divider", "shopping basket", "shopping cart", "shovel", "shower cap",
+ "shower curtain", "ski", "balaclava ski mask", "sleeping bag", "slide rule", "sliding door",
+ "slot machine", "snorkel", "snowmobile", "snowplow", "soap dispenser", "soccer ball", "sock",
+ "solar thermal collector", "sombrero", "soup bowl", "keyboard space bar", "space heater",
+ "space shuttle", "spatula", "motorboat", "spider web", "spindle", "sports car", "spotlight",
+ "stage", "steam locomotive", "through arch bridge", "steel drum", "stethoscope", "scarf",
+ "stone wall", "stopwatch", "stove", "strainer", "tram", "stretcher", "couch", "stupa",
+ "submarine", "suit", "sundial", "sunglasses", "sunglasses", "sunscreen", "suspension bridge",
+ "mop", "sweatshirt", "swim trunks / shorts", "swing", "electrical switch", "syringe",
+ "table lamp", "tank", "tape player", "teapot", "teddy bear", "television", "tennis ball",
+ "thatched roof", "front curtain", "thimble", "threshing machine", "throne", "tile roof",
+ "toaster", "tobacco shop", "toilet seat", "torch", "totem pole", "tow truck", "toy store",
+ "tractor", "semi-trailer truck", "tray", "trench coat", "tricycle", "trimaran", "tripod",
+ "triumphal arch", "trolleybus", "trombone", "hot tub", "turnstile", "typewriter keyboard",
+ "umbrella", "unicycle", "upright piano", "vacuum cleaner", "vase", "vaulted or arched ceiling",
+ "velvet fabric", "vending machine", "vestment", "viaduct", "violin", "volleyball",
+ "waffle iron", "wall clock", "wallet", "wardrobe", "military aircraft", "sink",
+ "washing machine", "water bottle", "water jug", "water tower", "whiskey jug", "whistle",
+ "hair wig", "window screen", "window shade", "Windsor tie", "wine bottle", "airplane wing",
+ "wok", "wooden spoon", "wool", "split-rail fence", "shipwreck", "sailboat", "yurt", "website",
+ "comic book", "crossword", "traffic or street sign", "traffic light", "dust jacket", "menu",
+ "plate", "guacamole", "consomme", "hot pot", "trifle", "ice cream", "popsicle", "baguette",
+ "bagel", "pretzel", "cheeseburger", "hot dog", "mashed potatoes", "cabbage", "broccoli",
+ "cauliflower", "zucchini", "spaghetti squash", "acorn squash", "butternut squash", "cucumber",
+ "artichoke", "bell pepper", "cardoon", "mushroom", "Granny Smith apple", "strawberry", "orange",
+ "lemon", "fig", "pineapple", "banana", "jackfruit", "cherimoya (custard apple)", "pomegranate",
+ "hay", "carbonara", "chocolate syrup", "dough", "meatloaf", "pizza", "pot pie", "burrito",
+ "red wine", "espresso", "tea cup", "eggnog", "mountain", "bubble", "cliff", "coral reef",
+ "geyser", "lakeshore", "promontory", "sandbar", "beach", "valley", "volcano", "baseball player",
+ "bridegroom", "scuba diver", "rapeseed", "daisy", "yellow lady's slipper", "corn", "acorn",
+ "rose hip", "horse chestnut seed", "coral fungus", "agaric", "gyromitra", "stinkhorn mushroom",
+ "earth star fungus", "hen of the woods mushroom", "bolete", "corn cob", "toilet paper"
+)
+
diff --git a/src/open_clip_train/__init__.py b/src/open_clip_train/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/src/open_clip_train/data.py b/src/open_clip_train/data.py
new file mode 100644
index 0000000000000000000000000000000000000000..234d7cfc804dc689574adb44336d797c47c43d8d
--- /dev/null
+++ b/src/open_clip_train/data.py
@@ -0,0 +1,626 @@
+import ast
+import json
+import logging
+import math
+import os
+import random
+import sys
+import braceexpand
+from dataclasses import dataclass
+from multiprocessing import Value
+
+import numpy as np
+import pandas as pd
+import torch
+import torchvision.datasets as datasets
+import webdataset as wds
+from PIL import Image
+from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler, IterableDataset, get_worker_info
+from torch.utils.data.distributed import DistributedSampler
+from webdataset.filters import _shuffle
+from webdataset.tariterators import base_plus_ext, url_opener, tar_file_expander, valid_sample
+
+try:
+ import horovod.torch as hvd
+except ImportError:
+ hvd = None
+
+
+### jsonl dataset
+class JsonlDataset(Dataset):
+ def __init__(self, input_filename, transforms, tokenizer=None):
+ logging.debug(f'Loading jsonl data from {input_filename}.')
+ with open(input_filename, 'r') as f:
+ self.samples = [json.loads(line) for line in f]
+
+ self.transforms = transforms
+ self.tokenize = tokenizer
+ logging.debug(f'Loaded {len(self.samples)} samples.')
+
+ def __len__(self):
+ return len(self.samples)
+
+ def __getitem__(self, idx):
+ sample = self.samples[idx]
+ full_img = Image.open(sample['image']).convert("L") # shape: [H, W] = [512, 1024]
+ full_tensor = torch.from_numpy(np.array(full_img)).unsqueeze(0).float() / 255.
+ left_tensor = full_tensor[:, :, :512] # shape: [1, 512, 512]
+ right_tensor = full_tensor[:, :, 512:] # shape: [1, 512, 512]
+ image = torch.cat([left_tensor, right_tensor], dim=0)
+ text = self.tokenize([sample['text']])[0]
+
+ concentration = torch.tensor(sample["Concentration"], dtype=torch.float32)
+ time = torch.tensor(sample["Time"], dtype=torch.float32)
+ compound_embedding = torch.tensor(sample["compound_embedding"], dtype=torch.float32)
+
+ return image, text, concentration, time, compound_embedding
+
+
+def get_jsonl_dataset(args, preprocess_fn, is_train, epoch=0, tokenizer=None):
+ input_filename = args.train_data if is_train else args.val_data
+ assert input_filename
+ dataset = JsonlDataset(
+ input_filename,
+ preprocess_fn,
+ tokenizer=tokenizer
+ )
+ num_samples = len(dataset)
+ sampler = DistributedSampler(dataset) if args.distributed and is_train else None
+ shuffle = is_train and sampler is None
+
+ dataloader = DataLoader(
+ dataset,
+ batch_size=args.batch_size,
+ shuffle=shuffle,
+ num_workers=args.workers,
+ pin_memory=True,
+ sampler=sampler,
+ drop_last=is_train,
+ )
+ dataloader.num_samples = num_samples
+ dataloader.num_batches = len(dataloader)
+
+ return DataInfo(dataloader, sampler)
+
+###################################################
+
+class CsvDataset(Dataset):
+ def __init__(self, input_filename, transforms, img_key, caption_key, sep="\t", tokenizer=None):
+ logging.debug(f'Loading csv data from {input_filename}.')
+ df = pd.read_csv(input_filename, sep=sep)
+
+ self.images = df[img_key].tolist()
+ self.captions = df[caption_key].tolist()
+ self.transforms = transforms
+ logging.debug('Done loading data.')
+
+ self.tokenize = tokenizer
+
+ def __len__(self):
+ return len(self.captions)
+
+ def __getitem__(self, idx):
+ images = self.transforms(Image.open(str(self.images[idx])))
+ texts = self.tokenize([str(self.captions[idx])])[0]
+ return images, texts
+
+
+class SharedEpoch:
+ def __init__(self, epoch: int = 0):
+ self.shared_epoch = Value('i', epoch)
+
+ def set_value(self, epoch):
+ self.shared_epoch.value = epoch
+
+ def get_value(self):
+ return self.shared_epoch.value
+
+
+@dataclass
+class DataInfo:
+ dataloader: DataLoader
+ sampler: DistributedSampler = None
+ shared_epoch: SharedEpoch = None
+
+ def set_epoch(self, epoch):
+ if self.shared_epoch is not None:
+ self.shared_epoch.set_value(epoch)
+ if self.sampler is not None and isinstance(self.sampler, DistributedSampler):
+ self.sampler.set_epoch(epoch)
+
+
+def expand_urls(urls, weights=None):
+ if weights is None:
+ expanded_urls = wds.shardlists.expand_urls(urls)
+ return expanded_urls, None
+ if isinstance(urls, str):
+ urllist = urls.split("::")
+ weights = weights.split('::')
+ assert len(weights) == len(urllist),\
+ f"Expected the number of data components ({len(urllist)}) and weights({len(weights)}) to match."
+ weights = [float(weight) for weight in weights]
+ all_urls, all_weights = [], []
+ for url, weight in zip(urllist, weights):
+ expanded_url = list(braceexpand.braceexpand(url))
+ expanded_weights = [weight for _ in expanded_url]
+ all_urls.extend(expanded_url)
+ all_weights.extend(expanded_weights)
+ return all_urls, all_weights
+ else:
+ all_urls = list(urls)
+ return all_urls, weights
+
+
+def get_dataset_size(shards):
+ shards_list, _ = expand_urls(shards)
+ dir_path = os.path.dirname(shards_list[0])
+ sizes_filename = os.path.join(dir_path, 'sizes.json')
+ len_filename = os.path.join(dir_path, '__len__')
+ if os.path.exists(sizes_filename):
+ sizes = json.load(open(sizes_filename, 'r'))
+ total_size = sum([int(sizes[os.path.basename(shard)]) for shard in shards_list])
+ elif os.path.exists(len_filename):
+ # FIXME this used to be eval(open(...)) but that seemed rather unsafe
+ total_size = ast.literal_eval(open(len_filename, 'r').read())
+ else:
+ total_size = None # num samples undefined
+ # some common dataset sizes (at time of authors last download)
+ # CC3M (train): 2905954
+ # CC12M: 10968539
+ # LAION-400M: 407332084
+ # LAION-2B (english): 2170337258
+ num_shards = len(shards_list)
+ return total_size, num_shards
+
+
+def get_imagenet(args, preprocess_fns, split):
+ assert split in ["train", "val", "v2"]
+ is_train = split == "train"
+ preprocess_train, preprocess_val = preprocess_fns
+
+ if split == "v2":
+ from imagenetv2_pytorch import ImageNetV2Dataset
+ dataset = ImageNetV2Dataset(location=args.imagenet_v2, transform=preprocess_val)
+ else:
+ if is_train:
+ data_path = args.imagenet_train
+ preprocess_fn = preprocess_train
+ else:
+ data_path = args.imagenet_val
+ preprocess_fn = preprocess_val
+ assert data_path
+
+ dataset = datasets.ImageFolder(data_path, transform=preprocess_fn)
+
+ if is_train:
+ idxs = np.zeros(len(dataset.targets))
+ target_array = np.array(dataset.targets)
+ k = 50
+ for c in range(1000):
+ m = target_array == c
+ n = len(idxs[m])
+ arr = np.zeros(n)
+ arr[:k] = 1
+ np.random.shuffle(arr)
+ idxs[m] = arr
+
+ idxs = idxs.astype('int')
+ sampler = SubsetRandomSampler(np.where(idxs)[0])
+ else:
+ sampler = None
+
+ dataloader = torch.utils.data.DataLoader(
+ dataset,
+ batch_size=args.batch_size,
+ num_workers=args.workers,
+ sampler=sampler,
+ )
+
+ return DataInfo(dataloader=dataloader, sampler=sampler)
+
+
+def count_samples(dataloader):
+ os.environ["WDS_EPOCH"] = "0"
+ n_elements, n_batches = 0, 0
+ for images, texts in dataloader:
+ n_batches += 1
+ n_elements += len(images)
+ assert len(images) == len(texts)
+ return n_elements, n_batches
+
+
+def filter_no_caption_or_no_image(sample):
+ has_caption = ('txt' in sample)
+ has_image = ('png' in sample or 'jpg' in sample or 'jpeg' in sample or 'webp' in sample)
+ return has_caption and has_image
+
+
+def log_and_continue(exn):
+ """Call in an exception handler to ignore any exception, issue a warning, and continue."""
+ logging.warning(f'Handling webdataset error ({repr(exn)}). Ignoring.')
+ return True
+
+
+def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
+ """Return function over iterator that groups key, value pairs into samples.
+
+ :param keys: function that splits the key into key and extension (base_plus_ext)
+ :param lcase: convert suffixes to lower case (Default value = True)
+ """
+ current_sample = None
+ for filesample in data:
+ assert isinstance(filesample, dict)
+ fname, value = filesample["fname"], filesample["data"]
+ prefix, suffix = keys(fname)
+ if prefix is None:
+ continue
+ if lcase:
+ suffix = suffix.lower()
+ # FIXME webdataset version throws if suffix in current_sample, but we have a potential for
+ # this happening in the current LAION400m dataset if a tar ends with same prefix as the next
+ # begins, rare, but can happen since prefix aren't unique across tar files in that dataset
+ if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
+ if valid_sample(current_sample):
+ yield current_sample
+ current_sample = dict(__key__=prefix, __url__=filesample["__url__"])
+ if suffixes is None or suffix in suffixes:
+ current_sample[suffix] = value
+ if valid_sample(current_sample):
+ yield current_sample
+
+
+def tarfile_to_samples_nothrow(src, handler=log_and_continue):
+ # NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
+ streams = url_opener(src, handler=handler)
+ files = tar_file_expander(streams, handler=handler)
+ samples = group_by_keys_nothrow(files, handler=handler)
+ return samples
+
+
+def pytorch_worker_seed(increment=0):
+ """get dataloader worker seed from pytorch"""
+ worker_info = get_worker_info()
+ if worker_info is not None:
+ # favour using the seed already created for pytorch dataloader workers if it exists
+ seed = worker_info.seed
+ if increment:
+ # space out seed increments so they can't overlap across workers in different iterations
+ seed += increment * max(1, worker_info.num_workers)
+ return seed
+ # fallback to wds rank based seed
+ return wds.utils.pytorch_worker_seed()
+
+
+_SHARD_SHUFFLE_SIZE = 2000
+_SHARD_SHUFFLE_INITIAL = 500
+_SAMPLE_SHUFFLE_SIZE = 5000
+_SAMPLE_SHUFFLE_INITIAL = 1000
+
+
+class detshuffle2(wds.PipelineStage):
+ def __init__(
+ self,
+ bufsize=1000,
+ initial=100,
+ seed=0,
+ epoch=-1,
+ ):
+ self.bufsize = bufsize
+ self.initial = initial
+ self.seed = seed
+ self.epoch = epoch
+
+ def run(self, src):
+ if isinstance(self.epoch, SharedEpoch):
+ epoch = self.epoch.get_value()
+ else:
+ # NOTE: this is epoch tracking is problematic in a multiprocess (dataloader workers or train)
+ # situation as different workers may wrap at different times (or not at all).
+ self.epoch += 1
+ epoch = self.epoch
+ rng = random.Random()
+ if self.seed < 0:
+ # If seed is negative, we use the worker's seed, this will be different across all nodes/workers
+ seed = pytorch_worker_seed(epoch)
+ else:
+ # This seed to be deterministic AND the same across all nodes/workers in each epoch
+ seed = self.seed + epoch
+ rng.seed(seed)
+ return _shuffle(src, self.bufsize, self.initial, rng)
+
+
+class ResampledShards2(IterableDataset):
+ """An iterable dataset yielding a list of urls."""
+
+ def __init__(
+ self,
+ urls,
+ weights=None,
+ nshards=sys.maxsize,
+ worker_seed=None,
+ deterministic=False,
+ epoch=-1,
+ ):
+ """Sample shards from the shard list with replacement.
+
+ :param urls: a list of URLs as a Python list or brace notation string
+ """
+ super().__init__()
+ urls, weights = expand_urls(urls, weights)
+ self.urls = urls
+ self.weights = weights
+ if self.weights is not None:
+ assert len(self.urls) == len(self.weights),\
+ f"Number of urls {len(self.urls)} and weights {len(self.weights)} should match."
+ assert isinstance(self.urls[0], str)
+ self.nshards = nshards
+ self.rng = random.Random()
+ self.worker_seed = worker_seed
+ self.deterministic = deterministic
+ self.epoch = epoch
+
+ def __iter__(self):
+ """Return an iterator over the shards."""
+ if isinstance(self.epoch, SharedEpoch):
+ epoch = self.epoch.get_value()
+ else:
+ # NOTE: this is epoch tracking is problematic in a multiprocess (dataloader workers or train)
+ # situation as different workers may wrap at different times (or not at all).
+ self.epoch += 1
+ epoch = self.epoch
+ if self.deterministic:
+ # reset seed w/ epoch if deterministic
+ if self.worker_seed is None:
+ # pytorch worker seed should be deterministic due to being init by arg.seed + rank + worker id
+ seed = pytorch_worker_seed(epoch)
+ else:
+ seed = self.worker_seed() + epoch
+ self.rng.seed(seed)
+ for _ in range(self.nshards):
+ if self.weights is None:
+ yield dict(url=self.rng.choice(self.urls))
+ else:
+ yield dict(url=self.rng.choices(self.urls, weights=self.weights, k=1)[0])
+
+
+def get_wds_dataset(args, preprocess_img, is_train, epoch=0, floor=False, tokenizer=None):
+ input_shards = args.train_data if is_train else args.val_data
+ assert input_shards is not None
+ resampled = getattr(args, 'dataset_resampled', False) and is_train
+
+ num_shards = None
+ if is_train:
+ if args.train_num_samples is not None:
+ num_samples = args.train_num_samples
+ else:
+ num_samples, num_shards = get_dataset_size(input_shards)
+ if not num_samples:
+ raise RuntimeError(
+ 'Currently, the number of dataset samples must be specified for the training dataset. '
+ 'Please specify it via `--train-num-samples` if no dataset length info is present.')
+ else:
+ # Eval will just exhaust the iterator if the size is not specified.
+ num_samples = args.val_num_samples or 0
+
+ shared_epoch = SharedEpoch(epoch=epoch) # create a shared epoch store to sync epoch to dataloader worker proc
+
+ if is_train and args.train_data_upsampling_factors is not None:
+ assert resampled, "--train_data_upsampling_factors is only supported when sampling with replacement (with --dataset-resampled)."
+
+ if resampled:
+ pipeline = [ResampledShards2(
+ input_shards,
+ weights=args.train_data_upsampling_factors,
+ deterministic=True,
+ epoch=shared_epoch,
+ )]
+ else:
+ pipeline = [wds.SimpleShardList(input_shards)]
+
+ # at this point we have an iterator over all the shards
+ if is_train:
+ if not resampled:
+ pipeline.extend([
+ detshuffle2(
+ bufsize=_SHARD_SHUFFLE_SIZE,
+ initial=_SHARD_SHUFFLE_INITIAL,
+ seed=args.seed,
+ epoch=shared_epoch,
+ ),
+ wds.split_by_node,
+ wds.split_by_worker,
+ ])
+ pipeline.extend([
+ # at this point, we have an iterator over the shards assigned to each worker at each node
+ tarfile_to_samples_nothrow, # wds.tarfile_to_samples(handler=log_and_continue),
+ wds.shuffle(
+ bufsize=_SAMPLE_SHUFFLE_SIZE,
+ initial=_SAMPLE_SHUFFLE_INITIAL,
+ ),
+ ])
+ else:
+ pipeline.extend([
+ wds.split_by_worker,
+ # at this point, we have an iterator over the shards assigned to each worker
+ wds.tarfile_to_samples(handler=log_and_continue),
+ ])
+ pipeline.extend([
+ wds.select(filter_no_caption_or_no_image),
+ wds.decode("pilrgb", handler=log_and_continue),
+ wds.rename(image="jpg;png;jpeg;webp", text="txt"),
+ wds.map_dict(image=preprocess_img, text=lambda text: tokenizer(text)[0]),
+ wds.to_tuple("image", "text"),
+ wds.batched(args.batch_size, partial=not is_train)
+ ])
+
+ dataset = wds.DataPipeline(*pipeline)
+
+ if is_train:
+ if not resampled:
+ num_shards = num_shards or len(expand_urls(input_shards)[0])
+ assert num_shards >= args.workers * args.world_size, 'number of shards must be >= total workers'
+ # roll over and repeat a few samples to get same number of full batches on each node
+ round_fn = math.floor if floor else math.ceil
+ global_batch_size = args.batch_size * args.world_size
+ num_batches = round_fn(num_samples / global_batch_size)
+ num_workers = max(1, args.workers)
+ num_worker_batches = round_fn(num_batches / num_workers) # per dataloader worker
+ num_batches = num_worker_batches * num_workers
+ num_samples = num_batches * global_batch_size
+ dataset = dataset.with_epoch(num_worker_batches) # each worker is iterating over this
+ else:
+ # last batches are partial, eval is done on single (master) node
+ num_batches = math.ceil(num_samples / args.batch_size)
+
+ dataloader = wds.WebLoader(
+ dataset,
+ batch_size=None,
+ shuffle=False,
+ num_workers=args.workers,
+ persistent_workers=args.workers > 0,
+ )
+
+ # FIXME not clear which approach is better, with_epoch before vs after dataloader?
+ # hoping to resolve via https://github.com/webdataset/webdataset/issues/169
+ # if is_train:
+ # # roll over and repeat a few samples to get same number of full batches on each node
+ # global_batch_size = args.batch_size * args.world_size
+ # num_batches = math.ceil(num_samples / global_batch_size)
+ # num_workers = max(1, args.workers)
+ # num_batches = math.ceil(num_batches / num_workers) * num_workers
+ # num_samples = num_batches * global_batch_size
+ # dataloader = dataloader.with_epoch(num_batches)
+ # else:
+ # # last batches are partial, eval is done on single (master) node
+ # num_batches = math.ceil(num_samples / args.batch_size)
+
+ # add meta-data to dataloader instance for convenience
+ dataloader.num_batches = num_batches
+ dataloader.num_samples = num_samples
+
+ return DataInfo(dataloader=dataloader, shared_epoch=shared_epoch)
+
+
+def get_csv_dataset(args, preprocess_fn, is_train, epoch=0, tokenizer=None):
+ input_filename = args.train_data if is_train else args.val_data
+ assert input_filename
+ dataset = CsvDataset(
+ input_filename,
+ preprocess_fn,
+ img_key=args.csv_img_key,
+ caption_key=args.csv_caption_key,
+ sep=args.csv_separator,
+ tokenizer=tokenizer
+ )
+ num_samples = len(dataset)
+ sampler = DistributedSampler(dataset) if args.distributed and is_train else None
+ shuffle = is_train and sampler is None
+
+ dataloader = DataLoader(
+ dataset,
+ batch_size=args.batch_size,
+ shuffle=shuffle,
+ num_workers=args.workers,
+ pin_memory=True,
+ sampler=sampler,
+ drop_last=is_train,
+ )
+ dataloader.num_samples = num_samples
+ dataloader.num_batches = len(dataloader)
+
+ return DataInfo(dataloader, sampler)
+
+
+class SyntheticDataset(Dataset):
+
+ def __init__(
+ self,
+ transform=None,
+ image_size=(224, 224),
+ caption="Dummy caption",
+ dataset_size=100,
+ tokenizer=None,
+ ):
+ self.transform = transform
+ self.image_size = image_size
+ self.caption = caption
+ self.image = Image.new('RGB', image_size)
+ self.dataset_size = dataset_size
+
+ self.preprocess_txt = lambda text: tokenizer(text)[0]
+
+ def __len__(self):
+ return self.dataset_size
+
+ def __getitem__(self, idx):
+ if self.transform is not None:
+ image = self.transform(self.image)
+ return image, self.preprocess_txt(self.caption)
+
+
+def get_synthetic_dataset(args, preprocess_fn, is_train, epoch=0, tokenizer=None):
+ image_size = preprocess_fn.transforms[0].size
+ dataset = SyntheticDataset(
+ transform=preprocess_fn, image_size=image_size, dataset_size=args.train_num_samples, tokenizer=tokenizer)
+ num_samples = len(dataset)
+ sampler = DistributedSampler(dataset) if args.distributed and is_train else None
+ shuffle = is_train and sampler is None
+
+ dataloader = DataLoader(
+ dataset,
+ batch_size=args.batch_size,
+ shuffle=shuffle,
+ num_workers=args.workers,
+ pin_memory=True,
+ sampler=sampler,
+ drop_last=is_train,
+ )
+ dataloader.num_samples = num_samples
+ dataloader.num_batches = len(dataloader)
+
+ return DataInfo(dataloader, sampler)
+
+
+def get_dataset_fn(data_path, dataset_type):
+ if dataset_type == "webdataset":
+ return get_wds_dataset
+ elif dataset_type == "csv":
+ return get_csv_dataset
+ elif dataset_type == "synthetic":
+ return get_synthetic_dataset
+ elif dataset_type == "jsonl":
+ return get_jsonl_dataset
+ elif dataset_type == "auto":
+ ext = data_path.split('.')[-1]
+ if ext in ['csv', 'tsv']:
+ return get_csv_dataset
+ elif ext in ['tar']:
+ return get_wds_dataset
+ elif ext in ['jsonl']:
+ return get_jsonl_dataset
+ else:
+ raise ValueError(
+ f"Tried to figure out dataset type, but failed for extension {ext}.")
+ else:
+ raise ValueError(f"Unsupported dataset type: {dataset_type}")
+
+
+def get_data(args, preprocess_fns, epoch=0, tokenizer=None):
+ preprocess_train, preprocess_val = preprocess_fns
+ data = {}
+
+ if args.train_data or args.dataset_type == "synthetic":
+ data["train"] = get_dataset_fn(args.train_data, args.dataset_type)(
+ args, preprocess_train, is_train=True, epoch=epoch, tokenizer=tokenizer)
+
+ if args.val_data:
+ data["val"] = get_dataset_fn(args.val_data, args.dataset_type)(
+ args, preprocess_val, is_train=False, tokenizer=tokenizer)
+
+ if args.imagenet_val is not None:
+ data["imagenet-val"] = get_imagenet(args, preprocess_fns, "val")
+
+ if args.imagenet_v2 is not None:
+ data["imagenet-v2"] = get_imagenet(args, preprocess_fns, "v2")
+
+ return data
diff --git a/src/open_clip_train/distributed.py b/src/open_clip_train/distributed.py
new file mode 100644
index 0000000000000000000000000000000000000000..2fad34575f0965f1082752d9df66ceeb2f109344
--- /dev/null
+++ b/src/open_clip_train/distributed.py
@@ -0,0 +1,218 @@
+import os
+import warnings
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+
+try:
+ import horovod.torch as hvd
+except ImportError:
+ hvd = None
+
+
+def is_global_master(args):
+ return args.rank == 0
+
+
+def is_local_master(args):
+ return args.local_rank == 0
+
+
+def is_master(args, local=False):
+ return is_local_master(args) if local else is_global_master(args)
+
+
+def is_device_available(device):
+ device_type = torch.device(device).type
+ is_avail = False
+ is_known = False
+ if device_type == 'cuda':
+ is_avail = torch.cuda.is_available()
+ is_known = True
+ elif device_type == 'npu':
+ # NOTE autoload device extension needed for this not to error out on this check
+ is_avail = torch.npu.is_available()
+ is_known = True
+ elif device_type == 'mps':
+ is_avail = torch.backends.mps.is_available()
+ is_known = True
+ elif device_type == 'cpu':
+ is_avail = True
+ is_known = True
+
+ return is_avail, is_known
+
+
+def set_device(device):
+ if device.startswith('cuda:'):
+ torch.cuda.set_device(device)
+ elif device.startswith('npu:'):
+ torch.npu.set_device(device)
+
+
+def is_using_horovod():
+ # NOTE w/ horovod run, OMPI vars should be set, but w/ SLURM PMI vars will be set
+ # Differentiating between horovod and DDP use via SLURM may not be possible, so horovod arg still required...
+ ompi_vars = ["OMPI_COMM_WORLD_RANK", "OMPI_COMM_WORLD_SIZE"]
+ pmi_vars = ["PMI_RANK", "PMI_SIZE"]
+ if all([var in os.environ for var in ompi_vars]) or all([var in os.environ for var in pmi_vars]):
+ return True
+ else:
+ return False
+
+
+def is_using_distributed():
+ if 'WORLD_SIZE' in os.environ:
+ return int(os.environ['WORLD_SIZE']) > 1
+ if 'SLURM_NTASKS' in os.environ:
+ return int(os.environ['SLURM_NTASKS']) > 1
+ return False
+
+
+def world_info_from_env():
+ local_rank = 0
+ for v in ('LOCAL_RANK', 'MPI_LOCALRANKID', 'SLURM_LOCALID', 'OMPI_COMM_WORLD_LOCAL_RANK'):
+ if v in os.environ:
+ local_rank = int(os.environ[v])
+ break
+ global_rank = 0
+ for v in ('RANK', 'PMI_RANK', 'SLURM_PROCID', 'OMPI_COMM_WORLD_RANK'):
+ if v in os.environ:
+ global_rank = int(os.environ[v])
+ break
+ world_size = 1
+ for v in ('WORLD_SIZE', 'PMI_SIZE', 'SLURM_NTASKS', 'OMPI_COMM_WORLD_SIZE'):
+ if v in os.environ:
+ world_size = int(os.environ[v])
+ break
+
+ return local_rank, global_rank, world_size
+
+
+def init_distributed_device(args):
+ # Distributed training = training on more than one GPU.
+ # Works in both single and multi-node scenarios.
+ args.distributed = False
+ args.world_size = 1
+ args.rank = 0 # global rank
+ args.local_rank = 0
+ result = init_distributed_device_so(
+ device=getattr(args, 'device', 'cuda'),
+ dist_backend=getattr(args, 'dist_backend', None),
+ dist_url=getattr(args, 'dist_url', None),
+ horovod=getattr(args, 'horovod', False),
+ no_set_device_rank=getattr(args, 'no_set_device_rank', False),
+ )
+ args.device = result['device']
+ args.world_size = result['world_size']
+ args.rank = result['global_rank']
+ args.local_rank = result['local_rank']
+ args.distributed = result['distributed']
+ device = torch.device(args.device)
+ return device
+
+
+def init_distributed_device_so(
+ device: str = 'cuda',
+ dist_backend: Optional[str] = None,
+ dist_url: Optional[str] = None,
+ horovod: bool = False,
+ no_set_device_rank: bool = False,
+):
+ # Distributed training = training on more than one GPU.
+ # Works in both single and multi-node scenarios.
+ distributed = False
+ world_size = 1
+ global_rank = 0
+ local_rank = 0
+ device_type, *device_idx = device.split(':', maxsplit=1)
+ is_avail, is_known = is_device_available(device_type)
+ if not is_known:
+ warnings.warn(f"Device {device} was not known and checked for availability, trying anyways.")
+ elif not is_avail:
+ warnings.warn(f"Device {device} was not available, falling back to CPU.")
+ device_type = device = 'cpu'
+
+ if horovod:
+ import horovod.torch as hvd
+ assert hvd is not None, "Horovod is not installed"
+ hvd.init()
+ local_rank = int(hvd.local_rank())
+ global_rank = hvd.rank()
+ world_size = hvd.size()
+ distributed = True
+ elif is_using_distributed():
+ if dist_backend is None:
+ dist_backends = {
+ "cuda": "nccl",
+ "hpu": "hccl",
+ "npu": "hccl",
+ "xpu": "ccl",
+ }
+ dist_backend = dist_backends.get(device_type, 'gloo')
+
+ dist_url = dist_url or 'env://'
+
+ if 'SLURM_PROCID' in os.environ:
+ # DDP via SLURM
+ local_rank, global_rank, world_size = world_info_from_env()
+ # SLURM var -> torch.distributed vars in case needed
+ os.environ['LOCAL_RANK'] = str(local_rank)
+ os.environ['RANK'] = str(global_rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ torch.distributed.init_process_group(
+ backend=dist_backend,
+ init_method=dist_url,
+ world_size=world_size,
+ rank=global_rank,
+ )
+ else:
+ # DDP via torchrun, torch.distributed.launch
+ local_rank, _, _ = world_info_from_env()
+ torch.distributed.init_process_group(
+ backend=dist_backend,
+ init_method=dist_url,
+ )
+ world_size = torch.distributed.get_world_size()
+ global_rank = torch.distributed.get_rank()
+ distributed = True
+
+ if distributed and not no_set_device_rank and device_type not in ('cpu', 'mps'):
+ # Ignore manually specified device index in distributed mode and
+ # override with resolved local rank, fewer headaches in most setups.
+ if device_idx:
+ warnings.warn(f'device index {device_idx[0]} removed from specified ({device}).')
+ device = f'{device_type}:{local_rank}'
+ set_device(device)
+
+ return dict(
+ device=device,
+ global_rank=global_rank,
+ local_rank=local_rank,
+ world_size=world_size,
+ distributed=distributed,
+ )
+
+
+def broadcast_object(args, obj, src=0):
+ # broadcast a pickle-able python object from rank-0 to all ranks
+ if args.horovod:
+ return hvd.broadcast_object(obj, root_rank=src)
+ else:
+ if args.rank == src:
+ objects = [obj]
+ else:
+ objects = [None]
+ dist.broadcast_object_list(objects, src=src)
+ return objects[0]
+
+
+def all_gather_object(args, obj, dst=0):
+ # gather a pickle-able python object across all ranks
+ if args.horovod:
+ return hvd.allgather_object(obj)
+ else:
+ objects = [None for _ in range(args.world_size)]
+ dist.all_gather_object(objects, obj)
+ return objects
diff --git a/src/open_clip_train/file_utils.py b/src/open_clip_train/file_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..395cf7df0acc164c6851f17834d793f5852d4605
--- /dev/null
+++ b/src/open_clip_train/file_utils.py
@@ -0,0 +1,83 @@
+import logging
+import os
+import multiprocessing
+import subprocess
+import time
+import fsspec
+import torch
+from tqdm import tqdm
+
+def remote_sync_s3(local_dir, remote_dir):
+ # skip epoch_latest which can change during sync.
+ result = subprocess.run(["aws", "s3", "sync", local_dir, remote_dir, '--exclude', '*epoch_latest.pt'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ if result.returncode != 0:
+ logging.error(f"Error: Failed to sync with S3 bucket {result.stderr.decode('utf-8')}")
+ return False
+
+ logging.info(f"Successfully synced with S3 bucket")
+ return True
+
+def remote_sync_fsspec(local_dir, remote_dir):
+ # FIXME currently this is slow and not recommended. Look into speeding up.
+ a = fsspec.get_mapper(local_dir)
+ b = fsspec.get_mapper(remote_dir)
+
+ for k in a:
+ # skip epoch_latest which can change during sync.
+ if 'epoch_latest.pt' in k:
+ continue
+
+ logging.info(f'Attempting to sync {k}')
+ if k in b and len(a[k]) == len(b[k]):
+ logging.debug(f'Skipping remote sync for {k}.')
+ continue
+
+ try:
+ logging.info(f'Successful sync for {k}.')
+ b[k] = a[k]
+ except Exception as e:
+ logging.info(f'Error during remote sync for {k}: {e}')
+ return False
+
+ return True
+
+def remote_sync(local_dir, remote_dir, protocol):
+ logging.info('Starting remote sync.')
+ if protocol == 's3':
+ return remote_sync_s3(local_dir, remote_dir)
+ elif protocol == 'fsspec':
+ return remote_sync_fsspec(local_dir, remote_dir)
+ else:
+ logging.error('Remote protocol not known')
+ return False
+
+def keep_running_remote_sync(sync_every, local_dir, remote_dir, protocol):
+ while True:
+ time.sleep(sync_every)
+ remote_sync(local_dir, remote_dir, protocol)
+
+def start_sync_process(sync_every, local_dir, remote_dir, protocol):
+ p = multiprocessing.Process(target=keep_running_remote_sync, args=(sync_every, local_dir, remote_dir, protocol))
+ return p
+
+# Note: we are not currently using this save function.
+def pt_save(pt_obj, file_path):
+ of = fsspec.open(file_path, "wb")
+ with of as f:
+ torch.save(pt_obj, file_path)
+
+def pt_load(file_path, map_location=None):
+ if file_path.startswith('s3'):
+ logging.info('Loading remote checkpoint, which may take a bit.')
+ of = fsspec.open(file_path, "rb")
+ with of as f:
+ out = torch.load(f, map_location=map_location)
+ return out
+
+def check_exists(file_path):
+ try:
+ with fsspec.open(file_path):
+ pass
+ except FileNotFoundError:
+ return False
+ return True
diff --git a/src/open_clip_train/logger.py b/src/open_clip_train/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d9abed92568d459cbc8d6094ae3901935d89621
--- /dev/null
+++ b/src/open_clip_train/logger.py
@@ -0,0 +1,26 @@
+import logging
+
+
+def setup_logging(log_file, level, include_host=False):
+ if include_host:
+ import socket
+ hostname = socket.gethostname()
+ formatter = logging.Formatter(
+ f'%(asctime)s | {hostname} | %(levelname)s | %(message)s', datefmt='%Y-%m-%d,%H:%M:%S')
+ else:
+ formatter = logging.Formatter('%(asctime)s | %(levelname)s | %(message)s', datefmt='%Y-%m-%d,%H:%M:%S')
+
+ logging.root.setLevel(level)
+ loggers = [logging.getLogger(name) for name in logging.root.manager.loggerDict]
+ for logger in loggers:
+ logger.setLevel(level)
+
+ stream_handler = logging.StreamHandler()
+ stream_handler.setFormatter(formatter)
+ logging.root.addHandler(stream_handler)
+
+ if log_file:
+ file_handler = logging.FileHandler(filename=log_file)
+ file_handler.setFormatter(formatter)
+ logging.root.addHandler(file_handler)
+
diff --git a/src/open_clip_train/main.py b/src/open_clip_train/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..d99e616d59a2b3b275ae536510505928c401f2e2
--- /dev/null
+++ b/src/open_clip_train/main.py
@@ -0,0 +1,558 @@
+import copy
+import glob
+import logging
+import os
+import re
+import subprocess
+import sys
+import random
+from datetime import datetime
+from functools import partial
+
+import numpy as np
+import torch
+from torch import optim
+
+try:
+ import wandb
+except ImportError:
+ wandb = None
+
+try:
+ import torch.utils.tensorboard as tensorboard
+except ImportError:
+ tensorboard = None
+
+try:
+ import horovod.torch as hvd
+except ImportError:
+ hvd = None
+
+from open_clip import create_model_and_transforms, trace_model, get_tokenizer, create_loss
+from open_clip_train.data import get_data
+from open_clip_train.distributed import is_master, init_distributed_device, broadcast_object
+from open_clip_train.logger import setup_logging
+from open_clip_train.params import parse_args
+from open_clip_train.scheduler import cosine_lr, const_lr, const_lr_cooldown
+from open_clip_train.train import train_one_epoch, evaluate
+from open_clip_train.file_utils import pt_load, check_exists, start_sync_process, remote_sync
+
+
+LATEST_CHECKPOINT_NAME = "epoch_latest.pt"
+
+
+def random_seed(seed=42, rank=0):
+ torch.manual_seed(seed + rank)
+ np.random.seed(seed + rank)
+ random.seed(seed + rank)
+
+
+def natural_key(string_):
+ """See http://www.codinghorror.com/blog/archives/001018.html"""
+ return [int(s) if s.isdigit() else s for s in re.split(r'(\d+)', string_.lower())]
+
+
+def get_latest_checkpoint(path: str, remote : bool):
+ # as writen, this glob recurses, so can pick up checkpoints across multiple sub-folders
+ if remote:
+ result = subprocess.run(["aws", "s3", "ls", path + "/"], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ print(result)
+ if result.returncode == 1:
+ return None
+ checkpoints = [os.path.join(path, x.split(' ')[-1]) for x in result.stdout.decode().split('\n')[:-1]]
+ else:
+ checkpoints = glob.glob(path + '**/*.pt', recursive=True)
+ if checkpoints:
+ checkpoints = sorted(checkpoints, key=natural_key)
+ return checkpoints[-1]
+ return None
+
+
+def main(args):
+ args = parse_args(args)
+
+ if torch.cuda.is_available():
+ # This enables tf32 on Ampere GPUs which is only 8% slower than
+ # float16 and almost as accurate as float32
+ # This was a default in pytorch until 1.12
+ torch.backends.cuda.matmul.allow_tf32 = True
+ torch.backends.cudnn.benchmark = True
+ torch.backends.cudnn.deterministic = False
+
+ # fully initialize distributed device environment
+ device = init_distributed_device(args)
+
+ # get the name of the experiments
+ if args.name is None:
+ # sanitize model name for filesystem / uri use, easier if we don't use / in name as a rule?
+ model_name_safe = args.model.replace('/', '-')
+ date_str = datetime.now().strftime("%Y_%m_%d-%H_%M_%S")
+ if args.distributed:
+ # sync date_str from master to all ranks
+ date_str = broadcast_object(args, date_str)
+ args.name = '-'.join([
+ date_str,
+ f"model_{model_name_safe}",
+ f"lr_{args.lr}",
+ f"b_{args.batch_size}",
+ f"j_{args.workers}",
+ f"p_{args.precision}",
+ ])
+
+ resume_latest = args.resume == 'latest'
+ log_base_path = os.path.join(args.logs, args.name)
+ args.log_path = None
+ if is_master(args, local=args.log_local):
+ os.makedirs(log_base_path, exist_ok=True)
+ log_filename = f'out-{args.rank}' if args.log_local else 'out.log'
+ args.log_path = os.path.join(log_base_path, log_filename)
+ if os.path.exists(args.log_path) and not resume_latest:
+ print(
+ "Error. Experiment already exists. Use --name {} to specify a new experiment."
+ )
+ return -1
+
+ # Setup text logger
+ args.log_level = logging.DEBUG if args.debug else logging.INFO
+ setup_logging(args.log_path, args.log_level)
+
+ # Setup wandb, tensorboard, checkpoint logging
+ args.wandb = 'wandb' in args.report_to or 'all' in args.report_to
+ args.tensorboard = 'tensorboard' in args.report_to or 'all' in args.report_to
+ args.checkpoint_path = os.path.join(log_base_path, "checkpoints")
+ if is_master(args):
+ args.tensorboard_path = os.path.join(log_base_path, "tensorboard") if args.tensorboard else ''
+ for dirname in [args.tensorboard_path, args.checkpoint_path]:
+ if dirname:
+ os.makedirs(dirname, exist_ok=True)
+ else:
+ args.tensorboard_path = ''
+
+ if resume_latest:
+ resume_from = None
+ checkpoint_path = args.checkpoint_path
+ # If using remote_sync, need to check the remote instead of the local checkpoints folder.
+ if args.remote_sync is not None:
+ checkpoint_path = os.path.join(args.remote_sync, args.name, "checkpoints")
+ if args.save_most_recent:
+ print('Error. Cannot use save-most-recent with remote_sync and resume latest.')
+ return -1
+ if args.remote_sync_protocol != 's3':
+ print('Error. Sync protocol not supported when using resume latest.')
+ return -1
+ if is_master(args):
+ # Checking for existing checkpoint via master rank only. It is possible for
+ # different rank processes to see different files if a shared file-system is under
+ # stress, however it's very difficult to fully work around such situations.
+ if args.save_most_recent:
+ # if --save-most-recent flag is set, look for latest at a fixed filename
+ resume_from = os.path.join(checkpoint_path, LATEST_CHECKPOINT_NAME)
+ if not os.path.exists(resume_from):
+ # If no latest checkpoint has been saved yet, don't try to resume
+ resume_from = None
+ else:
+ # otherwise, list checkpoint dir contents and pick the newest checkpoint
+ resume_from = get_latest_checkpoint(checkpoint_path, remote=args.remote_sync is not None)
+ if resume_from:
+ logging.info(f'Found latest resume checkpoint at {resume_from}.')
+ else:
+ logging.info(f'No latest resume checkpoint found in {checkpoint_path}.')
+ if args.distributed:
+ # sync found checkpoint path to all ranks
+ resume_from = broadcast_object(args, resume_from)
+ args.resume = resume_from
+
+ if args.copy_codebase:
+ copy_codebase(args)
+
+ # start the sync proces if remote-sync is not None
+ remote_sync_process = None
+ if is_master(args) and args.remote_sync is not None:
+ # first make sure it works
+ result = remote_sync(
+ os.path.join(args.logs, args.name),
+ os.path.join(args.remote_sync, args.name),
+ args.remote_sync_protocol
+ )
+ if result:
+ logging.info('remote sync successful.')
+ else:
+ logging.info('Error: remote sync failed. Exiting.')
+ return -1
+ # if all looks good, start a process to do this every args.remote_sync_frequency seconds
+ remote_sync_process = start_sync_process(
+ args.remote_sync_frequency,
+ os.path.join(args.logs, args.name),
+ os.path.join(args.remote_sync, args.name),
+ args.remote_sync_protocol
+ )
+ remote_sync_process.start()
+
+ if args.precision == 'fp16':
+ logging.warning(
+ 'It is recommended to use AMP mixed-precision instead of FP16. '
+ 'FP16 support needs further verification and tuning, especially for train.')
+
+ if args.horovod:
+ logging.info(
+ f'Running in horovod mode with multiple processes / nodes. Device: {args.device}.'
+ f'Process (global: {args.rank}, local {args.local_rank}), total {args.world_size}.')
+ elif args.distributed:
+ logging.info(
+ f'Running in distributed mode with multiple processes. Device: {args.device}.'
+ f'Process (global: {args.rank}, local {args.local_rank}), total {args.world_size}.')
+ else:
+ logging.info(f'Running with a single process. Device {args.device}.')
+
+ dist_model = None
+ args.distill = args.distill_model is not None and args.distill_pretrained is not None
+ if args.distill:
+ #FIXME: support distillation with grad accum.
+ assert args.accum_freq == 1
+ #FIXME: support distillation with coca.
+ assert 'coca' not in args.model.lower()
+
+ if isinstance(args.force_image_size, (tuple, list)) and len(args.force_image_size) == 1:
+ # arg is nargs, single (square) image size list -> int
+ args.force_image_size = args.force_image_size[0]
+ random_seed(args.seed, 0)
+ model_kwargs = {}
+ if args.siglip:
+ model_kwargs['init_logit_scale'] = np.log(10) # different from CLIP
+ model_kwargs['init_logit_bias'] = -10
+ model, preprocess_train, preprocess_val = create_model_and_transforms(
+ args.model,
+ args.pretrained,
+ precision=args.precision,
+ device=device,
+ jit=args.torchscript,
+ force_quick_gelu=args.force_quick_gelu,
+ force_custom_text=args.force_custom_text,
+ force_patch_dropout=args.force_patch_dropout,
+ force_image_size=args.force_image_size,
+ image_mean=args.image_mean,
+ image_std=args.image_std,
+ image_interpolation=args.image_interpolation,
+ image_resize_mode=args.image_resize_mode, # only effective for inference
+ aug_cfg=args.aug_cfg,
+ pretrained_image=args.pretrained_image,
+ output_dict=True,
+ cache_dir=args.cache_dir,
+ **model_kwargs,
+ )
+ if args.distill:
+ # FIXME: currently assumes the model you're distilling from has the same tokenizer & transforms.
+ dist_model, _, _ = create_model_and_transforms(
+ args.distill_model,
+ args.distill_pretrained,
+ device=device,
+ precision=args.precision,
+ output_dict=True,
+ cache_dir=args.cache_dir,
+ )
+ if args.use_bnb_linear is not None:
+ print('=> using a layer from bitsandbytes.\n'
+ ' this is an experimental feature which requires two extra pip installs\n'
+ ' pip install bitsandbytes triton'
+ ' please make sure to use triton 2.0.0')
+ import bitsandbytes as bnb
+ from open_clip.utils import replace_linear
+ print(f'=> replacing linear layers with {args.use_bnb_linear}')
+ linear_replacement_cls = getattr(bnb.nn.triton_based_modules, args.use_bnb_linear)
+ replace_linear(model, linear_replacement_cls)
+ model = model.to(device)
+
+ random_seed(args.seed, args.rank)
+
+ if args.trace:
+ model = trace_model(model, batch_size=args.batch_size, device=device)
+
+ if args.lock_image:
+ # lock image tower as per LiT - https://arxiv.org/abs/2111.07991
+ model.lock_image_tower(
+ unlocked_groups=args.lock_image_unlocked_groups,
+ freeze_bn_stats=args.lock_image_freeze_bn_stats)
+ if args.lock_text:
+ model.lock_text_tower(
+ unlocked_layers=args.lock_text_unlocked_layers,
+ freeze_layer_norm=args.lock_text_freeze_layer_norm)
+
+ if args.grad_checkpointing:
+ model.set_grad_checkpointing()
+
+ if is_master(args):
+ logging.info("Model:")
+ logging.info(f"{str(model)}")
+ logging.info("Params:")
+ params_file = os.path.join(args.logs, args.name, "params.txt")
+ with open(params_file, "w") as f:
+ for name in sorted(vars(args)):
+ val = getattr(args, name)
+ logging.info(f" {name}: {val}")
+ f.write(f"{name}: {val}\n")
+
+ if args.distributed and not args.horovod:
+ if args.use_bn_sync:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
+ ddp_args = {}
+ if args.ddp_static_graph:
+ # this doesn't exist in older PyTorch, arg only added if enabled
+ ddp_args['static_graph'] = True
+ model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device], **ddp_args)
+
+ if args.distill:
+ dist_model = torch.nn.parallel.DistributedDataParallel(dist_model, device_ids=[device], **ddp_args)
+
+ # create optimizer and scaler
+ optimizer = None
+ scaler = None
+
+ if args.train_data or args.dataset_type == "synthetic":
+ assert not args.trace, 'Cannot train with traced model'
+
+ opt = getattr(args, 'opt', 'adamw').lower()
+ if opt.startswith('timm/'):
+ from timm.optim import create_optimizer_v2
+ timm_opt = opt.split('timm/')[-1]
+ opt_kwargs = {}
+ assert (args.beta1 is None) == (args.beta2 is None), \
+ 'When using timm optimizer, BOTH beta1 and beta2 must be specified (or not specified).'
+ if args.beta1 is not None:
+ opt_kwargs['betas'] = (args.beta1, args.beta2)
+ if args.momentum is not None:
+ opt_kwargs['momentum'] = args.momentum
+ optimizer = create_optimizer_v2(
+ model,
+ timm_opt,
+ lr=args.lr,
+ weight_decay=args.wd,
+ eps=args.eps,
+ **opt_kwargs,
+ )
+ else:
+ # If some params are not passed, we use the default values based on model name.
+ exclude = lambda n, p: p.ndim < 2 or "bn" in n or "ln" in n or "bias" in n or 'logit_scale' in n
+ include = lambda n, p: not exclude(n, p)
+
+ named_parameters = list(model.named_parameters())
+ gain_or_bias_params = [p for n, p in named_parameters if exclude(n, p) and p.requires_grad]
+ rest_params = [p for n, p in named_parameters if include(n, p) and p.requires_grad]
+
+ if opt == 'adamw':
+ optimizer = optim.AdamW(
+ [
+ {"params": gain_or_bias_params, "weight_decay": 0.},
+ {"params": rest_params, "weight_decay": args.wd},
+ ],
+ lr=args.lr,
+ betas=(args.beta1, args.beta2),
+ eps=args.eps,
+ )
+ else:
+ assert False, f'Unknown optimizer {opt}'
+
+ if is_master(args):
+ if is_master(args):
+ defaults = copy.deepcopy(optimizer.defaults)
+ defaults['weight_decay'] = args.wd
+ defaults = ', '.join([f'{k}: {v}' for k, v in defaults.items()])
+ logging.info(
+ f'Created {type(optimizer).__name__} ({args.opt}) optimizer: {defaults}'
+ )
+
+ if args.horovod:
+ optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
+ hvd.broadcast_parameters(model.state_dict(), root_rank=0)
+ hvd.broadcast_optimizer_state(optimizer, root_rank=0)
+
+ scaler = None
+ if args.precision == "amp":
+ try:
+ # scaler = torch.amp.GradScaler(device=device)
+ scaler = torch.cuda.amp.GradScaler()
+ except (AttributeError, TypeError) as e:
+ scaler = torch.cuda.amp.GradScaler()
+
+ # optionally resume from a checkpoint
+ start_epoch = 0
+ if args.resume is not None:
+ checkpoint = pt_load(args.resume, map_location='cpu')
+ if 'epoch' in checkpoint:
+ # resuming a train checkpoint w/ epoch and optimizer state
+ start_epoch = checkpoint["epoch"]
+ sd = checkpoint["state_dict"]
+ if not args.distributed and next(iter(sd.items()))[0].startswith('module'):
+ sd = {k[len('module.'):]: v for k, v in sd.items()}
+ model.load_state_dict(sd)
+ if optimizer is not None:
+ optimizer.load_state_dict(checkpoint["optimizer"])
+ if scaler is not None and 'scaler' in checkpoint:
+ scaler.load_state_dict(checkpoint['scaler'])
+ logging.info(f"=> resuming checkpoint '{args.resume}' (epoch {start_epoch})")
+ else:
+ # loading a bare (model only) checkpoint for fine-tune or evaluation
+ model.load_state_dict(checkpoint)
+ logging.info(f"=> loaded checkpoint '{args.resume}' (epoch {start_epoch})")
+
+ # initialize datasets
+ tokenizer = get_tokenizer(args.model, cache_dir=args.cache_dir)
+ data = get_data(
+ args,
+ (preprocess_train, preprocess_val),
+ epoch=start_epoch,
+ tokenizer=tokenizer,
+ )
+ assert len(data), 'At least one train or eval dataset must be specified.'
+
+ # create scheduler if train
+ scheduler = None
+ if 'train' in data and optimizer is not None:
+ total_steps = (data["train"].dataloader.num_batches // args.accum_freq) * args.epochs
+ if args.lr_scheduler == "cosine":
+ scheduler = cosine_lr(optimizer, args.lr, args.warmup, total_steps)
+ elif args.lr_scheduler == "const":
+ scheduler = const_lr(optimizer, args.lr, args.warmup, total_steps)
+ elif args.lr_scheduler == "const-cooldown":
+ assert args.epochs_cooldown is not None,\
+ "Please specify the number of cooldown epochs for this lr schedule."
+ cooldown_steps = (data["train"].dataloader.num_batches // args.accum_freq) * args.epochs_cooldown
+ scheduler = const_lr_cooldown(
+ optimizer, args.lr, args.warmup, total_steps,
+ cooldown_steps, args.lr_cooldown_power, args.lr_cooldown_end)
+ else:
+ logging.error(
+ f'Unknown scheduler, {args.lr_scheduler}. Available options are: cosine, const, const-cooldown.')
+ exit(1)
+
+ # determine if this worker should save logs and checkpoints. only do so if it is rank == 0
+ args.save_logs = args.logs and args.logs.lower() != 'none' and is_master(args)
+ writer = None
+ if args.save_logs and args.tensorboard:
+ assert tensorboard is not None, "Please install tensorboard."
+ writer = tensorboard.SummaryWriter(args.tensorboard_path)
+
+ if args.wandb and is_master(args):
+ assert wandb is not None, 'Please install wandb.'
+ logging.debug('Starting wandb.')
+ args.train_sz = data["train"].dataloader.num_samples
+ if args.val_data is not None:
+ args.val_sz = data["val"].dataloader.num_samples
+ # you will have to configure this for your project!
+ wandb.init(
+ project=args.wandb_project_name,
+ name=args.name,
+ id=args.name,
+ notes=args.wandb_notes,
+ tags=[],
+ resume='auto' if args.resume == "latest" else None,
+ config=vars(args),
+ )
+ if args.debug:
+ wandb.watch(model, log='all')
+ wandb.save(params_file)
+ logging.debug('Finished loading wandb.')
+
+ # Pytorch 2.0 adds '_orig_mod.' prefix to keys of state_dict() of compiled models.
+ # For compatibility, we save state_dict() of the original model, which shares the
+ # weights without the prefix.
+ original_model = model
+ if args.torchcompile:
+ logging.info('Compiling model...')
+
+ if args.grad_checkpointing and args.distributed:
+ logging.info('Disabling DDP dynamo optimizer when grad checkpointing enabled.')
+ # As of now (~PyTorch 2.4/2.5), compile + grad checkpointing work, but DDP optimizer must be disabled
+ torch._dynamo.config.optimize_ddp = False
+
+ model = torch.compile(original_model)
+
+ if 'train' not in data:
+ # If using int8, convert to inference mode.
+ if args.use_bnb_linear is not None:
+ from open_clip.utils import convert_int8_model_to_inference_mode
+ convert_int8_model_to_inference_mode(model)
+ # Evaluate.
+ evaluate(model, data, start_epoch, args, tb_writer=writer, tokenizer=tokenizer)
+ return
+
+ loss = create_loss(args)
+
+ # torch.autograd.set_detect_anomaly(True)
+
+ for epoch in range(start_epoch, args.epochs):
+ if is_master(args):
+ logging.info(f'Start epoch {epoch}')
+
+ train_one_epoch(model, data, loss, epoch, optimizer, scaler, scheduler, dist_model, args, tb_writer=writer)
+ completed_epoch = epoch + 1
+
+ if any(v in data for v in ('val', 'imagenet-val', 'imagenet-v2')):
+ evaluate(model, data, completed_epoch, args, tb_writer=writer, tokenizer=tokenizer)
+
+ # Saving checkpoints.
+ if args.save_logs:
+ checkpoint_dict = {
+ "epoch": completed_epoch,
+ "name": args.name,
+ "state_dict": original_model.state_dict(),
+ "optimizer": optimizer.state_dict(),
+ }
+ if scaler is not None:
+ checkpoint_dict["scaler"] = scaler.state_dict()
+
+ if completed_epoch == args.epochs or (
+ args.save_frequency > 0 and (completed_epoch % args.save_frequency) == 0
+ ):
+ torch.save(
+ checkpoint_dict,
+ os.path.join(args.checkpoint_path, f"epoch_{completed_epoch}.pt"),
+ )
+ if args.delete_previous_checkpoint:
+ previous_checkpoint = os.path.join(args.checkpoint_path, f"epoch_{completed_epoch - 1}.pt")
+ if os.path.exists(previous_checkpoint):
+ os.remove(previous_checkpoint)
+
+ if args.save_most_recent:
+ # try not to corrupt the latest checkpoint if save fails
+ tmp_save_path = os.path.join(args.checkpoint_path, "tmp.pt")
+ latest_save_path = os.path.join(args.checkpoint_path, LATEST_CHECKPOINT_NAME)
+ torch.save(checkpoint_dict, tmp_save_path)
+ os.replace(tmp_save_path, latest_save_path)
+
+ if args.wandb and is_master(args):
+ wandb.finish()
+
+ # run a final sync.
+ if remote_sync_process is not None:
+ logging.info('Final remote sync.')
+ remote_sync_process.terminate()
+ result = remote_sync(
+ os.path.join(args.logs, args.name),
+ os.path.join(args.remote_sync, args.name),
+ args.remote_sync_protocol
+ )
+ if result:
+ logging.info('Final remote sync successful.')
+ else:
+ logging.info('Final remote sync failed.')
+
+
+def copy_codebase(args):
+ from shutil import copytree, ignore_patterns
+ new_code_path = os.path.join(args.logs, args.name, "code")
+ if os.path.exists(new_code_path):
+ print(
+ f"Error. Experiment already exists at {new_code_path}. Use --name to specify a new experiment."
+ )
+ return -1
+ print(f"Copying codebase to {new_code_path}")
+ current_code_path = os.path.realpath(__file__)
+ for _ in range(3):
+ current_code_path = os.path.dirname(current_code_path)
+ copytree(current_code_path, new_code_path, ignore=ignore_patterns('log', 'logs', 'wandb'))
+ print("Done copying code.")
+ return 1
+
+
+if __name__ == "__main__":
+ main(sys.argv[1:])
diff --git a/src/open_clip_train/params.py b/src/open_clip_train/params.py
new file mode 100644
index 0000000000000000000000000000000000000000..31771cb85fb9c1c32f9ead769900decbaf19e77a
--- /dev/null
+++ b/src/open_clip_train/params.py
@@ -0,0 +1,488 @@
+import argparse
+import ast
+
+
+def get_default_params(model_name):
+ # Params from paper (https://arxiv.org/pdf/2103.00020.pdf)
+ model_name = model_name.lower()
+ if "vit" in model_name:
+ return {"lr": 5.0e-4, "beta1": 0.9, "beta2": 0.98, "eps": 1.0e-6}
+ else:
+ return {"lr": 5.0e-4, "beta1": 0.9, "beta2": 0.999, "eps": 1.0e-8}
+
+
+class ParseKwargs(argparse.Action):
+ def __call__(self, parser, namespace, values, option_string=None):
+ kw = {}
+ for value in values:
+ key, value = value.split('=')
+ try:
+ kw[key] = ast.literal_eval(value)
+ except ValueError:
+ kw[key] = str(value) # fallback to string (avoid need to escape on command line)
+ setattr(namespace, self.dest, kw)
+
+
+def parse_args(args):
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--train-data",
+ type=str,
+ default=None,
+ help="Path to file(s) with training data. When using webdataset, multiple datasources can be combined using the `::` separator.",
+ )
+ parser.add_argument(
+ "--train-data-upsampling-factors",
+ type=str,
+ default=None,
+ help=(
+ "When using multiple data sources with webdataset and sampling with replacement, this can be used to upsample specific data sources. "
+ "Similar to --train-data, this should be a string with as many numbers as there are data sources, separated by `::` (e.g. 1::2::0.5) "
+ "By default, datapoints are sampled uniformly regardless of the dataset sizes."
+ )
+ )
+ parser.add_argument(
+ "--val-data",
+ type=str,
+ default=None,
+ help="Path to file(s) with validation data",
+ )
+ parser.add_argument(
+ "--train-num-samples",
+ type=int,
+ default=None,
+ help="Number of samples in dataset. Required for webdataset if not available in info file.",
+ )
+ parser.add_argument(
+ "--val-num-samples",
+ type=int,
+ default=None,
+ help="Number of samples in dataset. Useful for webdataset if not available in info file.",
+ )
+ parser.add_argument(
+ "--dataset-type",
+ choices=["webdataset", "csv", "jsonl", "synthetic", "auto"],
+ default="auto",
+ help="Which type of dataset to process."
+ )
+ parser.add_argument(
+ "--dataset-resampled",
+ default=False,
+ action="store_true",
+ help="Whether to use sampling with replacement for webdataset shard selection."
+ )
+ parser.add_argument(
+ "--csv-separator",
+ type=str,
+ default="\t",
+ help="For csv-like datasets, which separator to use."
+ )
+ parser.add_argument(
+ "--csv-img-key",
+ type=str,
+ default="filepath",
+ help="For csv-like datasets, the name of the key for the image paths."
+ )
+ parser.add_argument(
+ "--csv-caption-key",
+ type=str,
+ default="title",
+ help="For csv-like datasets, the name of the key for the captions."
+ )
+ parser.add_argument(
+ "--imagenet-val",
+ type=str,
+ default=None,
+ help="Path to imagenet val set for conducting zero shot evaluation.",
+ )
+ parser.add_argument(
+ "--imagenet-v2",
+ type=str,
+ default=None,
+ help="Path to imagenet v2 for conducting zero shot evaluation.",
+ )
+ parser.add_argument(
+ "--cache-dir",
+ type=str,
+ default=None,
+ help="Override system default cache path for model & tokenizer file downloads.",
+ )
+ parser.add_argument(
+ "--logs",
+ type=str,
+ default="./logs/",
+ help="Where to store tensorboard logs. Use None to avoid storing logs.",
+ )
+ parser.add_argument(
+ "--log-local",
+ action="store_true",
+ default=False,
+ help="log files on local master, otherwise global master only.",
+ )
+ parser.add_argument(
+ "--name",
+ type=str,
+ default=None,
+ help="Optional identifier for the experiment when storing logs. Otherwise use current time.",
+ )
+ parser.add_argument(
+ "--workers", type=int, default=4, help="Number of dataloader workers per GPU."
+ )
+ parser.add_argument(
+ "--batch-size", type=int, default=64, help="Batch size per GPU."
+ )
+ parser.add_argument(
+ "--epochs", type=int, default=32, help="Number of epochs to train for."
+ )
+ parser.add_argument(
+ "--epochs-cooldown", type=int, default=None,
+ help="When scheduler w/ cooldown used, perform cooldown from total_epochs - cooldown_epochs onwards."
+ )
+ parser.add_argument("--lr", type=float, default=None, help="Learning rate.")
+ parser.add_argument("--beta1", type=float, default=None, help="Adam beta 1.")
+ parser.add_argument("--beta2", type=float, default=None, help="Adam beta 2.")
+ parser.add_argument("--eps", type=float, default=None, help="Adam epsilon.")
+ parser.add_argument("--wd", type=float, default=0.2, help="Weight decay.")
+ parser.add_argument("--momentum", type=float, default=None, help="Momentum (for timm optimizers).")
+ parser.add_argument(
+ "--warmup", type=int, default=10000, help="Number of steps to warmup for."
+ )
+ parser.add_argument(
+ "--opt", type=str, default='adamw',
+ help="Which optimizer to use. Choices are ['adamw', or any timm optimizer 'timm/{opt_name}']."
+ )
+ parser.add_argument(
+ "--use-bn-sync",
+ default=False,
+ action="store_true",
+ help="Whether to use batch norm sync.")
+ parser.add_argument(
+ "--skip-scheduler",
+ action="store_true",
+ default=False,
+ help="Use this flag to skip the learning rate decay.",
+ )
+ parser.add_argument(
+ "--lr-scheduler",
+ type=str,
+ default='cosine',
+ help="LR scheduler. One of: 'cosine', 'const' (constant), 'const-cooldown' (constant w/ cooldown). Default: cosine",
+ )
+ parser.add_argument(
+ "--lr-cooldown-end", type=float, default=0.0,
+ help="End learning rate for cooldown schedule. Default: 0"
+ )
+ parser.add_argument(
+ "--lr-cooldown-power", type=float, default=1.0,
+ help="Power for polynomial cooldown schedule. Default: 1.0 (linear decay)"
+ )
+ parser.add_argument(
+ "--save-frequency", type=int, default=1, help="How often to save checkpoints."
+ )
+ parser.add_argument(
+ "--save-most-recent",
+ action="store_true",
+ default=False,
+ help="Always save the most recent model trained to epoch_latest.pt.",
+ )
+ parser.add_argument(
+ "--zeroshot-frequency", type=int, default=2, help="How often to run zero shot."
+ )
+ parser.add_argument(
+ "--val-frequency", type=int, default=1, help="How often to run evaluation with val data."
+ )
+ parser.add_argument(
+ "--resume",
+ default=None,
+ type=str,
+ help="path to latest checkpoint (default: none)",
+ )
+ parser.add_argument(
+ "--precision",
+ choices=["amp", "amp_bf16", "amp_bfloat16", "bf16", "fp16", "pure_bf16", "pure_fp16", "fp32"],
+ default="amp",
+ help="Floating point precision."
+ )
+ parser.add_argument(
+ "--model",
+ type=str,
+ default="RN50",
+ help="Name of the vision backbone to use.",
+ )
+ parser.add_argument(
+ "--pretrained",
+ default='',
+ type=str,
+ help="Use a pretrained CLIP model weights with the specified tag or file path.",
+ )
+ parser.add_argument(
+ "--pretrained-image",
+ default=False,
+ action='store_true',
+ help="Load imagenet pretrained weights for image tower backbone if available.",
+ )
+ parser.add_argument(
+ "--lock-image",
+ default=False,
+ action='store_true',
+ help="Lock full image tower by disabling gradients.",
+ )
+ parser.add_argument(
+ "--lock-image-unlocked-groups",
+ type=int,
+ default=0,
+ help="Leave last n image tower layer groups unlocked.",
+ )
+ parser.add_argument(
+ "--lock-image-freeze-bn-stats",
+ default=False,
+ action='store_true',
+ help="Freeze BatchNorm running stats in image tower for any locked layers.",
+ )
+ parser.add_argument(
+ '--image-mean', type=float, nargs='+', default=None, metavar='MEAN',
+ help='Override default image mean value of dataset')
+ parser.add_argument(
+ '--image-std', type=float, nargs='+', default=None, metavar='STD',
+ help='Override default image std deviation of of dataset')
+ parser.add_argument(
+ '--image-interpolation',
+ default=None, type=str, choices=['bicubic', 'bilinear', 'random'],
+ help="Override default image resize interpolation"
+ )
+ parser.add_argument(
+ '--image-resize-mode',
+ default=None, type=str, choices=['shortest', 'longest', 'squash'],
+ help="Override default image resize (& crop) mode during inference"
+ )
+ parser.add_argument('--aug-cfg', nargs='*', default={}, action=ParseKwargs)
+ parser.add_argument(
+ "--grad-checkpointing",
+ default=False,
+ action='store_true',
+ help="Enable gradient checkpointing.",
+ )
+ parser.add_argument(
+ "--local-loss",
+ default=False,
+ action="store_true",
+ help="calculate loss w/ local features @ global (instead of realizing full global @ global matrix)"
+ )
+ parser.add_argument(
+ "--gather-with-grad",
+ default=False,
+ action="store_true",
+ help="enable full distributed gradient for feature gather"
+ )
+ parser.add_argument(
+ '--force-image-size', type=int, nargs='+', default=None,
+ help='Override default image size'
+ )
+ parser.add_argument(
+ "--force-quick-gelu",
+ default=False,
+ action='store_true',
+ help="Force use of QuickGELU activation for non-OpenAI transformer models.",
+ )
+ parser.add_argument(
+ "--force-patch-dropout",
+ default=None,
+ type=float,
+ help="Override the patch dropout during training, for fine tuning with no dropout near the end as in the paper",
+ )
+ parser.add_argument(
+ "--force-custom-text",
+ default=False,
+ action='store_true',
+ help="Force use of CustomTextCLIP model (separate text-tower).",
+ )
+ parser.add_argument(
+ "--torchscript",
+ default=False,
+ action='store_true',
+ help="torch.jit.script the model, also uses jit version of OpenAI models if pretrained=='openai'",
+ )
+ parser.add_argument(
+ "--torchcompile",
+ default=False,
+ action='store_true',
+ help="torch.compile() the model, requires pytorch 2.0 or later.",
+ )
+ parser.add_argument(
+ "--trace",
+ default=False,
+ action='store_true',
+ help="torch.jit.trace the model for inference / eval only",
+ )
+ parser.add_argument(
+ "--accum-freq", type=int, default=1, help="Update the model every --acum-freq steps."
+ )
+ parser.add_argument(
+ "--device", default="cuda", type=str, help="Accelerator to use."
+ )
+ # arguments for distributed training
+ parser.add_argument(
+ "--dist-url",
+ default=None,
+ type=str,
+ help="url used to set up distributed training",
+ )
+ parser.add_argument(
+ "--dist-backend",
+ default=None,
+ type=str,
+ help="distributed backend. \"nccl\" for GPU, \"hccl\" for Ascend NPU"
+ )
+ parser.add_argument(
+ "--report-to",
+ default='',
+ type=str,
+ help="Options are ['wandb', 'tensorboard', 'wandb,tensorboard']"
+ )
+ parser.add_argument(
+ "--wandb-notes",
+ default='',
+ type=str,
+ help="Notes if logging with wandb"
+ )
+ parser.add_argument(
+ "--wandb-project-name",
+ type=str,
+ default='open-clip',
+ help="Name of the project if logging with wandb.",
+ )
+ parser.add_argument(
+ "--debug",
+ default=False,
+ action="store_true",
+ help="If true, more information is logged."
+ )
+ parser.add_argument(
+ "--copy-codebase",
+ default=False,
+ action="store_true",
+ help="If true, we copy the entire base on the log directory, and execute from there."
+ )
+ parser.add_argument(
+ "--horovod",
+ default=False,
+ action="store_true",
+ help="Use horovod for distributed training."
+ )
+ parser.add_argument(
+ "--ddp-static-graph",
+ default=False,
+ action='store_true',
+ help="Enable static graph optimization for DDP in PyTorch >= 1.11.",
+ )
+ parser.add_argument(
+ "--no-set-device-rank",
+ default=False,
+ action="store_true",
+ help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc)."
+ )
+ parser.add_argument(
+ "--seed", type=int, default=0, help="Default random seed."
+ )
+ parser.add_argument(
+ "--grad-clip-norm", type=float, default=None, help="Gradient clip."
+ )
+ parser.add_argument(
+ "--lock-text",
+ default=False,
+ action='store_true',
+ help="Lock full text tower by disabling gradients.",
+ )
+ parser.add_argument(
+ "--lock-text-unlocked-layers",
+ type=int,
+ default=0,
+ help="Leave last n text tower layer groups unlocked.",
+ )
+ parser.add_argument(
+ "--lock-text-freeze-layer-norm",
+ default=False,
+ action='store_true',
+ help="Freeze LayerNorm running stats in text tower for any locked layers.",
+ )
+ parser.add_argument(
+ "--log-every-n-steps",
+ type=int,
+ default=100,
+ help="Log every n steps to tensorboard/console/wandb.",
+ )
+ parser.add_argument(
+ "--coca-caption-loss-weight",
+ type=float,
+ default=2.0,
+ help="Weight assigned to caption loss in CoCa."
+ )
+ parser.add_argument(
+ "--coca-contrastive-loss-weight",
+ type=float,
+ default=1.0,
+ help="Weight assigned to contrastive loss when training CoCa."
+ )
+ parser.add_argument(
+ "--remote-sync",
+ type=str,
+ default=None,
+ help="Optinoally sync with a remote path specified by this arg",
+ )
+ parser.add_argument(
+ "--remote-sync-frequency",
+ type=int,
+ default=300,
+ help="How frequently to sync to a remote directly if --remote-sync is not None.",
+ )
+ parser.add_argument(
+ "--remote-sync-protocol",
+ choices=["s3", "fsspec"],
+ default="s3",
+ help="How to do the remote sync backup if --remote-sync is not None.",
+ )
+ parser.add_argument(
+ "--delete-previous-checkpoint",
+ default=False,
+ action="store_true",
+ help="If true, delete previous checkpoint after storing a new one."
+ )
+ parser.add_argument(
+ "--distill-model",
+ default=None,
+ help='Which model arch to distill from, if any.'
+ )
+ parser.add_argument(
+ "--distill-pretrained",
+ default=None,
+ help='Which pre-trained weights to distill from, if any.'
+ )
+ parser.add_argument(
+ "--use-bnb-linear",
+ default=None,
+ help='Replace the network linear layers from the bitsandbytes library. '
+ 'Allows int8 training/inference, etc.'
+ )
+ parser.add_argument(
+ "--siglip",
+ default=False,
+ action="store_true",
+ help='Use SigLip (sigmoid) loss.'
+ )
+ parser.add_argument(
+ "--loss-dist-impl",
+ default=None,
+ type=str,
+ help='A string to specify a specific distributed loss implementation.'
+ )
+
+ args = parser.parse_args(args)
+
+ if 'timm' not in args.opt:
+ # set default opt params based on model name (only if timm optimizer not used)
+ default_params = get_default_params(args.model)
+ for name, val in default_params.items():
+ if getattr(args, name) is None:
+ setattr(args, name, val)
+
+ return args
diff --git a/src/open_clip_train/precision.py b/src/open_clip_train/precision.py
new file mode 100644
index 0000000000000000000000000000000000000000..5af494892d1c2c0c26fc878f2e1fa69b585194cb
--- /dev/null
+++ b/src/open_clip_train/precision.py
@@ -0,0 +1,14 @@
+import torch
+from contextlib import suppress
+from functools import partial
+
+
+def get_autocast(precision, device_type='cuda'):
+ if precision =='amp':
+ amp_dtype = torch.float16
+ elif precision == 'amp_bfloat16' or precision == 'amp_bf16':
+ amp_dtype = torch.bfloat16
+ else:
+ return suppress
+
+ return partial(torch.amp.autocast, device_type=device_type, dtype=amp_dtype)
\ No newline at end of file
diff --git a/src/open_clip_train/profiler.py b/src/open_clip_train/profiler.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6521d1f00d76df484cee15a85139289719a83dd
--- /dev/null
+++ b/src/open_clip_train/profiler.py
@@ -0,0 +1,249 @@
+import argparse
+
+import torch
+import open_clip
+import pandas as pd
+from torch.utils.flop_counter import FlopCounterMode
+try:
+ import fvcore
+except:
+ fvcore = None
+
+parser = argparse.ArgumentParser(description='OpenCLIP Profiler')
+
+# benchmark specific args
+parser.add_argument('--model', metavar='NAME', default='',
+ help='model(s) to profile')
+parser.add_argument('--results-file', default='', type=str, metavar='FILENAME',
+ help='Output csv file for results')
+parser.add_argument('--profiler', default='torch', type=str, choices=['torch', 'fvcore'])
+parser.add_argument('--batch-size', default=1, type=int, help='Batch size for profiling')
+
+
+def profile_fvcore(
+ model,
+ image_input_size=(3, 224, 224),
+ text_input_size=(77,),
+ batch_size=1,
+ detailed=False,
+ force_cpu=False
+):
+ if force_cpu:
+ model = model.to('cpu')
+ device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
+ example_image_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
+ example_text_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
+ fca = fvcore.nn.FlopCountAnalysis(model, (example_image_input, example_text_input))
+ aca = fvcore.nn.ActivationCountAnalysis(model, (example_image_input, example_text_input))
+ if detailed:
+ fcs = fvcore.nn.flop_count_str(fca)
+ print(fcs)
+ return fca.total() / batch_size, aca.total() / batch_size
+
+
+def profile_fvcore_text(
+ model,
+ text_input_size=(77,),
+ batch_size=1,
+ detailed=False,
+ force_cpu=False
+):
+ if force_cpu:
+ model = model.to('cpu')
+ device = next(model.parameters()).device
+ example_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
+ fca = fvcore.nn.FlopCountAnalysis(model, example_input)
+ aca = fvcore.nn.ActivationCountAnalysis(model, example_input)
+ if detailed:
+ fcs = fvcore.nn.flop_count_str(fca)
+ print(fcs)
+ return fca.total() / batch_size, aca.total() / batch_size
+
+
+def profile_fvcore_image(
+ model,
+ image_input_size=(3, 224, 224),
+ batch_size=1,
+ detailed=False,
+ force_cpu=False
+):
+ if force_cpu:
+ model = model.to('cpu')
+ device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
+ example_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
+ fca = fvcore.nn.FlopCountAnalysis(model, example_input)
+ aca = fvcore.nn.ActivationCountAnalysis(model, example_input)
+ if detailed:
+ fcs = fvcore.nn.flop_count_str(fca)
+ print(fcs)
+ return fca.total() / batch_size, aca.total() / batch_size
+
+
+def profile_torch_image(model, image_input_size, batch_size=1, force_cpu=False):
+ """Profile the image encoder using torch.utils.flop_counter"""
+ if force_cpu:
+ model = model.to('cpu')
+ device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
+ example_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
+
+ flop_counter = FlopCounterMode()
+ with flop_counter:
+ model(example_input)
+ total_flops = sum(flop_counter.get_flop_counts()['Global'].values())
+ return total_flops / batch_size
+
+
+def profile_torch_text(model, text_input_size, batch_size=1, force_cpu=False):
+ """Profile the text encoder using torch.utils.flop_counter"""
+ if force_cpu:
+ model = model.to('cpu')
+ device = next(model.parameters()).device
+ example_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
+
+ flop_counter = FlopCounterMode()
+ with flop_counter:
+ model(example_input)
+ total_flops = sum(flop_counter.get_flop_counts()['Global'].values())
+ return total_flops / batch_size
+
+
+def profile_torch(model, text_input_size, image_input_size, batch_size=1, force_cpu=False):
+ """Profile the full model using torch.utils.flop_counter"""
+ if force_cpu:
+ model = model.to('cpu')
+ device, dtype = next(model.parameters()).device, next(model.parameters()).dtype
+ image_input = torch.ones((batch_size,) + image_input_size, device=device, dtype=dtype)
+ text_input = torch.ones((batch_size,) + text_input_size, device=device, dtype=torch.int64)
+
+ flop_counter = FlopCounterMode()
+ with flop_counter:
+ model(image_input, text_input)
+ total_flops = sum(flop_counter.get_flop_counts()['Global'].values())
+ return total_flops / batch_size
+
+
+def count_params(model):
+ return sum(m.numel() for m in model.parameters())
+
+def profile_model(model_name, batch_size=1, profiler='torch', device="cuda"):
+ assert profiler in ['torch', 'fvcore'], 'Only torch and fvcore profilers are supported'
+ if profiler == 'fvcore':
+ assert fvcore is not None, 'Please install fvcore.'
+ model = open_clip.create_model(model_name, force_custom_text=True, pretrained_hf=False)
+ model.eval()
+
+ if torch.cuda.is_available():
+ model = model.cuda()
+ elif device == "npu" and torch.npu.is_available():
+ model = model.npu()
+
+ if isinstance(model.visual.image_size, (tuple, list)):
+ image_input_size = (3,) + tuple(model.visual.image_size[-2:])
+ else:
+ image_input_size = (3, model.visual.image_size, model.visual.image_size)
+
+ text_input_size = (77,)
+ if hasattr(model, 'context_length') and model.context_length:
+ text_input_size = (model.context_length,)
+
+ results = {}
+ results['model'] = model_name
+ results['image_size'] = image_input_size[1]
+
+ model_cfg = open_clip.get_model_config(model_name)
+ if model_cfg:
+ vision_cfg = open_clip.CLIPVisionCfg(**model_cfg['vision_cfg'])
+ text_cfg = open_clip.CLIPTextCfg(**model_cfg['text_cfg'])
+ results['image_width'] = int(vision_cfg.width)
+ results['text_width'] = int(text_cfg.width)
+ results['embed_dim'] = int(model_cfg['embed_dim'])
+ else:
+ results['image_width'] = 0
+ results['text_width'] = 0
+ results['embed_dim'] = 0
+
+ retries = 2
+ while retries:
+ retries -= 1
+ try:
+ results['mparams'] = round(count_params(model) / 1e6, 2)
+ results['image_mparams'] = round(count_params(model.visual) / 1e6, 2)
+ results['text_mparams'] = round(count_params(model.text) / 1e6, 2)
+
+ if profiler == 'fvcore':
+ macs, acts = profile_fvcore(
+ model, image_input_size=image_input_size, text_input_size=text_input_size, force_cpu=not retries, batch_size=batch_size)
+
+ image_macs, image_acts = profile_fvcore_image(
+ model.visual, image_input_size=image_input_size, force_cpu=not retries, batch_size=batch_size)
+
+ text_macs, text_acts = profile_fvcore_text(
+ model.text, text_input_size=text_input_size, force_cpu=not retries, batch_size=batch_size)
+
+ results['gmacs'] = round(macs / 1e9, 2)
+ results['macts'] = round(acts / 1e6, 2)
+
+ results['image_gmacs'] = round(image_macs / 1e9, 2)
+ results['image_macts'] = round(image_acts / 1e6, 2)
+
+ results['text_gmacs'] = round(text_macs / 1e9, 2)
+ results['text_macts'] = round(text_acts / 1e6, 2)
+ elif profiler == 'torch':
+ image_flops = profile_torch_image(
+ model.visual, image_input_size=image_input_size, force_cpu=not retries, batch_size=batch_size)
+ text_flops = profile_torch_text(
+ model.text, text_input_size=text_input_size, force_cpu=not retries, batch_size=batch_size)
+ total_flops = profile_torch(
+ model, image_input_size=image_input_size, text_input_size=text_input_size, force_cpu=not retries, batch_size=batch_size)
+
+ results['gflops'] = round(total_flops / 1e9, 2)
+ results['image_gflops'] = round(image_flops / 1e9, 2)
+ results['text_gflops'] = round(text_flops / 1e9, 2)
+
+ except RuntimeError as e:
+ pass
+ return results
+
+
+def main():
+ args = parser.parse_args()
+
+ # FIXME accept a text file name to allow lists of models in txt/csv
+ if args.model == 'all':
+ parsed_model = open_clip.list_models()
+ else:
+ parsed_model = args.model.split(',')
+
+ results = []
+ models_with_errors = []
+ for m in parsed_model:
+ print('='*100)
+ print(f'Profiling {m}')
+ try:
+ row = profile_model(m, batch_size=args.batch_size, profiler=args.profiler, device=args.device)
+ results.append(row)
+ except Exception as e:
+ print(f'Error profiling {m}: {e}')
+ import traceback
+ traceback.print_exc()
+ models_with_errors.append(m)
+
+ df = pd.DataFrame(results, columns=results[0].keys())
+
+ if 'gmacs' in df.columns:
+ df = df.sort_values(by=['gmacs', 'mparams', 'model'])
+ else:
+ df = df.sort_values(by=['gflops', 'mparams', 'model'])
+
+ print('='*100)
+ print('Done.')
+ print(df)
+ if args.results_file:
+ df.to_csv(args.results_file, index=False)
+
+ if models_with_errors:
+ print('Models with errors:', models_with_errors)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/src/open_clip_train/scheduler.py b/src/open_clip_train/scheduler.py
new file mode 100644
index 0000000000000000000000000000000000000000..f76ba110f2b115b5c888c870d913e22640732f54
--- /dev/null
+++ b/src/open_clip_train/scheduler.py
@@ -0,0 +1,57 @@
+import math
+
+
+def assign_learning_rate(optimizer, new_lr):
+ for param_group in optimizer.param_groups:
+ param_group["lr"] = new_lr
+
+
+def _warmup_lr(base_lr, warmup_length, step):
+ return base_lr * (step + 1) / warmup_length
+
+
+def const_lr(optimizer, base_lr, warmup_length, steps):
+ def _lr_adjuster(step):
+ if step < warmup_length:
+ lr = _warmup_lr(base_lr, warmup_length, step)
+ else:
+ lr = base_lr
+ assign_learning_rate(optimizer, lr)
+ return lr
+
+ return _lr_adjuster
+
+
+def const_lr_cooldown(optimizer, base_lr, warmup_length, steps, cooldown_steps, cooldown_power=1.0, cooldown_end_lr=0.):
+ def _lr_adjuster(step):
+ start_cooldown_step = steps - cooldown_steps
+ if step < warmup_length:
+ lr = _warmup_lr(base_lr, warmup_length, step)
+ else:
+ if step < start_cooldown_step:
+ lr = base_lr
+ else:
+ e = step - start_cooldown_step
+ es = steps - start_cooldown_step
+ # linear decay if power == 1; polynomial decay otherwise;
+ decay = (1 - (e / es)) ** cooldown_power
+ lr = decay * (base_lr - cooldown_end_lr) + cooldown_end_lr
+ assign_learning_rate(optimizer, lr)
+ return lr
+
+ return _lr_adjuster
+
+
+def cosine_lr(optimizer, base_lr, warmup_length, steps):
+ def _lr_adjuster(step):
+ if step < warmup_length:
+ lr = _warmup_lr(base_lr, warmup_length, step)
+ else:
+ e = step - warmup_length
+ es = steps - warmup_length
+ lr = 0.5 * (1 + math.cos(math.pi * e / es)) * base_lr
+ assign_learning_rate(optimizer, lr)
+ return lr
+
+ return _lr_adjuster
+
diff --git a/src/open_clip_train/train.py b/src/open_clip_train/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ac138ecd9d6ade8fec03e075bb1d72c84a0cf40
--- /dev/null
+++ b/src/open_clip_train/train.py
@@ -0,0 +1,392 @@
+import json
+import logging
+import math
+import os
+import time
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from torch.nn.parallel.distributed import DistributedDataParallel
+
+try:
+ import wandb
+except ImportError:
+ wandb = None
+
+from open_clip import get_input_dtype, CLIP, CustomTextCLIP
+from open_clip_train.distributed import is_master
+from open_clip_train.zero_shot import zero_shot_eval
+from open_clip_train.precision import get_autocast
+
+
+class AverageMeter(object):
+ """Computes and stores the average and current value"""
+
+ def __init__(self):
+ self.reset()
+
+ def reset(self):
+ self.val = 0
+ self.avg = 0
+ self.sum = 0
+ self.count = 0
+
+ def update(self, val, n=1):
+ self.val = val
+ self.sum += val * n
+ self.count += n
+ self.avg = self.sum / self.count
+
+
+def postprocess_clip_output(model_out):
+ return {
+ "image_features": model_out[0],
+ "text_features": model_out[1],
+ "logit_scale": model_out[2]
+ }
+
+
+def unwrap_model(model):
+ if hasattr(model, 'module'):
+ return model.module
+ else:
+ return model
+
+
+def backward(total_loss, scaler):
+ if scaler is not None:
+ scaler.scale(total_loss).backward()
+ else:
+ total_loss.backward()
+
+
+def train_one_epoch(model, data, loss, epoch, optimizer, scaler, scheduler, dist_model, args, tb_writer=None):
+ device = torch.device(args.device)
+ autocast = get_autocast(args.precision, device_type=device.type)
+ input_dtype = get_input_dtype(args.precision)
+
+ model.train()
+ torch.autograd.set_detect_anomaly(True)
+
+ if args.distill:
+ dist_model.eval()
+
+ data['train'].set_epoch(epoch) # set epoch in process safe manner via sampler or shared_epoch
+ dataloader = data['train'].dataloader
+ num_batches_per_epoch = dataloader.num_batches // args.accum_freq
+ sample_digits = math.ceil(math.log(dataloader.num_samples + 1, 10))
+
+ if args.accum_freq > 1:
+ accum_images, accum_texts, accum_features = [], [], {}
+
+ losses_m = {}
+ batch_time_m = AverageMeter()
+ data_time_m = AverageMeter()
+ end = time.time()
+ for i, batch in enumerate(dataloader):
+ i_accum = i // args.accum_freq
+ step = num_batches_per_epoch * epoch + i_accum
+
+ if not args.skip_scheduler:
+ scheduler(step)
+
+ images, texts, concentration, Time, compound_embedding = batch
+ images = images.to(device=device, dtype=input_dtype, non_blocking=True)
+ texts = texts.to(device=device, non_blocking=True)
+ concentration = concentration.to(device=device, dtype=input_dtype, non_blocking=True)
+ Time = Time.to(device=device, dtype=input_dtype, non_blocking=True)
+ compound_embedding = compound_embedding.to(device=device, dtype=input_dtype, non_blocking=True)
+
+ data_time_m.update(time.time() - end)
+ optimizer.zero_grad()
+
+ if args.accum_freq == 1:
+ with autocast():
+ model_out = model(images, texts, concentration, Time, compound_embedding)
+ logit_scale = model_out["logit_scale"]
+ if args.distill:
+ with torch.no_grad():
+ dist_model_out = dist_model(images, texts)
+ model_out.update({f'dist_{k}': v for k, v in dist_model_out.items()})
+ losses = loss(**model_out, output_dict=True)
+
+ total_loss = sum(losses.values())
+ losses["loss"] = total_loss
+
+ backward(total_loss, scaler)
+ else:
+ # First, cache the features without any gradient tracking.
+ with torch.no_grad():
+ with autocast():
+ model_out = model(images, texts, concentration, Time, compound_embedding)
+
+ for f in ("logit_scale", "logit_bias"):
+ model_out.pop(f, None)
+
+ for key, val in model_out.items():
+ if key in accum_features:
+ accum_features[key].append(val)
+ else:
+ accum_features[key] = [val]
+
+ accum_images.append(images)
+ accum_texts.append(texts)
+
+ # If (i + 1) % accum_freq is not zero, move on to the next batch.
+ if ((i + 1) % args.accum_freq) > 0:
+ # FIXME this makes data time logging unreliable when accumulating
+ continue
+
+ # Now, ready to take gradients for the last accum_freq batches.
+ # Re-do the forward pass for those batches, and use the cached features from the other batches as negatives.
+ # Call backwards each time, but only step optimizer at the end.
+ optimizer.zero_grad()
+ for j in range(args.accum_freq):
+ images = accum_images[j]
+ texts = accum_texts[j]
+ with autocast():
+ model_out = model(images, texts, concentration, Time, compound_embedding)
+
+ inputs_no_accum = {}
+ inputs_no_accum["logit_scale"] = logit_scale = model_out.pop("logit_scale")
+ if "logit_bias" in model_out:
+ inputs_no_accum["logit_bias"] = model_out.pop("logit_bias")
+
+ inputs = {}
+ for key, val in accum_features.items():
+ accumulated = accum_features[key]
+ inputs[key] = torch.cat(accumulated[:j] + [model_out[key]] + accumulated[j + 1:])
+
+ losses = loss(**inputs, **inputs_no_accum, output_dict=True)
+ del inputs
+ del inputs_no_accum
+ total_loss = sum(losses.values())
+ losses["loss"] = total_loss
+
+ backward(total_loss, scaler)
+
+ if scaler is not None:
+ if args.horovod:
+ optimizer.synchronize()
+ scaler.unscale_(optimizer)
+ if args.grad_clip_norm is not None:
+ torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip_norm, norm_type=2.0)
+ with optimizer.skip_synchronize():
+ scaler.step(optimizer)
+ else:
+ if args.grad_clip_norm is not None:
+ scaler.unscale_(optimizer)
+ torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip_norm, norm_type=2.0)
+ scaler.step(optimizer)
+ scaler.update()
+ else:
+ if args.grad_clip_norm is not None:
+ torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip_norm, norm_type=2.0)
+ optimizer.step()
+
+ # reset gradient accum, if enabled
+ if args.accum_freq > 1:
+ accum_images, accum_texts, accum_features = [], [], {}
+
+ # Note: we clamp to 4.6052 = ln(100), as in the original paper.
+ with torch.no_grad():
+ unwrap_model(model).logit_scale.clamp_(0, math.log(100))
+
+ batch_time_m.update(time.time() - end)
+ end = time.time()
+ batch_count = i_accum + 1
+ if is_master(args) and (i_accum % args.log_every_n_steps == 0 or batch_count == num_batches_per_epoch):
+ batch_size = len(images)
+ num_samples = batch_count * batch_size * args.accum_freq * args.world_size
+ samples_per_epoch = dataloader.num_samples
+ percent_complete = 100.0 * batch_count / num_batches_per_epoch
+
+ # NOTE loss is coarsely sampled, just master node and per log update
+ for key, val in losses.items():
+ if key not in losses_m:
+ losses_m[key] = AverageMeter()
+ losses_m[key].update(val.item(), batch_size)
+
+ logit_scale_scalar = logit_scale.item()
+ loss_log = " ".join(
+ [
+ f"{loss_name.capitalize()}: {loss_m.val:#.5g} ({loss_m.avg:#.5g})"
+ for loss_name, loss_m in losses_m.items()
+ ]
+ )
+ samples_per_second = args.accum_freq * args.batch_size * args.world_size / batch_time_m.val
+ samples_per_second_per_gpu = args.accum_freq * args.batch_size / batch_time_m.val
+ logging.info(
+ f"Train Epoch: {epoch} [{num_samples:>{sample_digits}}/{samples_per_epoch} ({percent_complete:.0f}%)] "
+ f"Data (t): {data_time_m.avg:.3f} "
+ f"Batch (t): {batch_time_m.avg:.3f}, {samples_per_second:#g}/s, {samples_per_second_per_gpu:#g}/s/gpu "
+ f"LR: {optimizer.param_groups[0]['lr']:5f} "
+ f"Logit Scale: {logit_scale_scalar:.3f} " + loss_log
+ )
+
+ # Save train loss / etc. Using non avg meter values as loggers have their own smoothing
+ log_data = {
+ "data_time": data_time_m.val,
+ "batch_time": batch_time_m.val,
+ "samples_per_second": samples_per_second,
+ "samples_per_second_per_gpu": samples_per_second_per_gpu,
+ "scale": logit_scale_scalar,
+ "lr": optimizer.param_groups[0]["lr"]
+ }
+ log_data.update({name:val.val for name,val in losses_m.items()})
+
+ log_data = {"train/" + name: val for name, val in log_data.items()}
+
+ if tb_writer is not None:
+ for name, val in log_data.items():
+ tb_writer.add_scalar(name, val, step)
+
+ if args.wandb:
+ assert wandb is not None, 'Please install wandb.'
+ log_data['step'] = step # for backwards compatibility
+ wandb.log(log_data, step=step)
+
+ # resetting batch / data time meters per log window
+ batch_time_m.reset()
+ data_time_m.reset()
+ # end for
+
+
+def evaluate(model, data, epoch, args, tb_writer=None, tokenizer=None):
+ metrics = {}
+ if not is_master(args):
+ return metrics
+ device = torch.device(args.device)
+ model.eval()
+
+ zero_shot_metrics = zero_shot_eval(model, data, epoch, args, tokenizer=tokenizer)
+ metrics.update(zero_shot_metrics)
+
+ autocast = get_autocast(args.precision, device_type=device.type)
+ input_dtype = get_input_dtype(args.precision)
+
+ if 'val' in data and (args.val_frequency and ((epoch % args.val_frequency) == 0 or epoch == args.epochs)):
+ dataloader = data['val'].dataloader
+ num_samples = 0
+ samples_per_val = dataloader.num_samples
+
+ # FIXME this does not scale past small eval datasets
+ # all_image_features @ all_text_features will blow up memory and compute very quickly
+ cumulative_loss = 0.0
+ cumulative_gen_loss = 0.0
+ all_image_features, all_text_features = [], []
+ with torch.inference_mode():
+ for i, batch in enumerate(dataloader):
+ images, texts, concentration, Time, compound_embedding = batch
+ images = images.to(device=device, dtype=input_dtype, non_blocking=True)
+ texts = texts.to(device=device, non_blocking=True)
+ concentration = concentration.to(device=device, dtype=input_dtype, non_blocking=True)
+ Time = Time.to(device=device, dtype=input_dtype, non_blocking=True)
+ compound_embedding = compound_embedding.to(device=device, dtype=input_dtype, non_blocking=True)
+
+ with autocast():
+ model_out = model(images, texts, concentration, Time, compound_embedding)
+ image_features = model_out["image_features"]
+ text_features = model_out["text_features"]
+ logit_scale = model_out["logit_scale"]
+ # features are accumulated in CPU tensors, otherwise GPU memory exhausted quickly
+ # however, system RAM is easily exceeded and compute time becomes problematic
+ all_image_features.append(image_features.cpu())
+ all_text_features.append(text_features.cpu())
+ logit_scale = logit_scale.mean()
+ logits_per_image = logit_scale * image_features @ text_features.t()
+ logits_per_text = logits_per_image.t()
+
+ batch_size = images.shape[0]
+ labels = torch.arange(batch_size, device=device).long()
+ total_loss = (
+ F.cross_entropy(logits_per_image, labels) +
+ F.cross_entropy(logits_per_text, labels)
+ ) / 2
+
+ gen_loss = maybe_compute_generative_loss(model_out)
+
+ cumulative_loss += total_loss * batch_size
+ num_samples += batch_size
+ if is_master(args) and (i % 100) == 0:
+ logging.info(
+ f"Eval Epoch: {epoch} [{num_samples} / {samples_per_val}]\t"
+ f"Clip Loss: {cumulative_loss / num_samples:.6f}\t")
+
+ if gen_loss is not None:
+ cumulative_gen_loss += gen_loss * batch_size
+ logging.info(
+ f"Generative Loss: {cumulative_gen_loss / num_samples:.6f}\t")
+
+ val_metrics = get_clip_metrics(
+ image_features=torch.cat(all_image_features),
+ text_features=torch.cat(all_text_features),
+ logit_scale=logit_scale.cpu(),
+ )
+ loss = cumulative_loss / num_samples
+ metrics.update(
+ {**val_metrics, "clip_val_loss": loss.item(), "epoch": epoch, "num_samples": num_samples}
+ )
+ if gen_loss is not None:
+ gen_loss = cumulative_gen_loss / num_samples
+ metrics.update({"val_generative_loss": gen_loss.item()})
+
+ if not metrics:
+ return metrics
+
+ logging.info(
+ f"Eval Epoch: {epoch} "
+ + "\t".join([f"{k}: {round(v, 4):.4f}" for k, v in metrics.items()])
+ )
+
+ log_data = {"val/" + name: val for name, val in metrics.items()}
+
+ if args.save_logs:
+ if tb_writer is not None:
+ for name, val in log_data.items():
+ tb_writer.add_scalar(name, val, epoch)
+
+ with open(os.path.join(args.checkpoint_path, "results.jsonl"), "a+") as f:
+ f.write(json.dumps(metrics))
+ f.write("\n")
+
+ if args.wandb:
+ assert wandb is not None, 'Please install wandb.'
+ if 'train' in data:
+ dataloader = data['train'].dataloader
+ num_batches_per_epoch = dataloader.num_batches // args.accum_freq
+ step = num_batches_per_epoch * epoch
+ else:
+ step = None
+ log_data['epoch'] = epoch
+ wandb.log(log_data, step=step)
+
+ return metrics
+
+
+def get_clip_metrics(image_features, text_features, logit_scale):
+ metrics = {}
+ logits_per_image = (logit_scale * image_features @ text_features.t()).detach().cpu()
+ logits_per_text = logits_per_image.t().detach().cpu()
+
+ logits = {"image_to_text": logits_per_image, "text_to_image": logits_per_text}
+ ground_truth = torch.arange(len(text_features)).view(-1, 1)
+
+ for name, logit in logits.items():
+ ranking = torch.argsort(logit, descending=True)
+ preds = torch.where(ranking == ground_truth)[1]
+ preds = preds.detach().cpu().numpy()
+ metrics[f"{name}_mean_rank"] = preds.mean() + 1
+ metrics[f"{name}_median_rank"] = np.floor(np.median(preds)) + 1
+ for k in [1, 5, 10]:
+ metrics[f"{name}_R@{k}"] = np.mean(preds < k)
+
+ return metrics
+
+
+def maybe_compute_generative_loss(model_out):
+ if "logits" in model_out and "labels" in model_out:
+ token_logits = model_out["logits"]
+ token_labels = model_out["labels"]
+ return F.cross_entropy(token_logits.permute(0, 2, 1), token_labels)
diff --git a/src/open_clip_train/zero_shot.py b/src/open_clip_train/zero_shot.py
new file mode 100644
index 0000000000000000000000000000000000000000..21241536528bef3bcfb6b6c61afe7e030be0a3fe
--- /dev/null
+++ b/src/open_clip_train/zero_shot.py
@@ -0,0 +1,86 @@
+import logging
+
+import torch
+from tqdm import tqdm
+
+from open_clip import get_input_dtype, get_tokenizer, build_zero_shot_classifier, \
+ IMAGENET_CLASSNAMES, OPENAI_IMAGENET_TEMPLATES
+from open_clip_train.precision import get_autocast
+
+
+def accuracy(output, target, topk=(1,)):
+ pred = output.topk(max(topk), 1, True, True)[1].t()
+ correct = pred.eq(target.view(1, -1).expand_as(pred))
+ return [float(correct[:k].reshape(-1).float().sum(0, keepdim=True).cpu().numpy()) for k in topk]
+
+
+def run(model, classifier, dataloader, args):
+ device = torch.device(args.device)
+ autocast = get_autocast(args.precision, device_type=device.type)
+ input_dtype = get_input_dtype(args.precision)
+
+ with torch.inference_mode():
+ top1, top5, n = 0., 0., 0.
+ for images, target in tqdm(dataloader, unit_scale=args.batch_size):
+ images = images.to(device=device, dtype=input_dtype)
+ target = target.to(device)
+
+ with autocast():
+ # predict
+ output = model(image=images)
+ image_features = output['image_features'] if isinstance(output, dict) else output[0]
+ logits = 100. * image_features @ classifier
+
+ # measure accuracy
+ acc1, acc5 = accuracy(logits, target, topk=(1, 5))
+ top1 += acc1
+ top5 += acc5
+ n += images.size(0)
+
+ top1 = (top1 / n)
+ top5 = (top5 / n)
+ return top1, top5
+
+
+def zero_shot_eval(model, data, epoch, args, tokenizer=None):
+ if 'imagenet-val' not in data and 'imagenet-v2' not in data:
+ return {}
+ if args.zeroshot_frequency == 0:
+ return {}
+ if (epoch % args.zeroshot_frequency) != 0 and epoch != args.epochs:
+ return {}
+ if args.distributed and not args.horovod:
+ model = model.module
+
+ logging.info('Starting zero-shot imagenet.')
+ if tokenizer is None:
+ tokenizer = get_tokenizer(args.model)
+
+ logging.info('Building zero-shot classifier')
+ device = torch.device(args.device)
+ autocast = get_autocast(args.precision, device_type=device.type)
+ with autocast():
+ classifier = build_zero_shot_classifier(
+ model,
+ tokenizer=tokenizer,
+ classnames=IMAGENET_CLASSNAMES,
+ templates=OPENAI_IMAGENET_TEMPLATES,
+ num_classes_per_batch=10,
+ device=device,
+ use_tqdm=True,
+ )
+
+ logging.info('Using classifier')
+ results = {}
+ if 'imagenet-val' in data:
+ top1, top5 = run(model, classifier, data['imagenet-val'].dataloader, args)
+ results['imagenet-zeroshot-val-top1'] = top1
+ results['imagenet-zeroshot-val-top5'] = top5
+ if 'imagenet-v2' in data:
+ top1, top5 = run(model, classifier, data['imagenet-v2'].dataloader, args)
+ results['imagenetv2-zeroshot-val-top1'] = top1
+ results['imagenetv2-zeroshot-val-top5'] = top5
+
+ logging.info('Finished zero-shot imagenet.')
+
+ return results
diff --git a/tests/test_download_pretrained.py b/tests/test_download_pretrained.py
new file mode 100644
index 0000000000000000000000000000000000000000..6340918ed5b7c56fdbbfb84e2bcb26ccf662c8b5
--- /dev/null
+++ b/tests/test_download_pretrained.py
@@ -0,0 +1,111 @@
+import requests
+import torch
+from PIL import Image
+import hashlib
+import tempfile
+import unittest
+from io import BytesIO
+from pathlib import Path
+from unittest.mock import patch
+
+from urllib3 import HTTPResponse
+from urllib3._collections import HTTPHeaderDict
+
+import open_clip
+from open_clip.pretrained import download_pretrained_from_url
+
+
+class DownloadPretrainedTests(unittest.TestCase):
+
+ def create_response(self, data, status_code=200, content_type='application/octet-stream'):
+ fp = BytesIO(data)
+ headers = HTTPHeaderDict({
+ 'Content-Type': content_type,
+ 'Content-Length': str(len(data))
+ })
+ raw = HTTPResponse(fp, preload_content=False, headers=headers, status=status_code)
+ return raw
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_openaipublic(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()
+ urllib.request.urlopen.return_value = self.create_response(file_contents)
+ with tempfile.TemporaryDirectory() as root:
+ url = f'https://openaipublic.azureedge.net/clip/models/{expected_hash}/RN50.pt'
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_called_once()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_openaipublic_corrupted(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()
+ urllib.request.urlopen.return_value = self.create_response(b'corrupted pretrained model')
+ with tempfile.TemporaryDirectory() as root:
+ url = f'https://openaipublic.azureedge.net/clip/models/{expected_hash}/RN50.pt'
+ with self.assertRaisesRegex(RuntimeError, r'checksum does not not match'):
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_called_once()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_openaipublic_valid_cache(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()
+ urllib.request.urlopen.return_value = self.create_response(file_contents)
+ with tempfile.TemporaryDirectory() as root:
+ local_file = Path(root) / 'RN50.pt'
+ local_file.write_bytes(file_contents)
+ url = f'https://openaipublic.azureedge.net/clip/models/{expected_hash}/RN50.pt'
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_not_called()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_openaipublic_corrupted_cache(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()
+ urllib.request.urlopen.return_value = self.create_response(file_contents)
+ with tempfile.TemporaryDirectory() as root:
+ local_file = Path(root) / 'RN50.pt'
+ local_file.write_bytes(b'corrupted pretrained model')
+ url = f'https://openaipublic.azureedge.net/clip/models/{expected_hash}/RN50.pt'
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_called_once()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_mlfoundations(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()[:8]
+ urllib.request.urlopen.return_value = self.create_response(file_contents)
+ with tempfile.TemporaryDirectory() as root:
+ url = f'https://github.com/mlfoundations/download/v0.2-weights/rn50-quickgelu-{expected_hash}.pt'
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_called_once()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_url_from_mlfoundations_corrupted(self, urllib):
+ file_contents = b'pretrained model weights'
+ expected_hash = hashlib.sha256(file_contents).hexdigest()[:8]
+ urllib.request.urlopen.return_value = self.create_response(b'corrupted pretrained model')
+ with tempfile.TemporaryDirectory() as root:
+ url = f'https://github.com/mlfoundations/download/v0.2-weights/rn50-quickgelu-{expected_hash}.pt'
+ with self.assertRaisesRegex(RuntimeError, r'checksum does not not match'):
+ download_pretrained_from_url(url, root)
+ urllib.request.urlopen.assert_called_once()
+
+ @patch('open_clip.pretrained.urllib')
+ def test_download_pretrained_from_hfh(self, urllib):
+ model, _, preprocess = open_clip.create_model_and_transforms('hf-hub:hf-internal-testing/tiny-open-clip-model')
+ tokenizer = open_clip.get_tokenizer('hf-hub:hf-internal-testing/tiny-open-clip-model')
+ img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+ image = preprocess(Image.open(requests.get(img_url, stream=True).raw)).unsqueeze(0)
+ text = tokenizer(["a diagram", "a dog", "a cat"])
+
+ with torch.no_grad():
+ image_features = model.encode_image(image)
+ text_features = model.encode_text(text)
+ image_features /= image_features.norm(dim=-1, keepdim=True)
+ text_features /= text_features.norm(dim=-1, keepdim=True)
+
+ text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
+
+ self.assertTrue(torch.allclose(text_probs, torch.tensor([[0.0597, 0.6349, 0.3053]]), 1e-3))
diff --git a/tests/test_hf_model.py b/tests/test_hf_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..6307b651adb1e5d47231921591dfd74fbe10e824
--- /dev/null
+++ b/tests/test_hf_model.py
@@ -0,0 +1,30 @@
+import pytest
+
+import torch
+from open_clip.hf_model import _POOLERS, HFTextEncoder
+from transformers import AutoConfig
+from transformers.modeling_outputs import BaseModelOutput
+
+# test poolers
+def test_poolers():
+ bs, sl, d = 2, 10, 5
+ h = torch.arange(sl).repeat(bs).reshape(bs, sl)[..., None] * torch.linspace(0.2, 1., d)
+ mask = torch.ones(bs, sl, dtype=torch.bool)
+ mask[:2, 6:] = False
+ x = BaseModelOutput(h)
+ for name, cls in _POOLERS.items():
+ pooler = cls()
+ res = pooler(x, mask)
+ assert res.shape == (bs, d), f"{name} returned wrong shape"
+
+# test HFTextEncoder
+@pytest.mark.parametrize("model_id", ["arampacha/roberta-tiny", "roberta-base", "xlm-roberta-base", "google/mt5-base"])
+def test_pretrained_text_encoder(model_id):
+ bs, sl, d = 2, 10, 64
+ cfg = AutoConfig.from_pretrained(model_id)
+ model = HFTextEncoder(model_id, d, proj_type='linear')
+ x = torch.randint(0, cfg.vocab_size, (bs, sl))
+ with torch.no_grad():
+ emb = model(x)
+
+ assert emb.shape == (bs, d)
diff --git a/tests/test_inference.py b/tests/test_inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..dca8dc44c49a5513d047924122a190898dad991d
--- /dev/null
+++ b/tests/test_inference.py
@@ -0,0 +1,133 @@
+
+import os
+import pytest
+import torch
+import open_clip
+import util_test
+
+os.environ['CUDA_VISIBLE_DEVICES'] = ''
+
+if hasattr(torch._C, '_jit_set_profiling_executor'):
+ # legacy executor is too slow to compile large models for unit tests
+ # no need for the fusion performance here
+ torch._C._jit_set_profiling_executor(True)
+ torch._C._jit_set_profiling_mode(False)
+
+models_to_test = set(open_clip.list_models())
+
+# testing excemptions
+models_to_test = models_to_test.difference({
+ # not available with timm yet
+ # see https://github.com/mlfoundations/open_clip/issues/219
+ 'convnext_xlarge',
+ 'convnext_xxlarge',
+ 'convnext_xxlarge_320',
+ 'vit_medium_patch16_gap_256',
+ # exceeds GH runner memory limit
+ 'ViT-bigG-14',
+ 'ViT-e-14',
+ 'mt5-xl-ViT-H-14',
+ 'coca_base',
+ 'coca_ViT-B-32',
+ 'coca_roberta-ViT-B-32'
+})
+
+if 'OPEN_CLIP_TEST_REG_MODELS' in os.environ:
+ external_model_list = os.environ['OPEN_CLIP_TEST_REG_MODELS']
+ with open(external_model_list, 'r') as f:
+ models_to_test = set(f.read().splitlines()).intersection(models_to_test)
+ print(f"Selected models from {external_model_list}: {models_to_test}")
+
+# TODO: add "coca_ViT-B-32" onece https://github.com/pytorch/pytorch/issues/92073 gets fixed
+models_to_test = list(models_to_test)
+models_to_test.sort()
+models_to_test = [(model_name, False) for model_name in models_to_test]
+
+models_to_jit_test = {"ViT-B-32"}
+models_to_jit_test = list(models_to_jit_test)
+models_to_jit_test = [(model_name, True) for model_name in models_to_jit_test]
+models_to_test_fully = models_to_test + models_to_jit_test
+
+
+@pytest.mark.regression_test
+@pytest.mark.parametrize("model_name,jit", models_to_test_fully)
+def test_inference_with_data(
+ model_name,
+ jit,
+ pretrained = None,
+ pretrained_hf = False,
+ precision = 'fp32',
+ force_quick_gelu = False,
+):
+ util_test.seed_all()
+ model, _, preprocess_val = open_clip.create_model_and_transforms(
+ model_name,
+ pretrained = pretrained,
+ precision = precision,
+ jit = jit,
+ force_quick_gelu = force_quick_gelu,
+ pretrained_hf = pretrained_hf
+ )
+ model_id = f'{model_name}_{pretrained or pretrained_hf}_{precision}'
+ input_dir, output_dir = util_test.get_data_dirs()
+ # text
+ input_text_path = os.path.join(input_dir, 'random_text.pt')
+ gt_text_path = os.path.join(output_dir, f'{model_id}_random_text.pt')
+ if not os.path.isfile(input_text_path):
+ pytest.skip(reason = f"missing test data, expected at {input_text_path}")
+ if not os.path.isfile(gt_text_path):
+ pytest.skip(reason = f"missing test data, expected at {gt_text_path}")
+ input_text = torch.load(input_text_path)
+ gt_text = torch.load(gt_text_path)
+ y_text = util_test.inference_text(model, model_name, input_text)
+ assert (y_text == gt_text).all(), f"text output differs @ {input_text_path}"
+ # image
+ image_size = model.visual.image_size
+ if not isinstance(image_size, tuple):
+ image_size = (image_size, image_size)
+ input_image_path = os.path.join(input_dir, f'random_image_{image_size[0]}_{image_size[1]}.pt')
+ gt_image_path = os.path.join(output_dir, f'{model_id}_random_image.pt')
+ if not os.path.isfile(input_image_path):
+ pytest.skip(reason = f"missing test data, expected at {input_image_path}")
+ if not os.path.isfile(gt_image_path):
+ pytest.skip(reason = f"missing test data, expected at {gt_image_path}")
+ input_image = torch.load(input_image_path)
+ gt_image = torch.load(gt_image_path)
+ y_image = util_test.inference_image(model, preprocess_val, input_image)
+ assert (y_image == gt_image).all(), f"image output differs @ {input_image_path}"
+
+ if not jit:
+ model.eval()
+ model_out = util_test.forward_model(model, model_name, preprocess_val, input_image, input_text)
+ if type(model) not in [open_clip.CLIP, open_clip.CustomTextCLIP]:
+ assert type(model_out) == dict
+ else:
+ model.output_dict = True
+ model_out_dict = util_test.forward_model(model, model_name, preprocess_val, input_image, input_text)
+ assert (model_out_dict["image_features"] == model_out[0]).all()
+ assert (model_out_dict["text_features"] == model_out[1]).all()
+ assert (model_out_dict["logit_scale"] == model_out[2]).all()
+ model.output_dict = None
+ else:
+ model, _, preprocess_val = open_clip.create_model_and_transforms(
+ model_name,
+ pretrained = pretrained,
+ precision = precision,
+ jit = False,
+ force_quick_gelu = force_quick_gelu,
+ pretrained_hf = pretrained_hf
+ )
+
+ test_model = util_test.TestWrapper(model, model_name, output_dict=False)
+ test_model = torch.jit.script(test_model)
+ model_out = util_test.forward_model(test_model, model_name, preprocess_val, input_image, input_text)
+ assert model_out["test_output"].shape[-1] == 2
+
+ test_model = util_test.TestWrapper(model, model_name, output_dict=True)
+ test_model = torch.jit.script(test_model)
+ model_out = util_test.forward_model(test_model, model_name, preprocess_val, input_image, input_text)
+ assert model_out["test_output"].shape[-1] == 2
+
+
+
+
diff --git a/tests/test_inference_simple.py b/tests/test_inference_simple.py
new file mode 100644
index 0000000000000000000000000000000000000000..2513052bef0d360cdd91d51c2547509111cbb442
--- /dev/null
+++ b/tests/test_inference_simple.py
@@ -0,0 +1,51 @@
+import torch
+from PIL import Image
+from open_clip.factory import get_tokenizer
+import pytest
+import open_clip
+import os
+os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+if hasattr(torch._C, '_jit_set_profiling_executor'):
+ # legacy executor is too slow to compile large models for unit tests
+ # no need for the fusion performance here
+ torch._C._jit_set_profiling_executor(True)
+ torch._C._jit_set_profiling_mode(False)
+
+
+test_simple_models = [
+ # model, pretrained, jit, force_custom_text
+ ("ViT-B-32", "laion2b_s34b_b79k", False, False),
+ ("ViT-B-32", "laion2b_s34b_b79k", True, False),
+ ("ViT-B-32", "laion2b_s34b_b79k", True, True),
+ ("roberta-ViT-B-32", "laion2b_s12b_b32k", False, False),
+]
+
+
+@pytest.mark.parametrize("model_type,pretrained,jit,force_custom_text", test_simple_models)
+def test_inference_simple(
+ model_type,
+ pretrained,
+ jit,
+ force_custom_text,
+):
+ model, _, preprocess = open_clip.create_model_and_transforms(
+ model_type,
+ pretrained=pretrained,
+ jit=jit,
+ force_custom_text=force_custom_text,
+ )
+ tokenizer = get_tokenizer(model_type)
+
+ current_dir = os.path.dirname(os.path.realpath(__file__))
+
+ image = preprocess(Image.open(current_dir + "/../docs/CLIP.png")).unsqueeze(0)
+ text = tokenizer(["a diagram", "a dog", "a cat"])
+
+ with torch.no_grad():
+ image_features = model.encode_image(image)
+ text_features = model.encode_text(text)
+
+ text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
+
+ assert torch.allclose(text_probs.cpu()[0], torch.tensor([1.0, 0.0, 0.0]))
diff --git a/tests/test_num_shards.py b/tests/test_num_shards.py
new file mode 100644
index 0000000000000000000000000000000000000000..5210c144618a5d9e29f78e4e0e50af0cf9546651
--- /dev/null
+++ b/tests/test_num_shards.py
@@ -0,0 +1,20 @@
+import pytest
+
+from open_clip_train.data import get_dataset_size
+
+@pytest.mark.parametrize(
+ "shards,expected_size",
+ [
+ ('/path/to/shard.tar', 1),
+ ('/path/to/shard_{000..000}.tar', 1),
+ ('/path/to/shard_{000..009}.tar', 10),
+ ('/path/to/shard_{000..009}_{000..009}.tar', 100),
+ ('/path/to/shard.tar::/path/to/other_shard_{000..009}.tar', 11),
+ ('/path/to/shard_{000..009}.tar::/path/to/other_shard_{000..009}.tar', 20),
+ (['/path/to/shard.tar'], 1),
+ (['/path/to/shard.tar', '/path/to/other_shard.tar'], 2),
+ ]
+)
+def test_num_shards(shards, expected_size):
+ _, size = get_dataset_size(shards)
+ assert size == expected_size, f'Expected {expected_size} for {shards} but found {size} instead.'
diff --git a/tests/test_training_simple.py b/tests/test_training_simple.py
new file mode 100644
index 0000000000000000000000000000000000000000..58b33a3c16846250353973b36d362824bcad99ad
--- /dev/null
+++ b/tests/test_training_simple.py
@@ -0,0 +1,103 @@
+
+import os
+import sys
+import pytest
+import torch
+from open_clip_train.main import main
+
+os.environ["CUDA_VISIBLE_DEVICES"] = ""
+
+if hasattr(torch._C, '_jit_set_profiling_executor'):
+ # legacy executor is too slow to compile large models for unit tests
+ # no need for the fusion performance here
+ torch._C._jit_set_profiling_executor(True)
+ torch._C._jit_set_profiling_mode(False)
+
+@pytest.mark.skipif(sys.platform.startswith('darwin'), reason="macos pickle bug with locals")
+def test_training():
+ main([
+ '--save-frequency', '1',
+ '--zeroshot-frequency', '1',
+ '--dataset-type', "synthetic",
+ '--train-num-samples', '16',
+ '--warmup', '1',
+ '--batch-size', '4',
+ '--lr', '1e-3',
+ '--wd', '0.1',
+ '--epochs', '1',
+ '--workers', '2',
+ '--model', 'RN50'
+ ])
+
+@pytest.mark.skipif(sys.platform.startswith('darwin'), reason="macos pickle bug with locals")
+def test_training_coca():
+ main([
+ '--save-frequency', '1',
+ '--zeroshot-frequency', '1',
+ '--dataset-type', "synthetic",
+ '--train-num-samples', '16',
+ '--warmup', '1',
+ '--batch-size', '4',
+ '--lr', '1e-3',
+ '--wd', '0.1',
+ '--epochs', '1',
+ '--workers', '2',
+ '--model', 'coca_ViT-B-32'
+ ])
+
+@pytest.mark.skipif(sys.platform.startswith('darwin'), reason="macos pickle bug with locals")
+def test_training_mt5():
+ main([
+ '--save-frequency', '1',
+ '--zeroshot-frequency', '1',
+ '--dataset-type', "synthetic",
+ '--train-num-samples', '16',
+ '--warmup', '1',
+ '--batch-size', '4',
+ '--lr', '1e-3',
+ '--wd', '0.1',
+ '--epochs', '1',
+ '--workers', '2',
+ '--model', 'mt5-base-ViT-B-32',
+ '--lock-text',
+ '--lock-text-unlocked-layers', '2'
+ ])
+
+
+
+@pytest.mark.skipif(sys.platform.startswith('darwin'), reason="macos pickle bug with locals")
+def test_training_unfreezing_vit():
+ main([
+ '--save-frequency', '1',
+ '--zeroshot-frequency', '1',
+ '--dataset-type', "synthetic",
+ '--train-num-samples', '16',
+ '--warmup', '1',
+ '--batch-size', '4',
+ '--lr', '1e-3',
+ '--wd', '0.1',
+ '--epochs', '1',
+ '--workers', '2',
+ '--model', 'ViT-B-32',
+ '--lock-image',
+ '--lock-image-unlocked-groups', '5',
+ '--accum-freq', '2'
+ ])
+
+
+@pytest.mark.skipif(sys.platform.startswith('darwin'), reason="macos pickle bug with locals")
+def test_training_clip_with_jit():
+ main([
+ '--save-frequency', '1',
+ '--zeroshot-frequency', '1',
+ '--dataset-type', "synthetic",
+ '--train-num-samples', '16',
+ '--warmup', '1',
+ '--batch-size', '4',
+ '--lr', '1e-3',
+ '--wd', '0.1',
+ '--epochs', '1',
+ '--workers', '2',
+ '--model', 'ViT-B-32',
+ '--torchscript'
+ ])
diff --git a/tests/test_wds.py b/tests/test_wds.py
new file mode 100644
index 0000000000000000000000000000000000000000..a31039028a08221d7d965b09ce5cf4a36308339e
--- /dev/null
+++ b/tests/test_wds.py
@@ -0,0 +1,149 @@
+import os
+import pytest
+import util_test
+import collections
+import tarfile
+import io
+from PIL import Image
+
+from open_clip_train.data import get_wds_dataset
+from open_clip_train.params import parse_args
+from open_clip_train.main import random_seed
+
+TRAIN_NUM_SAMPLES = 10_000
+RTOL = 0.2
+
+# NOTE: we use two test tar files, which are created on the fly and saved to data/input.
+# 000.tar has 10 samples, and the captions are 000_0, 000_1, ..., 000_9
+# 001.tar has 5 samples, and the captions are 001_0, 001_1, ..., 001_4
+def build_inputs(test_name):
+ base_input_dir, _ = util_test.get_data_dirs()
+ input_dir = os.path.join(base_input_dir, test_name)
+ os.makedirs(input_dir, exist_ok=True)
+
+ def save_tar(idx, num_samples):
+ filename = os.path.join(input_dir, f'test_data_{idx:03d}.tar')
+ tar = tarfile.open(filename, 'w')
+
+ for sample_idx in range(num_samples):
+ # Image
+ image = Image.new('RGB', (32, 32))
+ info = tarfile.TarInfo(f'{sample_idx}.png')
+ bio = io.BytesIO()
+ image.save(bio, format='png')
+ size = bio.tell()
+ bio.seek(0)
+ info.size = size
+ tar.addfile(info, bio)
+
+ # Caption
+ info = tarfile.TarInfo(f'{sample_idx}.txt')
+ bio = io.BytesIO()
+ bio.write(f'{idx:03d}_{sample_idx}'.encode('utf-8'))
+ size = bio.tell()
+ bio.seek(0)
+ info.size = size
+ tar.addfile(info, bio)
+
+ tar.close()
+
+ save_tar(0, 10)
+ save_tar(1, 5)
+
+ return input_dir
+
+
+def build_params(input_shards, seed=0):
+ args = parse_args([])
+ args.train_data = input_shards
+ args.train_num_samples = TRAIN_NUM_SAMPLES
+ args.dataset_resampled = True
+ args.seed = seed
+ args.workers = 1
+ args.world_size = 1
+ args.batch_size = 1
+ random_seed(seed)
+
+ preprocess_img = lambda x: x
+ tokenizer = lambda x: [x.strip()]
+
+ return args, preprocess_img, tokenizer
+
+
+def get_dataloader(input_shards):
+ args, preprocess_img, tokenizer = build_params(input_shards)
+ dataset = get_wds_dataset(args, preprocess_img, is_train=True, tokenizer=tokenizer)
+ dataloader = dataset.dataloader
+ return dataloader
+
+
+def test_single_source():
+ """Test webdataset with a single tar file."""
+ input_dir = build_inputs('single_source')
+ input_shards = os.path.join(input_dir, 'test_data_000.tar')
+ dataloader = get_dataloader(input_shards)
+
+ counts = collections.defaultdict(int)
+ for sample in dataloader:
+ txts = sample[1]
+ for txt in txts:
+ counts[txt] += 1
+
+ for key, count in counts.items():
+ assert count == pytest.approx(TRAIN_NUM_SAMPLES / 10, RTOL)
+
+
+def test_two_sources():
+ """Test webdataset with a single two tar files."""
+ input_dir = build_inputs('two_sources')
+ input_shards = os.path.join(input_dir, 'test_data_{000..001}.tar')
+ dataloader = get_dataloader(input_shards)
+
+ counts = collections.defaultdict(int)
+ for sample in dataloader:
+ txts = sample[1]
+ for txt in txts:
+ counts[txt] += 1
+
+ for key, count in counts.items():
+ assert count == pytest.approx(TRAIN_NUM_SAMPLES / 15, RTOL), f'{key}, {count}'
+
+
+def test_two_sources_same_weights():
+ """Test webdataset with a two tar files, using --train-data-weights=1::1."""
+ input_dir = build_inputs('two_sources_same_weights')
+ input_shards = f"{os.path.join(input_dir, 'test_data_000.tar')}::{os.path.join(input_dir, 'test_data_001.tar')}"
+ args, preprocess_img, tokenizer = build_params(input_shards)
+ args.train_data_upsampling_factors = '1::1'
+ dataset = get_wds_dataset(args, preprocess_img, is_train=True, tokenizer=tokenizer)
+ dataloader = dataset.dataloader
+
+ counts = collections.defaultdict(int)
+ for sample in dataloader:
+ txts = sample[1]
+ for txt in txts:
+ counts[txt] += 1
+
+ for key, count in counts.items():
+ assert count == pytest.approx(TRAIN_NUM_SAMPLES / 15, RTOL), f'{key}, {count}'
+
+def test_two_sources_with_upsampling():
+ """Test webdataset with a two tar files with upsampling."""
+ input_dir = build_inputs('two_sources_with_upsampling')
+ input_shards = f"{os.path.join(input_dir, 'test_data_000.tar')}::{os.path.join(input_dir, 'test_data_001.tar')}"
+ args, preprocess_img, tokenizer = build_params(input_shards)
+ args.train_data_upsampling_factors = '1::2'
+ dataset = get_wds_dataset(args, preprocess_img, is_train=True, tokenizer=tokenizer)
+ dataloader = dataset.dataloader
+
+ counts = collections.defaultdict(int)
+ for sample in dataloader:
+ txts = sample[1]
+ for txt in txts:
+ counts[txt] += 1
+
+ for key, count in counts.items():
+ if key.startswith('000'):
+ assert count == pytest.approx(TRAIN_NUM_SAMPLES / 20, RTOL), f'{key}, {count}'
+ else:
+ assert count == pytest.approx(TRAIN_NUM_SAMPLES / 10, RTOL), f'{key}, {count}'
diff --git a/tests/util_test.py b/tests/util_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..53380ddb1c43a6ced91d573f5fc9922742b28e0b
--- /dev/null
+++ b/tests/util_test.py
@@ -0,0 +1,323 @@
+import os
+import random
+import numpy as np
+from PIL import Image
+import torch
+
+if __name__ != '__main__':
+ import open_clip
+
+os.environ['CUDA_VISIBLE_DEVICES'] = ''
+
+def seed_all(seed = 0):
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = False
+ torch.use_deterministic_algorithms(True, warn_only=False)
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+
+def inference_text(model, model_name, batches):
+ y = []
+ tokenizer = open_clip.get_tokenizer(model_name)
+ with torch.no_grad():
+ for x in batches:
+ x = tokenizer(x)
+ y.append(model.encode_text(x))
+ return torch.stack(y)
+
+def inference_image(model, preprocess_val, batches):
+ y = []
+ with torch.no_grad():
+ for x in batches:
+ x = torch.stack([preprocess_val(img) for img in x])
+ y.append(model.encode_image(x))
+ return torch.stack(y)
+
+def forward_model(model, model_name, preprocess_val, image_batch, text_batch):
+ y = []
+ tokenizer = open_clip.get_tokenizer(model_name)
+ with torch.no_grad():
+ for x_im, x_txt in zip(image_batch, text_batch):
+ x_im = torch.stack([preprocess_val(im) for im in x_im])
+ x_txt = tokenizer(x_txt)
+ y.append(model(x_im, x_txt))
+ if type(y[0]) == dict:
+ out = {}
+ for key in y[0].keys():
+ out[key] = torch.stack([batch_out[key] for batch_out in y])
+ else:
+ out = []
+ for i in range(len(y[0])):
+ out.append(torch.stack([batch_out[i] for batch_out in y]))
+ return out
+
+def random_image_batch(batch_size, size):
+ h, w = size
+ data = np.random.randint(255, size = (batch_size, h, w, 3), dtype = np.uint8)
+ return [ Image.fromarray(d) for d in data ]
+
+def random_text_batch(batch_size, min_length = 75, max_length = 75):
+ t = open_clip.tokenizer.SimpleTokenizer()
+ # every token decoded as string, exclude SOT and EOT, replace EOW with space
+ token_words = [
+ x[1].replace('', ' ')
+ for x in t.decoder.items()
+ if x[0] not in t.all_special_ids
+ ]
+ # strings of randomly chosen tokens
+ return [
+ ''.join(random.choices(
+ token_words,
+ k = random.randint(min_length, max_length)
+ ))
+ for _ in range(batch_size)
+ ]
+
+def create_random_text_data(
+ path,
+ min_length = 75,
+ max_length = 75,
+ batches = 1,
+ batch_size = 1
+):
+ text_batches = [
+ random_text_batch(batch_size, min_length, max_length)
+ for _ in range(batches)
+ ]
+ print(f"{path}")
+ torch.save(text_batches, path)
+
+def create_random_image_data(path, size, batches = 1, batch_size = 1):
+ image_batches = [
+ random_image_batch(batch_size, size)
+ for _ in range(batches)
+ ]
+ print(f"{path}")
+ torch.save(image_batches, path)
+
+def get_data_dirs(make_dir = True):
+ data_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'data')
+ input_dir = os.path.join(data_dir, 'input')
+ output_dir = os.path.join(data_dir, 'output')
+ if make_dir:
+ os.makedirs(input_dir, exist_ok = True)
+ os.makedirs(output_dir, exist_ok = True)
+ assert os.path.isdir(data_dir), f"data directory missing, expected at {input_dir}"
+ assert os.path.isdir(data_dir), f"data directory missing, expected at {output_dir}"
+ return input_dir, output_dir
+
+def create_test_data_for_model(
+ model_name,
+ pretrained = None,
+ precision = 'fp32',
+ jit = False,
+ pretrained_hf = False,
+ force_quick_gelu = False,
+ create_missing_input_data = True,
+ batches = 1,
+ batch_size = 1,
+ overwrite = False
+):
+ model_id = f'{model_name}_{pretrained or pretrained_hf}_{precision}'
+ input_dir, output_dir = get_data_dirs()
+ output_file_text = os.path.join(output_dir, f'{model_id}_random_text.pt')
+ output_file_image = os.path.join(output_dir, f'{model_id}_random_image.pt')
+ text_exists = os.path.exists(output_file_text)
+ image_exists = os.path.exists(output_file_image)
+ if not overwrite and text_exists and image_exists:
+ return
+ seed_all()
+ model, _, preprocess_val = open_clip.create_model_and_transforms(
+ model_name,
+ pretrained = pretrained,
+ precision = precision,
+ jit = jit,
+ force_quick_gelu = force_quick_gelu,
+ pretrained_hf = pretrained_hf
+ )
+ # text
+ if overwrite or not text_exists:
+ input_file_text = os.path.join(input_dir, 'random_text.pt')
+ if create_missing_input_data and not os.path.exists(input_file_text):
+ create_random_text_data(
+ input_file_text,
+ batches = batches,
+ batch_size = batch_size
+ )
+ assert os.path.isfile(input_file_text), f"missing input data, expected at {input_file_text}"
+ input_data_text = torch.load(input_file_text)
+ output_data_text = inference_text(model, model_name, input_data_text)
+ print(f"{output_file_text}")
+ torch.save(output_data_text, output_file_text)
+ # image
+ if overwrite or not image_exists:
+ size = model.visual.image_size
+ if not isinstance(size, tuple):
+ size = (size, size)
+ input_file_image = os.path.join(input_dir, f'random_image_{size[0]}_{size[1]}.pt')
+ if create_missing_input_data and not os.path.exists(input_file_image):
+ create_random_image_data(
+ input_file_image,
+ size,
+ batches = batches,
+ batch_size = batch_size
+ )
+ assert os.path.isfile(input_file_image), f"missing input data, expected at {input_file_image}"
+ input_data_image = torch.load(input_file_image)
+ output_data_image = inference_image(model, preprocess_val, input_data_image)
+ print(f"{output_file_image}")
+ torch.save(output_data_image, output_file_image)
+
+def create_test_data(
+ models,
+ batches = 1,
+ batch_size = 1,
+ overwrite = False
+):
+ models = list(set(models).difference({
+ # not available with timm
+ # see https://github.com/mlfoundations/open_clip/issues/219
+ 'timm-convnext_xlarge',
+ 'timm-vit_medium_patch16_gap_256'
+ }).intersection(open_clip.list_models()))
+ models.sort()
+ print(f"generating test data for:\n{models}")
+ for model_name in models:
+ print(model_name)
+ create_test_data_for_model(
+ model_name,
+ batches = batches,
+ batch_size = batch_size,
+ overwrite = overwrite
+ )
+ return models
+
+def _sytem_assert(string):
+ assert os.system(string) == 0
+
+class TestWrapper(torch.nn.Module):
+ output_dict: torch.jit.Final[bool]
+ def __init__(self, model, model_name, output_dict=True) -> None:
+ super().__init__()
+ self.model = model
+ self.output_dict = output_dict
+ if type(model) in [open_clip.CLIP, open_clip.CustomTextCLIP]:
+ self.model.output_dict = self.output_dict
+ config = open_clip.get_model_config(model_name)
+ self.head = torch.nn.Linear(config["embed_dim"], 2)
+
+ def forward(self, image, text):
+ x = self.model(image, text)
+ x = x['image_features'] if self.output_dict else x[0]
+ assert x is not None # remove Optional[], type refinement for torchscript
+ out = self.head(x)
+ return {"test_output": out}
+
+def main(args):
+ global open_clip
+ import importlib
+ import shutil
+ import subprocess
+ import argparse
+ parser = argparse.ArgumentParser(description = "Populate test data directory")
+ parser.add_argument(
+ '-a', '--all',
+ action = 'store_true',
+ help = "create test data for all models"
+ )
+ parser.add_argument(
+ '-m', '--model',
+ type = str,
+ default = [],
+ nargs = '+',
+ help = "model(s) to create test data for"
+ )
+ parser.add_argument(
+ '-f', '--model_list',
+ type = str,
+ help = "path to a text file containing a list of model names, one model per line"
+ )
+ parser.add_argument(
+ '-s', '--save_model_list',
+ type = str,
+ help = "path to save the list of models that data was generated for"
+ )
+ parser.add_argument(
+ '-g', '--git_revision',
+ type = str,
+ help = "git revision to generate test data for"
+ )
+ parser.add_argument(
+ '--overwrite',
+ action = 'store_true',
+ help = "overwrite existing output data"
+ )
+ parser.add_argument(
+ '-n', '--num_batches',
+ default = 1,
+ type = int,
+ help = "amount of data batches to create (default: 1)"
+ )
+ parser.add_argument(
+ '-b', '--batch_size',
+ default = 1,
+ type = int,
+ help = "test data batch size (default: 1)"
+ )
+ args = parser.parse_args(args)
+ model_list = []
+ if args.model_list is not None:
+ with open(args.model_list, 'r') as f:
+ model_list = f.read().splitlines()
+ if not args.all and len(args.model) < 1 and len(model_list) < 1:
+ print("error: at least one model name is required")
+ parser.print_help()
+ parser.exit(1)
+ if args.git_revision is not None:
+ stash_output = subprocess.check_output(['git', 'stash']).decode().splitlines()
+ has_stash = len(stash_output) > 0 and stash_output[0] != 'No local changes to save'
+ current_branch = subprocess.check_output(['git', 'branch', '--show-current'])
+ if len(current_branch) < 1:
+ # not on a branch -> detached head
+ current_branch = subprocess.check_output(['git', 'rev-parse', 'HEAD'])
+ current_branch = current_branch.splitlines()[0].decode()
+ try:
+ _sytem_assert(f'git checkout {args.git_revision}')
+ except AssertionError as e:
+ _sytem_assert(f'git checkout -f {current_branch}')
+ if has_stash:
+ os.system(f'git stash pop')
+ raise e
+ open_clip = importlib.import_module('open_clip')
+ models = open_clip.list_models() if args.all else args.model + model_list
+ try:
+ models = create_test_data(
+ models,
+ batches = args.num_batches,
+ batch_size = args.batch_size,
+ overwrite = args.overwrite
+ )
+ finally:
+ if args.git_revision is not None:
+ test_dir = os.path.join(os.path.dirname(__file__), 'data')
+ test_dir_ref = os.path.join(os.path.dirname(__file__), 'data_ref')
+ if os.path.exists(test_dir_ref):
+ shutil.rmtree(test_dir_ref, ignore_errors = True)
+ if os.path.exists(test_dir):
+ os.rename(test_dir, test_dir_ref)
+ _sytem_assert(f'git checkout {current_branch}')
+ if has_stash:
+ os.system(f'git stash pop')
+ os.rename(test_dir_ref, test_dir)
+ if args.save_model_list is not None:
+ print(f"Saving model list as {args.save_model_list}")
+ with open(args.save_model_list, 'w') as f:
+ for m in models:
+ print(m, file=f)
+
+
+if __name__ == '__main__':
+ import sys
+ main(sys.argv[1:])
+
diff --git a/train_openclip_B.sh b/train_openclip_B.sh
new file mode 100644
index 0000000000000000000000000000000000000000..cc642c315bdbe731eedbc2f815127871ff518c2e
--- /dev/null
+++ b/train_openclip_B.sh
@@ -0,0 +1,20 @@
+cd /workspace/data/20250505_paired_images
+
+PYTHONPATH=/workspace/src python -m open_clip_train.main \
+ --dataset-type jsonl \
+ --train-data /workspace/data/20250505_paired_images/MCF7_train.jsonl \
+ --val-data /workspace/data/20250505_paired_images/MCF7_val.jsonl \
+ --model ViT-B-16 \
+ --warmup 10000 \
+ --batch-size=50 \
+ --lr=1e-3 \
+ --wd=0.1 \
+ --epochs=50 \
+ --workers=4 \
+ --device cuda:1 \
+ --logs ./logs/ViT-B-16/ \
+ --log-every-n-steps 32 \
+ --save-frequency 1 \
+ --zeroshot-frequency 1 \
+ --report-to tensorboard
+
diff --git a/train_openclip_L.sh b/train_openclip_L.sh
new file mode 100644
index 0000000000000000000000000000000000000000..cb2d380a7527cff9d7a6c04d759b219dfa7261d9
--- /dev/null
+++ b/train_openclip_L.sh
@@ -0,0 +1,20 @@
+cd /workspace/data/20250505_paired_images
+
+PYTHONPATH=/workspace/src python -m open_clip_train.main \
+ --dataset-type jsonl \
+ --train-data /workspace/data/20250505_paired_images/MCF7_train.jsonl \
+ --val-data /workspace/data/20250505_paired_images/MCF7_val.jsonl \
+ --model ViT-L-16 \
+ --warmup 10000 \
+ --batch-size=8 \
+ --lr=1e-3 \
+ --wd=0.1 \
+ --epochs=50 \
+ --workers=4 \
+ --device cuda:0 \
+ --logs ./logs/ViT-L-16/ \
+ --log-every-n-steps 32 \
+ --save-frequency 1 \
+ --zeroshot-frequency 1 \
+ --report-to tensorboard
+