

Revision 3.3.1 model (#3)
Browse files- Upload folder using huggingface_hub (00f6bae95602cbd087854eb5f6ffc7783f87ad4f)
- README.md +15 -10
- adapter_config.json +2 -2
- adapter_model.safetensors +1 -1
- config.json +2 -3
- model-00009-of-00009.safetensors +2 -2
- model.safetensors.index.json +199 -1
README.md
CHANGED
|
@@ -6,25 +6,29 @@ base_model:
|
|
| 6 |
- ibm-granite/granite-3.3-8b-instruct
|
| 7 |
library_name: transformers
|
| 8 |
---
|
| 9 |
-
# Granite-speech-3.3-8b
|
| 10 |
|
| 11 |
**Model Summary:**
|
| 12 |
Granite-speech-3.3-8b is a compact and efficient speech-language model, specifically designed for automatic speech recognition (ASR) and automatic speech translation (AST). Granite-speech-3.3-8b uses a two-pass design, unlike integrated models that combine speech and language into a single pass. Initial calls to granite-speech-3.3-8b will transcribe audio files into text. To process the transcribed text using the underlying Granite language model, users must make a second call as each step must be explicitly initiated.
|
| 13 |
|
| 14 |
The model was trained on a collection of public corpora comprising diverse datasets for ASR and AST as well as synthetic datasets tailored to support the speech translation task. Granite-speech-3.3 was trained by modality aligning granite-3.3-8b-instruct (https://huggingface.co/ibm-granite/granite-3.3-8b-instruct) to speech on publicly available open source corpora containing audio inputs and text targets.
|
| 15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
We are currently investigating an issue with greedy decoding (```num_beams=1```); the model performs reliably with beam sizes > 1, which we recommend for all use cases.
|
| 17 |
Additionally, the model may occasionally hallucinate on very short audio inputs (<0.1s). These issues are under active investigation, and we will update guidance as fixes become available.
|
| 18 |
|
| 19 |
**Evaluations:**
|
| 20 |
|
| 21 |
-
We evaluated granite-speech-3.3-8b alongside other speech-language models (SLMs) in the less than 8b parameter range as well as dedicated ASR and AST systems on standard benchmarks. The evaluation spanned multiple public benchmarks, with particular emphasis on English ASR tasks while also including AST for En-X translation.
|
| 22 |
|
| 23 |
-
 Speech encoder:
|
| 307 |
only ASR corpora (see configuration below). In addition, our CTC encoder uses block-attention with 4-seconds audio blocks and self-conditioned CTC
|
| 308 |
from the middle layer.
|
| 309 |
|
| 310 |
| Configuration parameter | Value |
|
| 311 |
|-----------------|----------------------|
|
| 312 |
| Input dimension | 160 (80 logmels x 2) |
|
| 313 |
-
| Nb. of layers |
|
| 314 |
| Hidden dimension | 1024 |
|
| 315 |
| Nb. of attention heads | 8 |
|
| 316 |
| Attention head size | 128 |
|
|
@@ -340,7 +344,8 @@ below:
|
|
| 340 |
| Librispeech | ASR | 1000 | https://huggingface.co/datasets/openslr/librispeech_asr |
|
| 341 |
| VoxPopuli English | ASR | 500 | https://huggingface.co/datasets/facebook/voxpopuli |
|
| 342 |
| AMI | ASR | 100 | https://huggingface.co/datasets/edinburghcstr/ami |
|
| 343 |
-
| YODAS English | ASR | 10000 | https://huggingface.co/datasets/espnet/yodas |
|
|
|
|
| 344 |
| Switchboard English | ASR | 260 | https://catalog.ldc.upenn.edu/LDC97S62 |
|
| 345 |
| CallHome English | ASR | 18 | https://catalog.ldc.upenn.edu/LDC97T14 |
|
| 346 |
| Fisher | ASR | 2000 | https://catalog.ldc.upenn.edu/LDC2004S13 |
|
|
@@ -350,7 +355,7 @@ below:
|
|
| 350 |
|
| 351 |
**Infrastructure:**
|
| 352 |
We train Granite Speech using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable
|
| 353 |
-
and efficient infrastructure for training our models over thousands of GPUs. The training of this particular model was completed in
|
| 354 |
H100 GPUs.
|
| 355 |
|
| 356 |
**Ethical Considerations and Limitations:**
|
|
|
|
| 6 |
- ibm-granite/granite-3.3-8b-instruct
|
| 7 |
library_name: transformers
|
| 8 |
---
|
| 9 |
+
# Granite-speech-3.3-8b (revision 3.3.1)
|
| 10 |
|
| 11 |
**Model Summary:**
|
| 12 |
Granite-speech-3.3-8b is a compact and efficient speech-language model, specifically designed for automatic speech recognition (ASR) and automatic speech translation (AST). Granite-speech-3.3-8b uses a two-pass design, unlike integrated models that combine speech and language into a single pass. Initial calls to granite-speech-3.3-8b will transcribe audio files into text. To process the transcribed text using the underlying Granite language model, users must make a second call as each step must be explicitly initiated.
|
| 13 |
|
| 14 |
The model was trained on a collection of public corpora comprising diverse datasets for ASR and AST as well as synthetic datasets tailored to support the speech translation task. Granite-speech-3.3 was trained by modality aligning granite-3.3-8b-instruct (https://huggingface.co/ibm-granite/granite-3.3-8b-instruct) to speech on publicly available open source corpora containing audio inputs and text targets.
|
| 15 |
|
| 16 |
+
Compared to the initial release, revision 3.3.1 has improvements in model performance stemming from two key changes:
|
| 17 |
+
* Training on additional data
|
| 18 |
+
* A deeper acoustic encoder for improved transcription accuracy
|
| 19 |
+
|
| 20 |
We are currently investigating an issue with greedy decoding (```num_beams=1```); the model performs reliably with beam sizes > 1, which we recommend for all use cases.
|
| 21 |
Additionally, the model may occasionally hallucinate on very short audio inputs (<0.1s). These issues are under active investigation, and we will update guidance as fixes become available.
|
| 22 |
|
| 23 |
**Evaluations:**
|
| 24 |
|
| 25 |
+
We evaluated granite-speech-3.3-8b revision 3.3.1 alongside other speech-language models (SLMs) in the less than 8b parameter range as well as dedicated ASR and AST systems on standard benchmarks. The evaluation spanned multiple public benchmarks, with particular emphasis on English ASR tasks while also including AST for En-X translation.
|
| 26 |
|
| 27 |
+
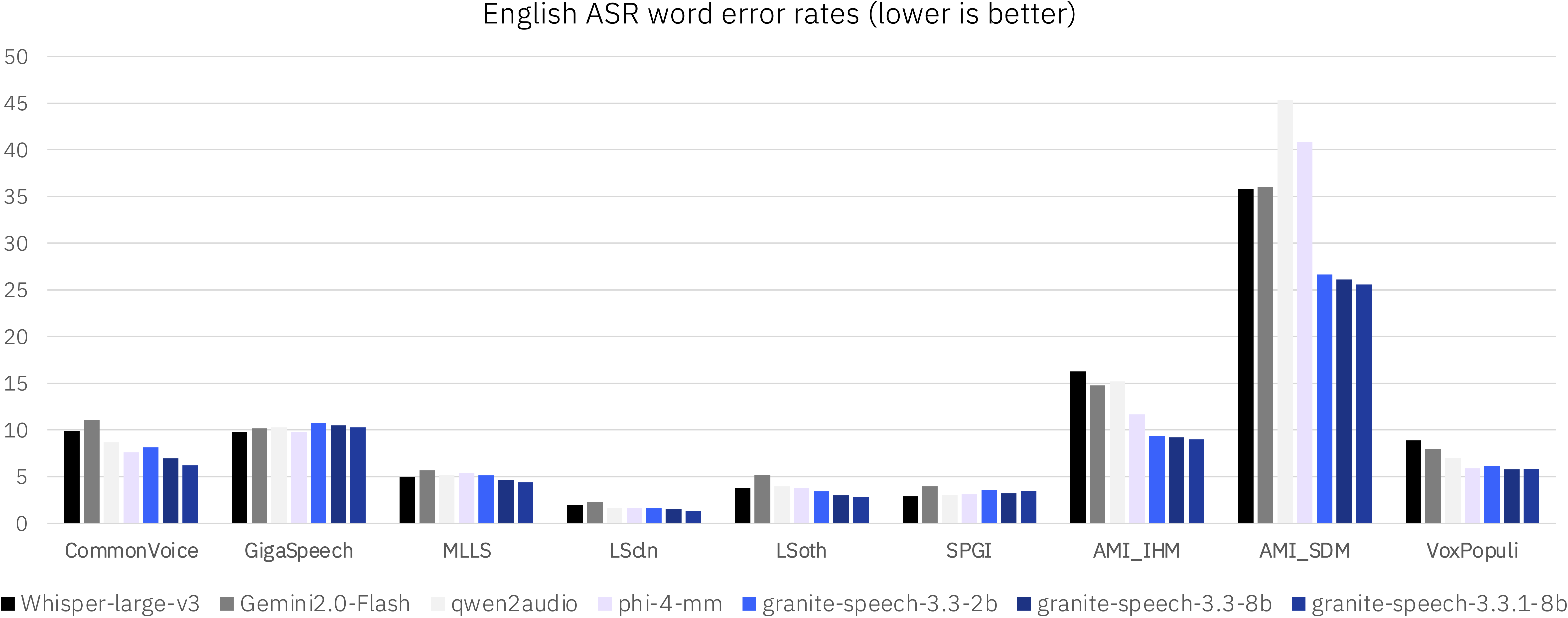
|
| 28 |
|
| 29 |
+

|
| 30 |
|
| 31 |
+

|
| 32 |
|
| 33 |
**Release Date**: April 15, 2025
|
| 34 |
|
|
|
|
| 43 |
|
| 44 |
## Generation:
|
| 45 |
|
| 46 |
+
Granite Speech model is supported natively in `transformers` from the `main` branch. Below is a simple example of how to use the `granite-speech-3.3-8b` revision 3.3.1 model.
|
| 47 |
|
| 48 |
### Usage with `transformers`
|
| 49 |
|
|
|
|
| 307 |
|
| 308 |
The architecture of granite-speech-3.3-8b consists of the following components:
|
| 309 |
|
| 310 |
+
(1) Speech encoder: 16 conformer blocks trained with Connectionist Temporal Classification (CTC) on character-level targets on the subset containing
|
| 311 |
only ASR corpora (see configuration below). In addition, our CTC encoder uses block-attention with 4-seconds audio blocks and self-conditioned CTC
|
| 312 |
from the middle layer.
|
| 313 |
|
| 314 |
| Configuration parameter | Value |
|
| 315 |
|-----------------|----------------------|
|
| 316 |
| Input dimension | 160 (80 logmels x 2) |
|
| 317 |
+
| Nb. of layers | 16 |
|
| 318 |
| Hidden dimension | 1024 |
|
| 319 |
| Nb. of attention heads | 8 |
|
| 320 |
| Attention head size | 128 |
|
|
|
|
| 344 |
| Librispeech | ASR | 1000 | https://huggingface.co/datasets/openslr/librispeech_asr |
|
| 345 |
| VoxPopuli English | ASR | 500 | https://huggingface.co/datasets/facebook/voxpopuli |
|
| 346 |
| AMI | ASR | 100 | https://huggingface.co/datasets/edinburghcstr/ami |
|
| 347 |
+
| YODAS English | ASR | 10000 | https://huggingface.co/datasets/espnet/yodas |
|
| 348 |
+
| Earnings-22 | ASR | 120 | https://huggingface.co/datasets/distil-whisper/earnings22 |
|
| 349 |
| Switchboard English | ASR | 260 | https://catalog.ldc.upenn.edu/LDC97S62 |
|
| 350 |
| CallHome English | ASR | 18 | https://catalog.ldc.upenn.edu/LDC97T14 |
|
| 351 |
| Fisher | ASR | 2000 | https://catalog.ldc.upenn.edu/LDC2004S13 |
|
|
|
|
| 355 |
|
| 356 |
**Infrastructure:**
|
| 357 |
We train Granite Speech using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable
|
| 358 |
+
and efficient infrastructure for training our models over thousands of GPUs. The training of this particular model was completed in 12 days on 32
|
| 359 |
H100 GPUs.
|
| 360 |
|
| 361 |
**Ethical Considerations and Limitations:**
|
adapter_config.json
CHANGED
|
@@ -20,8 +20,8 @@
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
| 23 |
-
"
|
| 24 |
-
"
|
| 25 |
],
|
| 26 |
"task_type": "CAUSAL_LM",
|
| 27 |
"use_dora": false,
|
|
|
|
| 20 |
"rank_pattern": {},
|
| 21 |
"revision": null,
|
| 22 |
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"v_proj"
|
| 25 |
],
|
| 26 |
"task_type": "CAUSAL_LM",
|
| 27 |
"use_dora": false,
|
adapter_model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 136336192
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dc40f62ec34c6b6d5148187fe9fa2a19ba36243536f78877cf68c61208193613
|
| 3 |
size 136336192
|
config.json
CHANGED
|
@@ -16,14 +16,13 @@
|
|
| 16 |
"max_pos_emb": 512,
|
| 17 |
"model_type": "granite_speech_encoder",
|
| 18 |
"num_heads": 8,
|
| 19 |
-
"num_layers":
|
| 20 |
"output_dim": 42
|
| 21 |
},
|
| 22 |
"has_lora_adapter": true,
|
| 23 |
"initializer_range": 0.02,
|
| 24 |
"model_type": "granite_speech",
|
| 25 |
"projector_config": {
|
| 26 |
-
"_attn_implementation_autoset": true,
|
| 27 |
"attention_probs_dropout_prob": 0.1,
|
| 28 |
"cross_attention_frequency": 1,
|
| 29 |
"encoder_hidden_size": 1024,
|
|
@@ -42,7 +41,7 @@
|
|
| 42 |
"vocab_size": 30522
|
| 43 |
},
|
| 44 |
"text_config": {
|
| 45 |
-
"_name_or_path": "
|
| 46 |
"architectures": [
|
| 47 |
"GraniteForCausalLM"
|
| 48 |
],
|
|
|
|
| 16 |
"max_pos_emb": 512,
|
| 17 |
"model_type": "granite_speech_encoder",
|
| 18 |
"num_heads": 8,
|
| 19 |
+
"num_layers": 16,
|
| 20 |
"output_dim": 42
|
| 21 |
},
|
| 22 |
"has_lora_adapter": true,
|
| 23 |
"initializer_range": 0.02,
|
| 24 |
"model_type": "granite_speech",
|
| 25 |
"projector_config": {
|
|
|
|
| 26 |
"attention_probs_dropout_prob": 0.1,
|
| 27 |
"cross_attention_frequency": 1,
|
| 28 |
"encoder_hidden_size": 1024,
|
|
|
|
| 41 |
"vocab_size": 30522
|
| 42 |
},
|
| 43 |
"text_config": {
|
| 44 |
+
"_name_or_path": "/proj/speech/data/granite-3.3-8b-instruct/r250409a",
|
| 45 |
"architectures": [
|
| 46 |
"GraniteForCausalLM"
|
| 47 |
],
|
model-00009-of-00009.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:77c78d245a3306c5675771e910ec8198d6956a058014fb94d3443be83b4930d3
|
| 3 |
+
size 1353359620
|
model.safetensors.index.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
-
"total_size":
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"encoder.input_linear.bias": "model-00009-of-00009.safetensors",
|
|
@@ -71,6 +71,204 @@
|
|
| 71 |
"encoder.layers.1.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 72 |
"encoder.layers.1.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 73 |
"encoder.layers.1.post_norm.weight": "model-00009-of-00009.safetensors",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
"encoder.layers.2.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 75 |
"encoder.layers.2.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 76 |
"encoder.layers.2.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
|
|
|
| 1 |
{
|
| 2 |
"metadata": {
|
| 3 |
+
"total_size": 17296537812
|
| 4 |
},
|
| 5 |
"weight_map": {
|
| 6 |
"encoder.input_linear.bias": "model-00009-of-00009.safetensors",
|
|
|
|
| 71 |
"encoder.layers.1.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 72 |
"encoder.layers.1.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 73 |
"encoder.layers.1.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 74 |
+
"encoder.layers.10.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 75 |
+
"encoder.layers.10.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 76 |
+
"encoder.layers.10.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 77 |
+
"encoder.layers.10.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 78 |
+
"encoder.layers.10.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 79 |
+
"encoder.layers.10.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 80 |
+
"encoder.layers.10.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 81 |
+
"encoder.layers.10.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 82 |
+
"encoder.layers.10.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 83 |
+
"encoder.layers.10.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 84 |
+
"encoder.layers.10.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 85 |
+
"encoder.layers.10.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 86 |
+
"encoder.layers.10.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 87 |
+
"encoder.layers.10.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 88 |
+
"encoder.layers.10.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 89 |
+
"encoder.layers.10.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 90 |
+
"encoder.layers.10.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 91 |
+
"encoder.layers.10.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 92 |
+
"encoder.layers.10.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 93 |
+
"encoder.layers.10.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 94 |
+
"encoder.layers.10.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 95 |
+
"encoder.layers.10.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 96 |
+
"encoder.layers.10.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 97 |
+
"encoder.layers.10.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 98 |
+
"encoder.layers.10.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 99 |
+
"encoder.layers.10.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 100 |
+
"encoder.layers.10.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 101 |
+
"encoder.layers.10.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 102 |
+
"encoder.layers.10.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 103 |
+
"encoder.layers.10.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 104 |
+
"encoder.layers.10.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 105 |
+
"encoder.layers.10.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 106 |
+
"encoder.layers.10.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 107 |
+
"encoder.layers.11.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 108 |
+
"encoder.layers.11.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 109 |
+
"encoder.layers.11.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 110 |
+
"encoder.layers.11.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 111 |
+
"encoder.layers.11.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 112 |
+
"encoder.layers.11.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 113 |
+
"encoder.layers.11.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 114 |
+
"encoder.layers.11.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 115 |
+
"encoder.layers.11.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 116 |
+
"encoder.layers.11.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 117 |
+
"encoder.layers.11.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 118 |
+
"encoder.layers.11.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 119 |
+
"encoder.layers.11.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 120 |
+
"encoder.layers.11.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 121 |
+
"encoder.layers.11.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 122 |
+
"encoder.layers.11.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 123 |
+
"encoder.layers.11.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 124 |
+
"encoder.layers.11.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 125 |
+
"encoder.layers.11.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 126 |
+
"encoder.layers.11.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 127 |
+
"encoder.layers.11.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 128 |
+
"encoder.layers.11.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 129 |
+
"encoder.layers.11.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 130 |
+
"encoder.layers.11.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 131 |
+
"encoder.layers.11.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 132 |
+
"encoder.layers.11.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 133 |
+
"encoder.layers.11.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 134 |
+
"encoder.layers.11.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 135 |
+
"encoder.layers.11.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 136 |
+
"encoder.layers.11.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 137 |
+
"encoder.layers.11.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 138 |
+
"encoder.layers.11.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 139 |
+
"encoder.layers.11.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 140 |
+
"encoder.layers.12.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 141 |
+
"encoder.layers.12.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 142 |
+
"encoder.layers.12.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 143 |
+
"encoder.layers.12.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 144 |
+
"encoder.layers.12.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 145 |
+
"encoder.layers.12.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 146 |
+
"encoder.layers.12.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 147 |
+
"encoder.layers.12.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 148 |
+
"encoder.layers.12.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 149 |
+
"encoder.layers.12.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 150 |
+
"encoder.layers.12.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 151 |
+
"encoder.layers.12.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 152 |
+
"encoder.layers.12.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 153 |
+
"encoder.layers.12.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 154 |
+
"encoder.layers.12.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 155 |
+
"encoder.layers.12.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 156 |
+
"encoder.layers.12.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 157 |
+
"encoder.layers.12.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 158 |
+
"encoder.layers.12.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 159 |
+
"encoder.layers.12.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 160 |
+
"encoder.layers.12.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 161 |
+
"encoder.layers.12.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 162 |
+
"encoder.layers.12.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 163 |
+
"encoder.layers.12.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 164 |
+
"encoder.layers.12.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 165 |
+
"encoder.layers.12.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 166 |
+
"encoder.layers.12.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 167 |
+
"encoder.layers.12.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 168 |
+
"encoder.layers.12.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 169 |
+
"encoder.layers.12.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 170 |
+
"encoder.layers.12.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 171 |
+
"encoder.layers.12.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 172 |
+
"encoder.layers.12.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 173 |
+
"encoder.layers.13.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 174 |
+
"encoder.layers.13.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 175 |
+
"encoder.layers.13.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 176 |
+
"encoder.layers.13.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 177 |
+
"encoder.layers.13.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 178 |
+
"encoder.layers.13.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 179 |
+
"encoder.layers.13.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 180 |
+
"encoder.layers.13.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 181 |
+
"encoder.layers.13.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 182 |
+
"encoder.layers.13.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 183 |
+
"encoder.layers.13.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 184 |
+
"encoder.layers.13.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 185 |
+
"encoder.layers.13.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 186 |
+
"encoder.layers.13.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 187 |
+
"encoder.layers.13.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 188 |
+
"encoder.layers.13.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 189 |
+
"encoder.layers.13.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 190 |
+
"encoder.layers.13.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 191 |
+
"encoder.layers.13.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 192 |
+
"encoder.layers.13.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 193 |
+
"encoder.layers.13.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 194 |
+
"encoder.layers.13.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 195 |
+
"encoder.layers.13.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 196 |
+
"encoder.layers.13.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 197 |
+
"encoder.layers.13.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 198 |
+
"encoder.layers.13.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 199 |
+
"encoder.layers.13.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 200 |
+
"encoder.layers.13.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 201 |
+
"encoder.layers.13.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 202 |
+
"encoder.layers.13.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 203 |
+
"encoder.layers.13.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 204 |
+
"encoder.layers.13.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 205 |
+
"encoder.layers.13.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 206 |
+
"encoder.layers.14.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 207 |
+
"encoder.layers.14.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 208 |
+
"encoder.layers.14.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 209 |
+
"encoder.layers.14.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 210 |
+
"encoder.layers.14.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 211 |
+
"encoder.layers.14.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 212 |
+
"encoder.layers.14.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 213 |
+
"encoder.layers.14.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 214 |
+
"encoder.layers.14.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 215 |
+
"encoder.layers.14.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 216 |
+
"encoder.layers.14.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 217 |
+
"encoder.layers.14.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 218 |
+
"encoder.layers.14.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 219 |
+
"encoder.layers.14.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 220 |
+
"encoder.layers.14.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 221 |
+
"encoder.layers.14.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 222 |
+
"encoder.layers.14.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 223 |
+
"encoder.layers.14.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 224 |
+
"encoder.layers.14.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 225 |
+
"encoder.layers.14.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 226 |
+
"encoder.layers.14.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 227 |
+
"encoder.layers.14.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 228 |
+
"encoder.layers.14.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 229 |
+
"encoder.layers.14.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 230 |
+
"encoder.layers.14.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 231 |
+
"encoder.layers.14.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 232 |
+
"encoder.layers.14.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 233 |
+
"encoder.layers.14.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 234 |
+
"encoder.layers.14.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 235 |
+
"encoder.layers.14.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 236 |
+
"encoder.layers.14.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 237 |
+
"encoder.layers.14.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 238 |
+
"encoder.layers.14.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 239 |
+
"encoder.layers.15.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 240 |
+
"encoder.layers.15.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 241 |
+
"encoder.layers.15.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|
| 242 |
+
"encoder.layers.15.attn.to_kv.weight": "model-00009-of-00009.safetensors",
|
| 243 |
+
"encoder.layers.15.attn.to_out.bias": "model-00009-of-00009.safetensors",
|
| 244 |
+
"encoder.layers.15.attn.to_out.weight": "model-00009-of-00009.safetensors",
|
| 245 |
+
"encoder.layers.15.attn.to_q.weight": "model-00009-of-00009.safetensors",
|
| 246 |
+
"encoder.layers.15.conv.batch_norm.bias": "model-00009-of-00009.safetensors",
|
| 247 |
+
"encoder.layers.15.conv.batch_norm.num_batches_tracked": "model-00009-of-00009.safetensors",
|
| 248 |
+
"encoder.layers.15.conv.batch_norm.running_mean": "model-00009-of-00009.safetensors",
|
| 249 |
+
"encoder.layers.15.conv.batch_norm.running_var": "model-00009-of-00009.safetensors",
|
| 250 |
+
"encoder.layers.15.conv.batch_norm.weight": "model-00009-of-00009.safetensors",
|
| 251 |
+
"encoder.layers.15.conv.depth_conv.conv.weight": "model-00009-of-00009.safetensors",
|
| 252 |
+
"encoder.layers.15.conv.down_conv.bias": "model-00009-of-00009.safetensors",
|
| 253 |
+
"encoder.layers.15.conv.down_conv.weight": "model-00009-of-00009.safetensors",
|
| 254 |
+
"encoder.layers.15.conv.norm.bias": "model-00009-of-00009.safetensors",
|
| 255 |
+
"encoder.layers.15.conv.norm.weight": "model-00009-of-00009.safetensors",
|
| 256 |
+
"encoder.layers.15.conv.up_conv.bias": "model-00009-of-00009.safetensors",
|
| 257 |
+
"encoder.layers.15.conv.up_conv.weight": "model-00009-of-00009.safetensors",
|
| 258 |
+
"encoder.layers.15.ff1.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 259 |
+
"encoder.layers.15.ff1.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 260 |
+
"encoder.layers.15.ff1.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 261 |
+
"encoder.layers.15.ff1.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 262 |
+
"encoder.layers.15.ff1.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 263 |
+
"encoder.layers.15.ff1.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 264 |
+
"encoder.layers.15.ff2.down_proj.bias": "model-00009-of-00009.safetensors",
|
| 265 |
+
"encoder.layers.15.ff2.down_proj.weight": "model-00009-of-00009.safetensors",
|
| 266 |
+
"encoder.layers.15.ff2.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 267 |
+
"encoder.layers.15.ff2.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 268 |
+
"encoder.layers.15.ff2.up_proj.bias": "model-00009-of-00009.safetensors",
|
| 269 |
+
"encoder.layers.15.ff2.up_proj.weight": "model-00009-of-00009.safetensors",
|
| 270 |
+
"encoder.layers.15.post_norm.bias": "model-00009-of-00009.safetensors",
|
| 271 |
+
"encoder.layers.15.post_norm.weight": "model-00009-of-00009.safetensors",
|
| 272 |
"encoder.layers.2.attn.pre_norm.bias": "model-00009-of-00009.safetensors",
|
| 273 |
"encoder.layers.2.attn.pre_norm.weight": "model-00009-of-00009.safetensors",
|
| 274 |
"encoder.layers.2.attn.rel_pos_emb.weight": "model-00009-of-00009.safetensors",
|